ヒルトン東京お台場で開催された、NVIDIAの「GTC Japan 2016」では、Jen-Hsun Huang CEOが登壇したが、その内容は、AI、AI、AIであった。

|
|
GTC Japan 2016で基調講演を行うNVIDIAのJen-Hsun Huang CEO |
筆者の記憶では、Jen-Hsun Huang CEOがGTC Japanで基調講演を行うのは初めてである。ただし、直前にはアムステルダムでのGTCヨーロッパでも基調講演を行っており、日本の地位が急向上したというわけでは無さそうである。
Huang CEOは、NVIDIAはGPUコンピューティングデバイス、ビジュアルコンピューティング、AIのすべてを手掛けており、NVIDIAはAIコンピューティングカンパニーであることをアピールした。

|
|
NVIDIAはGPUコンピューティングデバイス、ビジュアルコンピューティング、AIのすべてカバーするAIコンピューティング会社とアピールするHuang CEO |
この後にも、自動運転など色々なAIの事例やNVIDIAの高性能ディープラーニング用のフレームワークの「TensorRT」などがプレゼンされた。また、FANUCのロボット事業本部長で取締役専務執行役員の稲葉清典氏が登壇して、インテリジェントなロボット工場の開発に関してNVIDIのAIプラットフォームを採用し、技術提携を行うことが発表された。
プレゼンの中で興味深かったのは、AIを使って、ビデオ入力をリアルタイムでピカソ風の絵に変換するというデモである。

|
|
AIを使って、GTC Japan 2016の会場の様子をリアルタイムにピカソ風の絵に変換して見せた |
NVIDIAの新アーキテクチャGPU「Volta」
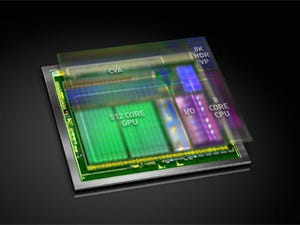
今回の基調講演での新しい発表は、自動運転用の「Xavier」である。しかし、これもヨーロッパのGTCでの発表と同じであり、その意味では新規な技術情報は無かった。XavierはPascalに続く次世代アーキテクチャ「Volta」のGPUを搭載し、Drive PX2の機能を1チップに収めた製品である。16nmプロセスで製造され、70億トランジスタを集積する。そして、8個のカスタムARMコアと512個コアのVolta GPUを集積する。また、新設計のCFA(Computer Vision Accelerator、デュアルの8K HDRビデオプロセサを搭載する。なお、サンプル出荷は2017年第4四半期とのことである。

|
|
16nmプロセスを使い70億トランジスタを集積。8コアのカスタムARMコアと512コアのVolta GPUを搭載 |
512コアで20TOPSのディープラーニング性能と書かれており、1コアあたり約40GOPSという計算になる。INT8演算の性能であるが、クロックを1GHzとすると40GOPS/sとなり、標準の32bit演算を10個並列実行しなければならない。まあ、1.25GHzクロックで8個の並列当たりが妥当なところであろうが、それでも現在のPascalコアの8倍のSIMD演算器が必要である。
これに対して答えは得られなかったが、基調講演で、Pascalより大きなコアという発言があり、Voltaはコアを大きくして、演算の並列度を高めていると思われる。
ディープラーニングの推論と学習
ディープラーニングと言っても、推論(Inference)と学習(Learning)では大きく事情が異なる。推論は多数の入力の積和計算が中心で、32bit浮動小数点(FP32)でなくとも半分の精度のFP16や、最近では8ビット整数でも大丈夫と言われている。
一方、学習は、推論で出した結果と正解の誤差から、誤差が小さくなるように各入力の重みを調整していく。そして、所望の結果が得られるまでこの作業を繰り返す。学習の場合、計算の誤差が大きいと、収束しなかったり、収束に長い時間が掛かったりする。このため、学習にはFP32の精度が必要であり、繰り返しの回数も多いので、何日も掛かることも珍しくない。
GoogleのTPU LSIや、MicrosoftのFPGAを使ったアクセラレータ、NVIDIAのP4 GPUなどは、推論を高速化することができるが、学習には使えない。GoogleやMicrosoftの場合は、学習は1回であるが、膨大なWebユーザが推論を使うので、推論の回数が膨大である。したがって、推論の性能を上げることが重要である。
一方、学習の性能も重要である。しかし、各入力の重みをどれだけ変えるかの計算には、各入力の重みの変更が、全部の誤差にどれだけ影響するかという微分係数を計算し、すべての微分係数を1カ所に集めて計算する必要があり、並列化が難しい。
8ビット整数の演算で推論性能を改善したP4とP40 GPU
NVIDIAのGPUは基本的に32ビットの浮動小数点数を扱う構造となっている。32ビットのレジスタには、8ビットの整数なら4つ(A0、A1、A2、A3)を入れられる。P4とP40 GPUでは、これを利用して、(A0×B0+A1×B1+A2×B2+A3×B3)+C→Dを計算する命令を新設している。FP32の計算は、乗算と加算で2演算であるが、INT8を使うこの命令では8演算を実行できる。したがって、ディープラーニングの推論処理を行う場合は、4倍の演算性能が得られる。
学習に狙いを定めたIBMのMinsky
9月8日にIBMは、「S822LC」と呼ぶサーバを発表した。このサーバは、人工知能の父と呼ばれるMarvin Minsky教授にちなんだ「Minsky」というコードネームで開発されてきたように、AI関係の処理に適した作りになっている。
しかし、NVIDIAのP4とP40が狙う推論ではなく、Minskyは学習に狙いを定めている。Minskyは、2個のPOWER8 CPUに4台のP100 GPUを、高速のNVLINKで接続するという構造になっている。また、POWER8には最大512GBという大容量のメモリを搭載できる。

|
|
IBMのS822LCサーバ。奥の4個の銅色のヒートシンクが付いているのがNVIDIAのP100 GPU。その間の銀色の2個のヒートシンクがPOWER8 CPU |
P100のユニファイドメモリ機能を使えば、GPU側に搭載された16GBのメモリ制約を超えてPOWER8側のメモリをNVLINK経由でGPUから使える。このため、大量のデータを使う学習にも対応できる。
また、NVLINKは高速であるので、4個のGPUに分散された大量の微分係数データを1カ所に集めることも高速にでき、スケーラビリティの高いマルチGPUを使う学習ができる。
さらに、ビッグデータをメモリにおいて高速にデータ処理ができる。

|
|
話を伺ったIBMのHigh Performance Computing & Analytics担当のVPであるSumit Gupta氏 |
IBMのHigh Performance Computing & Analytics担当VPのSumit Gupta氏にビジネス関係の話を伺ったところ、IBMのPOWER8は最強のCPUであるが、Xeonサーバと同程度の価格で販売しているので、ディープラーニングの学習用のサーバとして最適であるとのことである。まだ、発売から1カ月であるのでビジネスが立ち上がるのはこれからであるが、10月4日に、米国のNIMBIXというHPCクラウドを提供する会社がS822LCサーバを採用することを発表したという。