TPU1はシストリックアレイ構造で計算
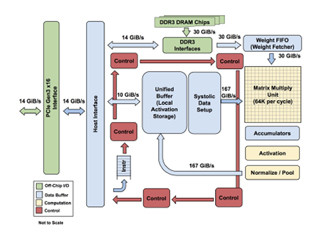
TPU1の行列積ユニットには、次の図のように重みデータを格納して置く。そして、Systolic Data Setupは、一番上の行にはx11、x21、x31、…というデータをFIFOに格納し、2番目の行にはx12、x22、x32、…というデータをFIFOに格納して置く。そして、(1)と表示された最初のサイクルには1行目のFIFOの読出しを開始し、w11を格納した左上の隅の積和演算器だけが計算を行う。
次の(2)サイクルには、1行目の演算器はx11を右隣りの積和演算器にコピーして(2)と書かれた演算を行う。そして、2行目のFIFOの読出しを開始し、2行目の左端の積和演算器で演算を行う。このように、各行の演算開始は1サイクルずつずれて行われるようになっている。
そして、積和演算器はその演算結果を次の行に送り、順に足し込んで下端からは総和が出力されるように接続されている。
このように各積和演算器の入力は最初に格納された重みデータwと左隣から送られて来るxで、結果は次の行の真下の演算器に送るだけであり、配線は短くてすむ。したがって、入力データをレジスタファイルから読み、演算結果をレジスタファイルに書き込むというCPUやGPUの演算方法と比べると計算に必要なエネルギーは少なくて済み、エネルギー効率が高い。
行列積ユニット全体として見ると、動いている部分が左上の隅から開始され、下と右の方に順番に広がっていく。したがって、x入力の最初と最後の方では、一部の演算器しか動いていないという状態になるが、赤字で書かれたように次のxベクタのデータを続けてFIFOを入れて置けば、毎サイクル切れ目なく演算を続けることができ、一般にベクタが長いので演算器の利用効率は高い。

|
|
Systolic Data Setupと行列積ユニットの動作 (この図は筆者が作成したもの) |
ただし、入力xijのj方向は1つのニューロン層の入力の数で決まり、i方向はミニバッチの入力データ数で決まる。そして、j方向の長さが行列積ユニットの256個より長ければ、256個単位でwを入れ替えて処理を行う必要が出てくる。この場合は、重みDRAMからの読出しバンド幅が30GB/sと制限されている点が性能を制約する可能性がある。
TPU1の実装
TPU1は28nm半導体プロセスで作られ、消費電力は最大40Wとなっている。次の図のようなボードに搭載され、サーバのHDD搭載スロットに実装できるようになっている。なお、ボードの上下の辺に搭載されている合計18個の黒いパッケージが重みデータを格納するDDR3 DRAMである。

|
|
GoogleのTPU1のボード(左)とラックに収容されたTPU1を接続したサーバ群(右) |
第2世代のクラウドTPU
そして、Googleは、矢継ぎ早に2017年5月のGoogle IOにおいて、クラウドTPUと呼ぶ第2世代のTPU(ここではTPU2と呼ぶ)を発表した。次の写真に見られるように、サーバのマザーボードサイズのボードに4個のTPU2を搭載している。
TPU2が初代のTPU1と大きく異なるのは、行列積の計算が8bit整数から16bitの半精度浮動小数点演算となった点である。これにより、TPU2は推論だけでなく、学習にも使えるようになった。
TPU2のマイクロアーキテクチャは公表されていないが、ホストCPUとはコプロセサ的な密結合であり、行列積演算ユニットはシストリックアレイ構造であるなどの点は、変わっていたいのではないかと思われる。
この4個のTPU2を搭載したボードの性能は180TeraFlopsと発表されており、1個あたりでは45TeraFlopsである。8bit整数と16bitの半精度浮動小数の違いはあるが、TPU2はTPU1の半分程度の演算性能になっている。
GoogleはTPU2に使っている半導体プロセスについて発表していないが、TPU1の28nmプロセスではなく、16nmプロセスを使っている可能性が高いと思われる。単純に素子密度はこの寸法の2乗に逆比例すると考えると、3倍程度のトランジスタを集積できるが、個々の演算器のサイズが10倍程度となっていると思われるので、チップ面積を1.5倍にして、TPU1の半分の32K演算器とし、クロックは同じ700MHz程度として演算性能が半分程度となったというのが筆者の想像である。
そして、EE Timesによると、TPU2ボード間の接続は2次元トーラスになっているという。高速インタフェース用のQFSPのようなコネクタが、左右の辺に4個ずつ付いており、これで2次元トーラスを構成しているとすると、つじつまが合う。4方向に1本ずつの接続でも良いが、故障を考えて、それぞれの接続を2重化していると思われる。

|
|
2017年のGoogle IOで発表されたTPU2を4個搭載したボード |
このボードを見て気づくのは、TPU1のボード上にあったDRAMが無くなっている点である。このDRAMが30GB/sのバンド幅しかなく、これを3D実装のHBM2などに変更するのが一番大きな性能改善とISCAで発表した論文に書かれており、大きなヒートシンクの下にはTPU2 LSIだけではなく、HBM2のような高バンド幅メモリも搭載したインタポーザが存在していると思われる。
そして、左辺の中央にある2つの幅の広いコネクタが何であるのかは謎である。しかし、次のラックの写真を拡大して注意深く見ると、これらのコネクタからのケーブルは、左右のCPUラックに接続されているように見える。つまり、左右のラックに搭載されているサーバのCPUにTPU2ボードを接続するコネクタではないかと思われる。この接続は、コネクタの形状としてPCI Expressではなく、IntelのOmni-Pathなどの可能性が高いと思われる。
TPU1のTDPは40Wと発表されているが、今年のGoogle IOではTPU2の消費電力は発表されなかった。しかし、TPU2ボードを横から見た写真で見るとTDP 130W程度でも冷やせそうな大きなヒートシンクが付いている。TPU1と比べて半精度浮動小数点演算化でLSIの消費電力も相当増加しており、さらにHBM2のような高バンド幅メモリも搭載されているので、100W超の消費電力となっても不思議ではない。

|
|
TPU2ボードを横から見た図。背の高い大電力用のヒートシンクが取り付けられている |
このTPU2ボードを64枚で、次の図のようなシステムを構成している。中央の2つのラック(Googleはポッドと呼ぶ)には4枚×8段のTPU2ボードが搭載され、その両端にサーバのCPUやストレージを搭載したノードが実装されていると思われる。
1枚のTPU2ボードの性能が180TeraFlopsで、それが64枚使われているので、写真の構成の演算性能は180TeraFlops×64=11.52PetaFlopsということになる。

|
|
64枚のTPU2ボード(全体では256 TPU2 LSI(を2つのラックに収容し、左右にCPUボードのラックを配置したTPU2ベースのシステム |
(次回は6月30日に掲載です)