NVIDIA GPUのロードマップ
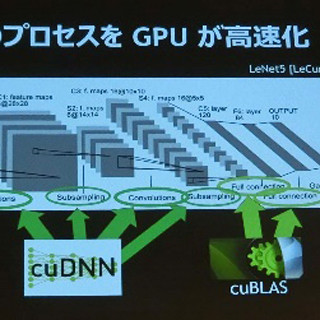
再び、演壇にHamilton氏が戻り、GPUのロードマップについて説明を行った。2015年にはめぼしい新GPUが無いが、2016年には次世代の「Pascal」、2018年には次々世代の「Volta」が出るという計画である。Pascalは、従来の単精度、倍精度に加えて16bit長の半精度の浮動小数点数をサポートする。
ディープラーニングの積和演算は16bit精度で良いとのことであり、半精度のサポートにより、同じ容量のメモリに2倍のデータが格納でき、演算性能も2倍に向上する。

|
|
2016年には次世代のPascal、2018年には次々世代のVoltaが登場するロードマップ |
次世代のPascalでは、倍精度演算性能が世界最高になり、3D積層メモリの搭載でメモリバンド幅が大幅に向上する。また、PCI Express 3.0の5倍のバンド幅を持つNVLinkが装備され、NVIDIAのGPU同士、あるいはGPUとIBMのPower CPUと直結することができるようになる。そして、GPUのデバイスメモリとCPUのメインメモリの相互アクセスの性能が向上し、より一体的なメモリとして使えるようになるという。

|
|
次世代のPascal GPUでは倍精度演算性能が向上して世界一になり、3D積層メモリの搭載で、GPUのメモリバンド幅が大きく改善する。また、GPU同士、あるいはGPUとPower CPUを直結する高速のNVLinkがサポートされる |
そして、最後のゲストである IBMのハイエンドシステム事業部の朝海氏が登壇した。

|
|
登壇してMarc Hamilton氏と握手する日本IBMの朝海孝氏 |
IBMとNVIDIAはハイエンドコンピューティング分野で連携しており、共同で、米国の次期フラグシップスパコンの開発を行っている。Oak Ridge国立研究所に納入されるSummitスパコンとLawrence Livermore国立研究所に納入されるSierraスパコンは、IBMのPower9 CPUとNVIDIAのVolta GPUを使用するシステムとなる。そして、Summitは150~300PFlops、Sierraは100PFlops以上の性能と発表されている。
これらのスパコンの稼働予定は2017年となっており、この点からもVoltaは先のロードマップより1年早く使用できるようにならなければならない。
そして、データ演算よりも、データの転送に必要なエネルギーの方が大きいことから、これらのシステムでは、データの移動を減らす新しい設計思想を取り入れて省電力化を行うとのことである。

|
|
米国の次期フラグシップスパコンであるSummitとSierraは、IBMのPower9 CPUとNVIDIAのVolta GPUを使用する |
そして、IBMは、データを移動するのではなく、データのあるところで処理することを目指すデータセントリックな処理の推進活動を行うセンターを日本に開設するとのことである。