NVIDIAが主催する「GPU Technology Conference(GTC)」は、昨年と同じSan Jose McEnery Convention Centerで開催された。1400ドルという高額の参加費にもかかわらず4000人以上が参加するという人気のある学会である。昨年と同じ会場であるが、人気セッションは人が集まりすぎて早く行かないと、満員で発表会場に入れないという事態が幾つも起こっており、昨年より参加者が増えている感じである。

|
|
GTC 2015が開催されたSan JoseのMcEnery Convention Center |
Jen-Hsun Huang CEOの基調講演で幕を開けた今年のGTCは、Deep Learning一色であった。Deep Learningは多層のニューラルネットワークを学習させ、画像、スピーチ、テキストなどが認識できるようにする技術を意味する。
Jen-Hsun Huang CEOは、今回のGTCでの主要な発表は、「A New GPU and Deep Learning」、「A Very Fast Box and Deep Learning」、「Roadmap Reveal and Deep Learning」と「Self-Driving Cars and Deep Learning」の4項目であると述べた。多少、こじ付け的なところも有るが、4項目すべてにand Deep Learningが付いている。後で述べるが、Deep Learningの計算処理はGPUに向いており、NVIDIAとしてはDeep Learningがメインストリームになり、それによってGPUの新しいマーケットが生まれることを期待していると思われる。

|
|
GTC 2015での4つの主要な発表は、「A New GPU and Deep Learning」、「A Very Fast Box and Deep Learning」、「Roadmap Reveal and Deep Learning」と「Self-Driving Cars and Deep Learning」であるとJen-Hsun Huang CEOは述べた |
ニューラルネットワークの歴史は古く、1960年代にPerceptronが提案された。しかし、良い結果がでるとブームになるが、結局は、また、すたれてしまうという歴史を繰り返してきた。
Jen-Hsun Huang CEOは、Deep Learningの主要な進歩として、1998年のLeCunのConvolutional Networkと2012年のHintonらの研究を挙げた。

|
|
Deep Learningの歴史上の重要な進歩として1998年のLeCunのConvolutional Networkと2012年のHintonらの業績を挙げた |
ImageNet Large Scale Visual Recognition Challengeというコンペがある。ImageNetは、この写真は何が写っているのかという情報を人間が付加した写真を100万枚以上集めており、毎年、画像の認識率を競うILSVRCというコンペを催している。
このコンペのトップの認識率は2010年に72%、2011年に74%と年率2%程度の改善で推移していたが、2012年にトロント大のHinton教授のグループがDeep Convolutional Networkを使い、学習速度を高める改善を加えたニューラルネットワークを使い、認識率を一気に84%に改善するという成果を挙げた。Jen-Hsun Huang CEOは、これをBig Bangと評価している、

|
|
ILSVRCの結果の年次推移。2010年は72%、2011年は74%であったが、72年にHintonのグループは84%というぶっちぎりの結果を出し、Jen-Hsun Huang CEOはBig Bangと評していた |
このBig Bangを受け継いで進歩が続いており、2014年のILSVRCでは93.37%の認識率に改善され、今年の2月にはMicrosoftとGoogleが相次いで95%という結果を発表し、94.9%という人間の認識率を超えるまでになっている。
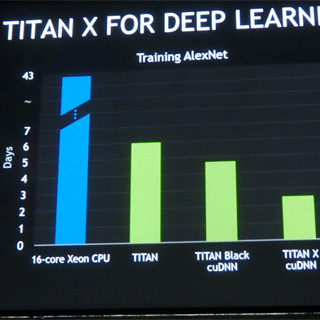
このようなアルゴリズムの改善とGPUを利用した高速実行により、ニューラルネットワークによる認識は実用化に近づいており、NVIDIAとしては今回のブームは本物と考えているようである。

|
|
今年に入り、1月13日にBaiduが5.98%、2月6日にMicrosoftが4.94%、2月11日にGoogleが4.82%の認識ミス率の達成を発表した |
そして、画像認識がどこまで来ているかを示す例として、Stanford大の研究者であるAndrej Karpathy氏とFei Fei Li氏の研究を紹介した。両氏の研究は、写真を認識してそれを説明する記述を付けるというものである。次の中央の写真に対して、「一羽の鳥が木の枝にとまっている」という説明を付けている。

|
|
Stanford大の研究成果。中央の写真に対して「一羽の鳥が木の枝にとまっている」という適切なキャプションを付けている |
次の写真は、帽子しか見えていないが、馬車には男性が乗っていると判断しており、素晴らしい結果である。その次の写真は、a boat isとボートが一艘と間違っているが、街路樹や車などがある状況で、概ね正しい認識ができている。

|

|
|
馬が引く馬車に乗って男の人が通りを進んでいる |
大きなビルを背景にして、運河に一艘のボードが舫ってある |
しかし、そううまく行く例ばかりではなく、次の写真では、飛魚を小さな白い鳥と間違っている。ただし、これは飛魚を学習していなかったからであるかもしれない。その次は、歯ブラシを持っている赤ちゃんを、バットを持つ少年と認識している。少年ではなく幼児であることが認識できず、野球のバットにしてはサイズが小さいことを理解できていないのであるが、これは難しそうである。
最後の写真は橇に乗る二人の男性がバランスを崩したところであるが、一方を少年と判断し、木でできた橇をベンチと誤認識している。地面が雪に覆われていることを認識できていないことが敗因ではないかと思われる。

|

|

|
|
飛魚を小さな白い鳥と述べている |
少年が野球のバットを持っている |
大人の男性と子供がベンチに座っている |
これらの例に見られるように、ニューラルネットワークによる認識は、かなりのところまで来ている。しかし、まだ、状況の総合的な判断という点においては改良が必要なように思われる。