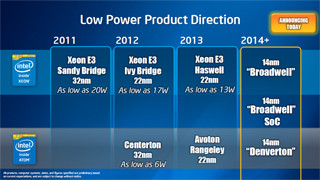
Iris GPUのブロックダイアグラム
GPUはグラフィックスドライバという厚いベールに覆われており、その構造は良く分からないのであるが、今回のIDF13でHaswellのIris GPUのOpenCLサポートが発表され、その内部構造がある程度、分かってきた。
HaswellのIris GPUのブロックダイアグラムは図1のようになっている。なお、この図は昨年のIDFでも発表されており、目新しいものではない。

|
|
図1 HaswellのIris Graphicsのブロック図 |
左側のシェードの掛かっている部分はグラフィックスパイプラインであり、この部分はOpenCLでは使われない。OpenCLの計算処理に使われるのは、この図でSlice0とSlice1と書かれた部分である。
各スライスにはサブスライス0と1が含まれ、その中間のシェードされた箱の中に、L3$が描かれている。この箱の中にはRasterizer/DepthとかPixel Ops、Render$などが描かれているが、これらもグラフィックス用の機能ブロックである。
サブスライスの中には10個のEUとL1IC$(1次命令キャッシュ)が含まれている。その他の部分は主にグラフィックス用のブロックである。
それぞれのEUは、図2に示すように、7つのスレッドを時分割で実行することができる。

|

|
|
図2 EUは7個のスレッドを並列に実行できる |
図3 各スレッドプロセサはSIMD8/16/32で並列演算を行う |
3つのバリエーションがあるSIMDの幅
各スレッドプロセサはSIMDで並列演算を行う。SIMDの幅は8演算、16演算、32演算と3つのバリエーションがある。SIMDのそれぞれのレーンがOpenCLのWork Item(CUDAでいうスレッド)に対応する。Intelの言うDWordは4バイトのことであるので、各スレッドに32バイトのレジスタが128個用意されており、スレッド内のWork Itemで共用することになる。従って、SIMD8の場合は各Work Itemは、より多くのレジスタを使うことができる。

|
|
図4 EUは4並列のALUを2セット持っている |
図4に示すように、SIMD8の時は2クロック、SIMD16の時は4クロック、SIMD32の時は8クロックの時間がかかり、ハードウェアとしては4演算/クロックの積和演算ユニットを同一命令で何クロック続けて動かすかの違いである。
各EUは4並列演算のALUを2組持っており、メインの第1ALUは、浮動小数点演算だけでなく整数演算や各種の演算も実行できるが、第2のALUは浮動小数点演算専用で、演算の種類もadd、mov、mad、mul、cmpに限定される。また、第2ALUへの命令は第1ALUとは別のスレッドの命令でなければならない。
これらをまとめると、次の図5のようになる。2つのスライスには合計40個のEUが含まれ、各EUは7つのスレッドを並列に実行できるので、280 EUスレッドを並列に実行できることになる。各スレッドは最大32レーンのSIMDであるので、最大8960Work Itemを並列に処理できることになる。

|
|
図5 Iris Graphicsの演算性能 |
それぞれのEUは2つの4並列ALUでクロックあたり積と和の2演算を実行でき、Iris Pro 5200のクロックは1.3GHzであるので、ピーク演算性能は832GFlopsとなる。NVIDIAやAMDのハイエンドのディスクリートGPUには遠く及ばないが、CPUチップに搭載するGPUとしては、320積和演算器を1.3GHzで動かすIris Graphicsは、384積和演算器を844MHzで動かすAMDのRichland APUよりピーク演算性能が高い。
図6に示すように、OpenCLのWork Group(CUDAのThread Block)はサブスライスに割り当てられ、各Work Item(CUDAのThread)はSIMDの1つのレーンに割り当てられる。この考え方はNVIDAのGPUやAMDのGCNアーキテクチャのGPUと同じである。ただし、SIMDのレーン数が可変である点は、他社のGPUには無い特徴である。

|

|
|
図6 OpenCLの実行モデル(1) |
図7 OpenCLの実行モデル(2) |
スレッド間の同期をとるバリアハードウェア
また、Iris GPUはスレッド間の同期をとるバリアハードウェアを持っており、同期に参加するスレッドは、処理が終わるとGatewayにメッセージを送り、バリアレジスタの値を+1する。また、各スレッドは、自分の処理が終わっても、バリアレジスタの値が同期するスレッド数に満たない場合は、スリープして他のスレッドの終了を待ち合わせる。この方式の同期機構は京コンピュータのSPARC64 VIIIfxでも使われており、Atomicなメモリアクセス命令を使う方式よりオーバヘッドが小さい。ただし、Iris GPUでは、バリアレジスタの数が16個であるので、これを超えてしまうと、命令の発行が止まってしまう。

|
|
図8 Iris GPUはプレディケートを使ってSIMT実行する |
Iris GPUはレーンごとにプレディケートを持ち、Single Instruction Multiple Thread(SIMT)方式で命令を実行する。そして、1つのSIMDの中でif文の条件が成立するレーンと不成立のレーンがある場合は、赤枠で囲ったように、両方のコードを実行するだけの処理時間が掛かる。ただし、同じif文でもSIMD内のすべてのレーンで成立、不成立が揃っていれば、片方だけを実行するので、ムダは生じない。これもNVIDIAやAMDのGPUと同じである。
そして、Iris GPUはIEEE754規格で規定された演算精度は満足しないが、マイクロソフトのDirectX 10の精度は満たすネーティブの演算関数を用意している。これらの関数は精度は若干劣るものの、ベキ乗やログの計算は、最大では1桁高速に実行できる。

|
|
図9 Iris GPUはIEEE754に準拠しない高速演算関数を持つ |