エネルギー効率やアクセラレータの使用
次の図は、CPUだけでなくGPUなどのアクセラレータを付けたシステム数を示している。2011年頃からNVIDIAのFermi GPUをアクセラレータとして装備するシステムが急増し、アクセラレータ付きがメジャーになるかとも思われたが、現在も150システム程度にとどまっている。
トップレベルのスパコンではアクセラレータを使うものが多いが、プログラミングが特殊であることから、小型のスパコンでは相変わらずCPUオンリーというシステムが多いことがこのような状況になっている原因と思われる。また、中国のインターネットサービスやソフト開発などに使われているスパコンではアクセラレータが不要であることも影響していると思われる。
-
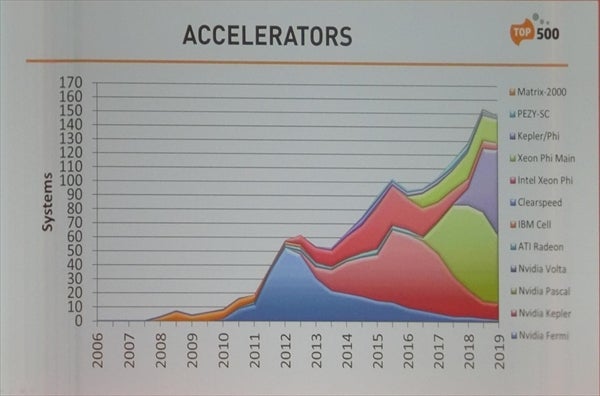
アクセラレータ付きのスパコンの台数推移。Fermi GPUの登場で急増したが、その後の伸びは鈍化し、現在では全体の30%の150システムである

次の図はTop50のスパコンでのアクセラレータの有無と、どのアクセラレータを使っているかを示す円グラフで、過半数がアクセラレータを使っており、アクセラレータを使っていないのは23システムである。使っているシステムでは、NVIDIAのVoltaが9システム、IntelのXeon Phiが8システムとなっている。
-
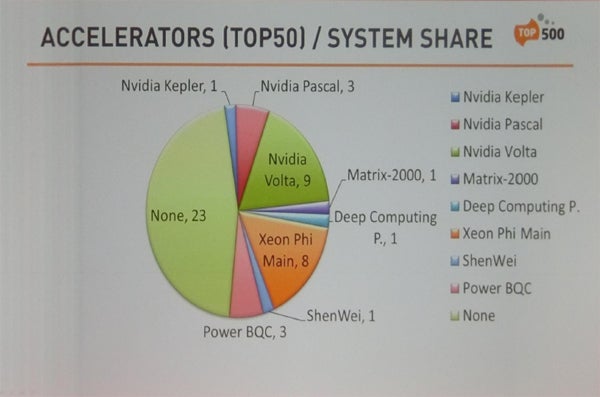
Top50スパコンでは54%と過半数のシステムが何らかのアクセラレータを使っている。NVIDIAのVoltaを使うシステムが9システム、IntelのXeon Phiを使うシステムが8システムとなっている

Green500の指標であるエネルギー効率は、毎回、向上することもあるが、ある高効率のテクノロジができるとそれが2年くらい1位を占めるという傾向になることが多い。現在はExascaler社のZettaScaler-2.2が連続4期トップであるが、歴史をみると、そろそろ新しい1位が出現してきそうな時期になってきているのではないかと思われる。
-
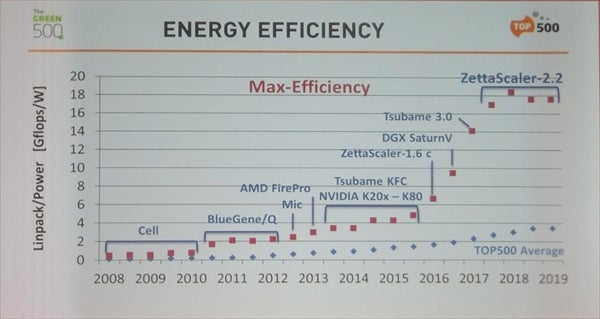
Green500の電力効率の推移。Cellの時代、BG/Qの時代のように、同じテクノロジが2年くらい連続して1位になるという傾向がある。歴史を見ると、そろそろZettaScalerも交代の時期に差し掛かってきている

