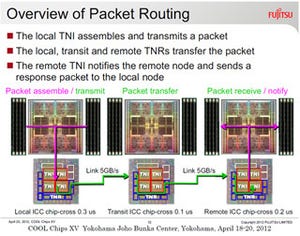
2013年4月17日から19日に横浜の情報文化センターで開催された「Cool Chips 16」において、富士通はハイエンドSPARCサーバ用のSPARC64 Xプロセサを発表した。
富士通のSPARC64 Xは2012年8月のHot Chipsで発表され、また、2013年2月のISSCCでも発表があり、今回の発表で明らかになった新規な情報は少なかったが、スーパーコンピュータ(スパコン)系とビジネス系のプロセサの違いとビジネス系のSPARC64 Xの設計思想などが分かり易く説明された。
富士通のSPARC64プロセサには、京スパコンに使われたSPARC64 VIIIfxのようにfxが付くスパコン用の系列と、今回発表のSPARC64 Xのようにfxのつかないビジネス用の2系列のプロセサがある。その点ではSPARC64 XはSPARC64 IXfxの後継ではなく、SPARC64 VII+の後継という位置づけになる。

|
|
SPARC64 Xプロセサについて招待講演を行う富士通の吉田氏 |
スパコン用は1チップが計算ノードとなる作りで、多数のノードをTofuインタコネクトでつないで大規模なスパコンを構成する。一方、ビジネス用は最大64ソケットのメモリ共有システムが作れる構成となっているが、Tofuとの接続ポートは持っていない。
また、スパコンでは1つのスレッドでも演算器をフルに使ってしまうのでマルチスレッドにしてもほとんど性能が上がらない。このため、スパコン用プロセサはマルチスレッドをサポートしていないが、ビジネス用のSPARC64 Xは2スレッドのマルチスレッドをサポートしており、汎用レジスタ(GPR)と浮動小数点レジスタ(FPR)を2組持っているという違いがある。
そして、スパコン用プロセサはHPC-ACEと呼ぶ科学技術計算を高速化するレジスタ拡張や浮動小数点のSIMD演算などの強化が行われているという特徴があったが、SPARC64 Xはビジネス用であるがHPC-ACEをサポートしており、この点ではスパコン用とビジネス用プロセサの差はなくなっている。

|
|
SPARC64 Xのチップ写真と諸元。16コアを搭載し、3.0GHzクロックで動作し、ピーク演算性能は382GFlops、メモリバンド幅は102GB/s (出典:Cool Chips 16での富士通の吉田氏の発表スライド) |
SPARC64 VII+までは、メモリコントローラも集積されていないCPUだけのチップであったが、SPARC64 Xは、8チャネルのDDR3メモリコントローラやPCI Express Gen3ポートを搭載し、4ソケットまではCPUチップを直結するポートも備えた近代的な構成のCPUとなった。
SPARC64 Xは28nm CMOSプロセスで作られ、16コアと24MBのL2キャッシュを集積している。倍精度浮動小数点のピーク演算性能は382GFlops、メモリバンド幅は102GB/sと業界トップレベルの性能を誇る。また、最大構成では64ソケット1024コア、32TBの共通メモリのシステムが作れるハイエンドビジネスサーバ用のプロセサとなっている。このような大規模構成で企業や社会のインフラシステムとして使用されることを想定しているので、ECCや命令のリトライなどRAS機能も充実しており、チップの大部分の箇所でのシングルエラーから回復できる構成となっている。
SPARC64 Xのプロセサコアのブロックダイヤグラムは次の図のようになっている。

|
|
SPARC64 Xのブロックダイヤ。青色以外のブロックがSPARC64 Xで追加された部分(出典:Cool Chips 16での富士通の吉田氏の発表スライド) |
スパコン用はFlops/Wで表される電力当たりの演算性能が重要であり、多少、クロックを下げて演算あたりの電力を減らす設計になっているが、ビジネス用ではシングルスレッドの性能が重要であるので、SPARC64 XではSPARC64 VII+から3段、パイプラインの段数を追加してクロックを3.0GHzまで引き上げている。また、SPARC64 Xではパターンヒストリテーブルの追加により分岐予測の精度を改善してシングルスレッド性能を上げるという改良が行われている。
その結果、次の図に示すように、SPARC64 VII+と比較してシングルスレッド性能は30~40%向上し、チップ全体の性能は約7倍に向上している。また、メモリバンド幅が律速となるStreamでは17倍の性能向上で、メモリまわりの改善が大きいことが分かる。

|
|
SPARC64 Xの性能向上(対SPARC64 VII+)。シングルスレッド性能では30~40%程度の性能向上。チップ全体では7倍程度に性能が向上している(出典: Cool Chips16での富士通の吉田氏の発表スライド) |
SPARC64 Xでは、富士通がSoftware on Chip(SWoC)と呼ぶ10進浮動小数点演算と暗号処理用の新命令のサポートが追加されている。
科学技術計算では、通常、IEEE 754規格の2進の浮動小数点形式のデータで演算を行う。しかし、2進では0.1のような数字は循環小数となり、ぴったりとは表現できず利息の計算などでは切り捨てや切り上げで1円のずれが出る場合がある。また、入出力は人間が見て分かる10進であり、内部が2進であると変換が必要になる。科学技術計算の場合は、内部の演算量が多いので変換のオーバヘッドは無視できるが、演算量の小さいビジネス計算では変換ばかりやっているということになり、効率が悪い。このため、IEEE754-2008規格では10進の浮動小数点形式が規定されることになった。
SPARC64 Xでは、この10進浮動小数点形式と、Oracleのデータベースで使われているNUMBERと呼ぶ可変長の小数点を含む数の演算処理を高速化する機構を搭載している。AES暗号の処理の高速化機構は他社の多くのCPUも持っていて珍しくないが、SPARC64 Xでも暗号機能がサポートされている。そして、10進演算用に18種、暗号処理用に10種の命令を追加している。

|
|
図の中の黄色の部分がSWoC機能を実現する部分。浮動小数点演算部に追加され、これによるプロセサコア面積の増加は2%程度である (出典: Cool Chips16での富士通の吉田氏の発表スライド) |
この図に示すように、10進演算エンジンと暗号化エンジンは浮動小数点演算部の中に追加されており、プロセサコアの2%程度という少ないハードウェアで実現されているという。

|
|
SWoCの追加で10進浮動小数点演算の性能は104倍、AES暗号処理の性能は29倍に向上(出典: Cool Chips16での富士通の吉田氏の発表スライド) |
しかし、NUMBERのベクトル加算を、新命令を使用する場合と使用しない場合で比較すると、使用することにより性能は104倍と大幅に改善しており、非常に効率が良い。また、この処理を行っている期間の消費電力は0.86倍に減少する。実行時間が104分の1で平均電力が0.86倍であるので、処理に必要なエネルギーは120分の1に減少している。
同様に、AES暗号の解号処理は、平均電力は1.04倍と若干増加しているが、処理時間は29分の1となり解号に必要なエネルギーは27分の1に減少している。
ということで、SPARC64 Xで新設されたSWoCは少ないハードウェアの追加で、大幅な性能向上と消費エネルギーの低減を実現する効率の良い機構であると言える。