ディープラーニングが何故注目を集めるのか
例えばFacebookには毎日3億5000万枚の画像がアップロードされる。これらを人手で分類することは不可能であろう。また、Walmartの顧客データやYouTubeのデータも膨大で、人手で解析したり、分類したりすることはできない。
しかし、ディープラーニングと呼ばれる新しい手法を使い、そのソフトウェアを高速に実行できるGPUを使うことで、大量のデータのより高度な分析が可能になってきた。
そのため、産業界の多くの分野から、ディープラーニングを使うことで、現在のビジネスを改善したり、新しいビジネス分野に進出したりすることができるのではないかと言う期待が高まっている。これが、今回のGTC Japanに2500人もの参加者が集まった理由であろう。

|
|
Facebook、Walmart、YouTubeなどは、毎日、膨大なデータを集めるが、その分析には新しいアルゴリズムと、それを高速で実行するGPUの計算パワーが必要 |
ディープラーニングは、神経系の情報処理にヒントを得た情報処理系で、大量の入力データを使って学習させることで高い認識率が得られる。計算処理の大部分は積和演算で、これはTop500のLinpackベンチマークで使われる演算と同じで、GPUが得意な計算である。
そして、NVIDIAはディープラーニングに適したGPUというハードウェアを持ち、それにcuDNNなどのディープラーニング用のライブラリを載せ、開発システムとしてまとめた「DIGITS DevBox」を販売している。NVIDIAとしてはディープラーニング向けのサーバシステムを販売しているわけではないが、ディープラーニング向けのシステムの多くのコンポーネントを揃えている。
これらのコンポーネントをNVIDIAから買えば、何かビジネスができるシステムになるという訳ではないが、ディープラーニングを始めようという場合、NVIDIAは一番多くのコンポーネントを提供できる会社の1つであることは間違いない。

|
|
NVIDIAはディープラーニングを行うGPU、cuDNNライブラリを揃え、フレームワークを搭載したDIGITS DevBoxを販売しており、ディープラーニングに一番コミットしている大企業である |
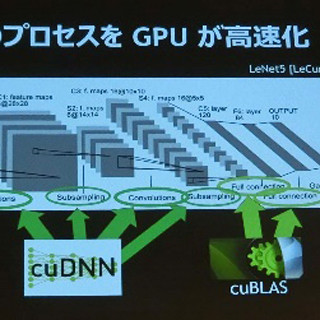
ディープラーニングに向けたNVIDIAの売りの1つが、cuDNNと呼ぶディープラーニング用の基本的な処理を行うライブラリである。ディープラーニングの学習過程では、膨大な数の入力に対するニューラルネットワークの応答を計算し、誤りが少なくなる方向にパラメタを修正して行くという作業を繰り返す。このため膨大な計算が必要となり、学習には何日も掛かるということも珍しくない。従って、計算速度が上がるということは、学習期間の短縮に直結し、非常に重要である。
次の図に示すように、初版のcuDNN 1.0では20万画像/日程度の性能であったが、最新のcuDNN 3.0では70万画像/日と3.5倍程度の性能向上が得られている。この性能向上にはGPUがTitan BlackからTitan Xに変わったことによるハードウェアの性能向上も含まれているが、全体として学習時間が約1/3に短縮できることになる。

|
|
cuDNNはニューラルネットワークの基本的な計算処理を行うライブラリであり、NVIDIAは性能改善を続けている。cuDNN3は初版の約3.5倍の性能になっている |
そして、NVIDIAは、4台のGPUを搭載したDIGITS DevBoxという開発システムを販売している。このシステムには、ディープラーニングに必要なフレームワークと呼ばれるソフトウェアなどが組みこまれており、これを購入すれば、すぐにディープラーニングシステムの開発を始めることができるという。

|
|
NVIDIAはDIGITSというディープラーニングの開発システムを販売している。 |
そして、ディープラーニングに関しては、Preferred Networks社の西川社長が登壇して、同社の開発状況を説明した。同社は東大発のベンチャーで、2006年に設立されたPreferred Infrastructureという会社から、2014年に分離してディープラーニングにフォーカスするPreferred Networksという会社を設立している。

|
|
登壇して自社のディープラーニング関係の開発とChainerについて説明するPreferred Networksの西川徹社長 |
ディープラーニングのシステムの開発にはフレームワークと呼ばれるソフトウェア基盤が使われるのが一般的である。このようなソフトウェア基盤としてはスタンフォード大学の開発したCaffe、モントリオール大学のTheanoなどが使われているが、使いにくい面があるという。そこで、Preferred Networksでは「Chainer」というフレームワークを自社で開発している。
Preferred Networksでは、ビッグデータ、IoTの時代に備えて、分散協調型の強化学習を行うシステムの開発を目指している。ニューラルネットワークの学習には、正解を教える教師付きの学習は学習効率は良いが、膨大な数の入力のそれぞれに正解を用意することは難しいという問題がある。強化学習は、正解を教えてくれる教師はいないが、システムが取ったアクションがどの程度良いかというスコアを教えてくれるフィードバックがあるという学習のやり方である。
2015年3月の米国でのGTCでは、ブロック崩しやインベーダーと言った懐かしのPCゲームの画面を入力として、それぞれの場面で左右への移動やミサイルの発射などの、ディープラーニングシステムが取ったアクションに対してスコアを教えるという方法で、高得点が得られるように学習をさせ、強いシステムを作ることに成功したという事例が報告されている。
Preferred Networksは膨大な数のセンサからのデータをサーバに集めてアクションを決定するというやり方は無理になってくるので、分散協調型のシステムが必要になると考えている。そしてPreferred Networksは、多数のロボットが協調して知識を獲得し、共有するという新しいアプローチを考えている。

|
|
Preferred Networksではビッグデータ、IoT時代に向けた分散協調型強化学習を行うシステムを目指している |
Preferred Networksの目指すシステムでは、IoTデバイスはセンサとして働くだけでなく、協調してうまく働くようなコントロールアクションも行う。

|
|
IoTデバイスはセンシングだけでなく、コントロールアクションも担当する |
そして、このようなシステムを実現するため、既存のディープラーニング用のフレームワークの問題点を解消するChainerと呼ぶ新しいフレームワークを開発している。Chainerでは、さまざまなアーキテクチャのネットワークを記述することができ、Pythonでネットワークを記述するだけで、学習のためにパラメタを修正して行く逆伝搬が行えるコードが生成される。また、CUDAベースでcuDNNに対応しており、実行性能が高い。
Chainerの記述は柔軟性が高く、2014年のILSVRCという画像認識のコンペでチャンピオンとなったGoogLeNetをCaffeで記述するには2058行を必要としているが、Chainerでは僅か167行で記述することができるという。
このような優れた特徴に注目し、NVIDIAはPreferred Networksとの提携を発表している。CaffeやTheanoなどの開発チームとも緊密に連携していると言うが、NVIDIAが正式に提携を発表したのはChainerだけである。

|
なお、Chainerはオープンソースであり、Webサイトから入手することができる。