Top500の今後
Top500の今後について、Erich Strohmaier氏は、ムーアの法則の終焉に伴い色々なアーキテクチャが考案されたり、特定の用途に特化して性能を改善しようとする試みが大幅に増えると予想する。
ISC 2019では、「2029年のHPC、あるいは2020年代のコンピューティングはカンブリア爆発」というパネルディスカッションが行われた。
一方、(現在のHPLのように)どのシステムでもHPLが実行できるということが無くなってしまったら、どのようにしてHPCの性能向上を把握すれば良いのかと問題を投げかけた。
そして、AIだけでなく低精度の演算を使う科学技術計算も出てきており、ISC 2019では低精度計算のBoFが行なわれることもアナウンスされた。
-

ムーアの法則での性能改善が無くなるとアーキテクチャによる改善が必要であり、多様なアーキテクチャが出てくるカンブリア爆発が起こる。しかし、これらマシンの性能測定をどうするかが問題

低精度計算の利用
次の図の横軸は未知数の数で、Ax=bの連立1次方程式を解く場合の計算時間をプロットしたものである。
4つのグラフは上から順にFP64で計算して解く場合、FP32でLU分解を行い、その後FP64で繰り返し誤差を減らす計算を行って、FP64で最初から計算する場合と同じ精度を得る場合の計算時間。その次は、FP16でLU分解を行い、FP64で精度改善を行う場合、一番下はNVIDIAのV100 GPUのTensorコアのFP16演算を使ってLU分解を行いFP64 で精度改善を行う場合の実行時間である。
この図の右端の未知数の数の場合、一番上のHPLで使っているFP64でLU分解を行う場合と比較すると、TensorコアでLU分解して、FP64で繰り返し精度改善を行う方法では、計算時間が1/4になっている。
-
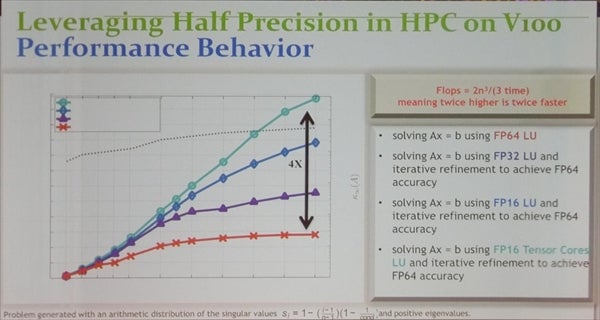
4つのグラフは、上から順に、現在のHPLで使われているFP64でLU分解を行う場合と、LU分解はFP32で行い、FP64で精度改善を行う場合、FP16でLU分解を行いFP64で精度改善を行う場合、V100 GPUのTensorコアでLU分解を行いFP64で精度改善を行う場合の計算時間を示している。図の右端では、一番上と一番下のグラフでは、計算時間が4倍違う

Summitスパコンで4500ノード(各ノードは、Power9 CPU 2個とV100 GPU 6個)を使って、未知数10,091,520の連立1次方程式を解いた。その結果、混合精度の計算では445PFlopsの性能が得られた。これは全部をFP64で計算するTop500の計算(148PFlops)と比較して2.95倍の性能である。
-

Summitスパコンで10M元の連立方程式を解いた。FP64だけでの計算では148PFlopsであるが、混合精度で計算すると445PFlopsと2.95倍の性能が得られた

まとめ
ISC 2019でのTop500のハイライトであるが、今回のリストでは500位のシステムの性能が1PFlopsを超え、ペタフロップススパコンがどこにでもあるという状況になった。
Dennard Scalingの減速は調達サイクルを長くし、最上位のシステムの性能鈍化を2008年から2013年へと5年間遅らせた。
中国はスパコンの生産と消費で世界一になった。しかし、Top50で見ると、まだ、状況は違っている。
色々なアーキテクチャが出てくると予想され、ベンチマークには柔軟性が求められるようになるとStrohmaier氏は結んだ。