2015年2月20日に大阪で開催されたPCクラスタコンソーシアムの「PCクラスタワークショップ in 大阪2015」において、Intelの根岸史季氏が、次世代スパコン向けの重要コンポーネントである「Knights Landing」と「Omi Path」について発表を行った。

|
|
Intelのスパコン構成要素について発表するIntelの根岸史季氏 |
次世代のXeon PhiであるKnights Landing(以下KNL)は3TFlops以上の演算能力を持ち、メモリとしてはMicronとの共同開発の積層メモリを同一パッケージに搭載する。このメモリはDDR4と比較すると5倍のメモリバンド幅を持ち、5倍の電力効率であるという。そして、最初の製品ではこのメモリの容量は16GBである。これはGPUのデバイスメモリと同程度であるが、KNLはDDR4 DRAMを接続するインタフェースを持ち、バンド幅は制約されるが、Xeon並のメモリ容量を持たせることができるようになっている。
また、KNLは、チップ間のインタコネクトであるOmni Pathのネットワークインタフェースチップもパッケージ内に搭載する。
登場時期に関しては、2015年後半に最初の商用システムと書かれているが、根岸氏の説明によると、この表現は1個でも商用に出荷されれば良いという書き方で、実質的な出荷開始は2016年の早い時期になるとのことである。

|
|
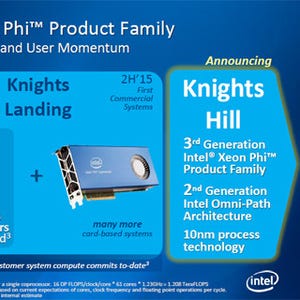
Knights Landingは3TFlops以上の性能で2015年の後半に登場。Micronとの共同開発の3D積層DRAMをパッケージに搭載し、DDR4の5倍のバンド幅と5倍のエネルギー効率を実現。そして、パッケージ内にOmni Pathのインタフェースチップを内蔵する |
そして、次々世代の「Knights Hill」の載ったロードマップを示したが、10nmプロセスで作られ、第2世代のOmni Pathを搭載するという従来から発表されている以上の情報は無かった。
KNLはXeonと命令互換であるので、Xeon用のコードがそのまま動くが、性能を出すためには並列処理のアルゴリズムにコードを書き直す必要がある。このため、Xeon Phiの採用をためらう向きもあるが、NERSCのスパコンでの調査では、使用頻度の高い10本のコードを使う時間が全体の50%、上位25本のコードでは66%の使用時間となっていた。つまり、これらの10本とか25本という程度のコードを並列アルゴリズムに書き換えれば大きな高速化が得られ、書き変えの手間は思ったほど大きくないという。

|
|
KNLはXeonと命令互換であるので、Xeonのコードがそのままで動くが、並列アルゴリズムに書き直さないと性能は出ない。全部書き直すのは大変であるが、NERSCの調査では、使用頻度の高い10コードで50%の使用時間、25コードでは66%を占めており、これらのコードの並列化で大きな効果が得られる |
現在のスパコンでは、インタコネクトとしてInfiniBandが広く用いられているが、Intelは、独自開発のOmni Pathというインタコネクトを推進している。Omni Pathの方がスケーラビリティが高く、対応するプログラミングモデルも豊富、構成の自由度が高いという。
KNLからOmni Pathが採用され、登場時期は2015年後半と書かれているが、前述の根岸氏の説明では、実質は2016年ということになりそうである。

|
|
IntelのOmni Pathは最高のスケーラビリティを持ち、各種のプログラミングモデルや構成に対応している |
Intelは「Storm Lake Gen 1」というコードネームでOmni Pathのインタフェース用のHost Fabric Interface(HFI)チップとスイッチチップを開発する。HFIチップはKNLのパッケージに組み込んだり、PCI Express接続のNetwork Interface Cardなどに使われ、スイッチチップはエッジスイッチやスパインスイッチを作るのに使用される。これらのスイッチ製品はIntelが作るとは限らず、他社で製造される場合もあるという。
この第1世代のOmni Pathは1リンクが2×100Gbit/sの伝送速度を持っており、HFIファブリックは50GB/sのバンド幅(2リンクを収容)を持つという。そしてスイッチチップは48ポートで9.6Tb/s、1200GB/sのファブリックバンド幅を持つ。

|
|
Storm Lake Gen1 Host Fabric Interfaceチップと48ポートのStorm Lake Gen1 Switchチップを開発し、KNLのパッケージに入れたり、PCIeボードに載せたりする。スイッチチップを使ってエッジスイッチやスパインスイッチを作るが、これらのスイッチは他社が供給することもあり得る |
他社(Mellanox)のInfiniBandスイッチチップは36ポートであり、48ポートのOmni Pathスイッチは17%から56%少ないチップ数で済み、13%から55%短いレーテンシで接続できる。

|
|
48ポートのスイッチチップを使うOmni Pathは、他社の36ポートスイッチを使うシステムより必要なスイッチ数、通過段数を減らすことができる |
ただし、これは単純なトポロジ上の計算であり、スイッチチップの単価や通過遅延時間が異なれば、どちらが優れているかは変わってくる。一般的には、ポート数の少ないスイッチチップの方が単価は安く、遅延時間も短くしやすいので、この比較だけでOmni Pathが優れているとは結論できないのであるが、Intelとしては次の図を示してOmni Pathは36ポートチップを使うInfiniBandと比較して1.3倍のポート密度を持ち、最大半分のスイッチ数で済み、5ホップで接続できるノード数は2.3倍となると主張している。

|
|
48ポートスイッチを使うので、1.3倍のポート密度であり、システム規模によって最大半分のスイッチ数で済み、5ホップで接続できるノード数は2.3倍になる |
なお、FDR規格のInfiniBandは、x4構成でリンクあたり2×56Gbit/sであるが、2×100Gbit/sとなるEDR規格のサンプルが展示され始めており、Omni PathのGen1が登場する時期には、リンク性能に差はないのではないかと思われる。