
こちらの記事でも触れた様に12月14日にCore Ultraが正式発表されたが、もう一つの目玉は開発コード名 Emerald Rapids こと5th Gen Xeon Scalableの発表である。
Emerald Rapidsそのものは以前からその存在が公開されており、今年3月に開催されたDCAI Investor Webinarではサンプルも公開されている(Photo01,02)。9月に行われたIntel Innovationで12月14日の発売を公言していたから、これがきちんと守れた格好だ。
-

Photo01: このサンプルがWorking SampleなのかMechanical Sampleなのかは不明。時期的にはまだMechanical Sampleだった可能性もある。

-

Photo02: ダイが妙にのっぺりしてるあたりはMechanical Sampleなのかもしれない。

ただEmerald Rapidsの構造とか性能などはこれまで一切公開されてこなかった。ということでこの辺りを中心にお届けしたい。
まず基本的な違い(Photo03)から。Sapphire Rapidsでは最大で60コアだったが、Emerald Rapidsでは64コアまで増強された。ただし今回はXeon MAXに相当する、HBM搭載のSKUは現時点ではラインナップされていない。
-

Photo03: 主要な相違点。最大の違いはコア数というよりもLLCの増強かもしれない。「約3倍」はちょっと数字を丸めすぎな気も。

メモリは8chのままだが最大で5600MT/secまで速度が向上した。ただしこれは1DPC(DIMM Per PC)の場合で、2DPCの場合は引き続き4400MT/secに据え置きとなっている(あと2DPCをサポートするSKUはかなり限られる)。そしてLLCだが、Sapphire Rapidsは1.875MB/coreだった。これに対してEmerald Rapidsは5MB/coreまで容量を増やしており、2.67倍の容量向上となっているまたUPI 2.0のLink速度を10GT/secから20GT/secに倍増。それとSapphire Rapidsでは落とされていた(というか技術的には可能ながら未サポートだった)CXL 1.1 Type 3、つまりMemory Expander Deviceを公式にサポートするようになった。
では性能は? ということで示されたのがこちら(Photo04)。特に大きいのは性能そのものよりも性能/消費電力比とかTCOの削減などであるが、これはもう少し後で細かく数字がでている。この性能とか省電力性のもう少し細かい数字こちら(Photo05)。このPhoto05をさらにブレークダウンしたのがこちら(Photo06)となる。
-
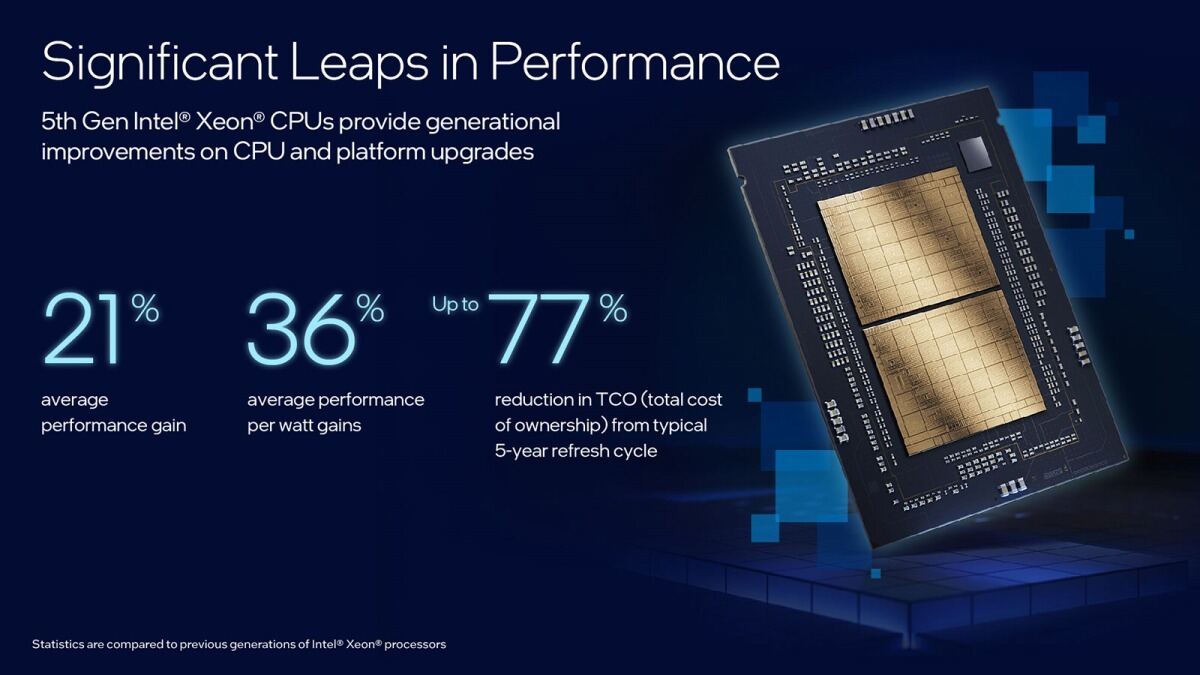
Photo04: コアそのものはSapphire RapidsのGolden Coveから、Raptor Lakeと同じWillow Coveに変更された。これによるIPC向上も若干ながら貢献している。

-

Photo05: 特定のワークロード向けでは20%を超える性能向上があるとしている。

-
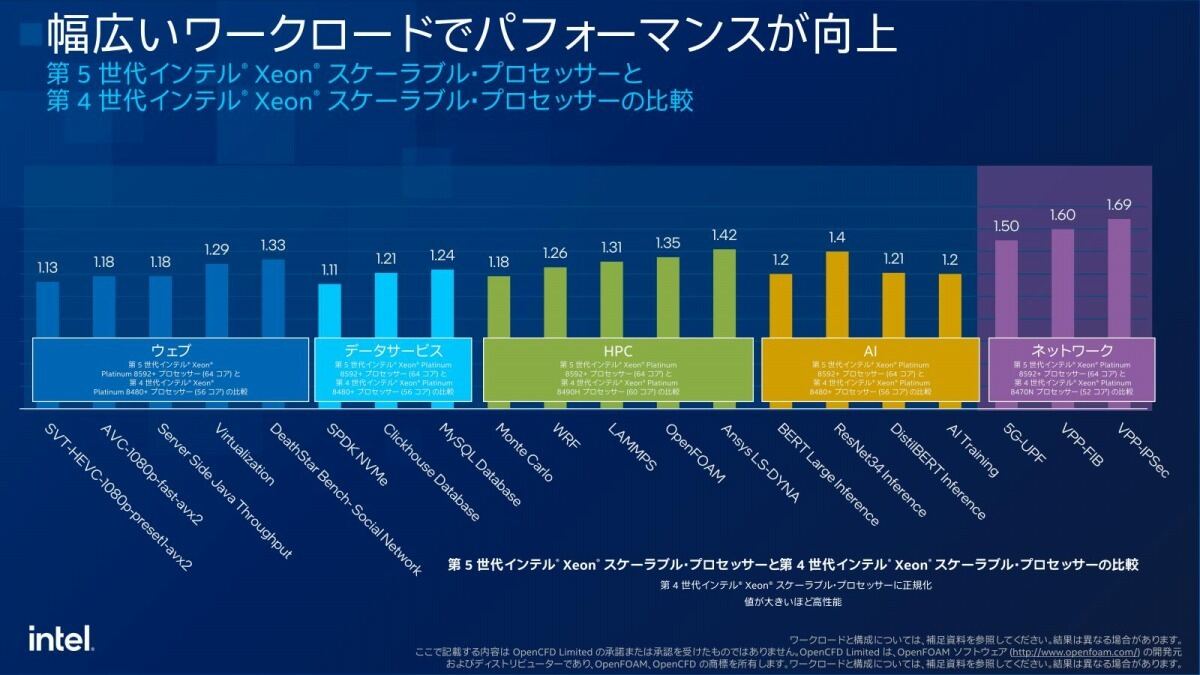
Photo06: Sapphire Rapids比という事を考えると、これはなかなか良い数字である。

ちなみに説明の中ではGenoaベースのEPYC 9554と今回発表のXeon 8592+での性能比較(Photo07)とか、Acceleratorの効果(Photo08)も説明された。ただこのAcceleratorの効果は、Acceleratorを使わない場合との差であって、Sapphire Rapids世代との比較は無しである。恐らくここは世代で大きな差はないだろう。
-
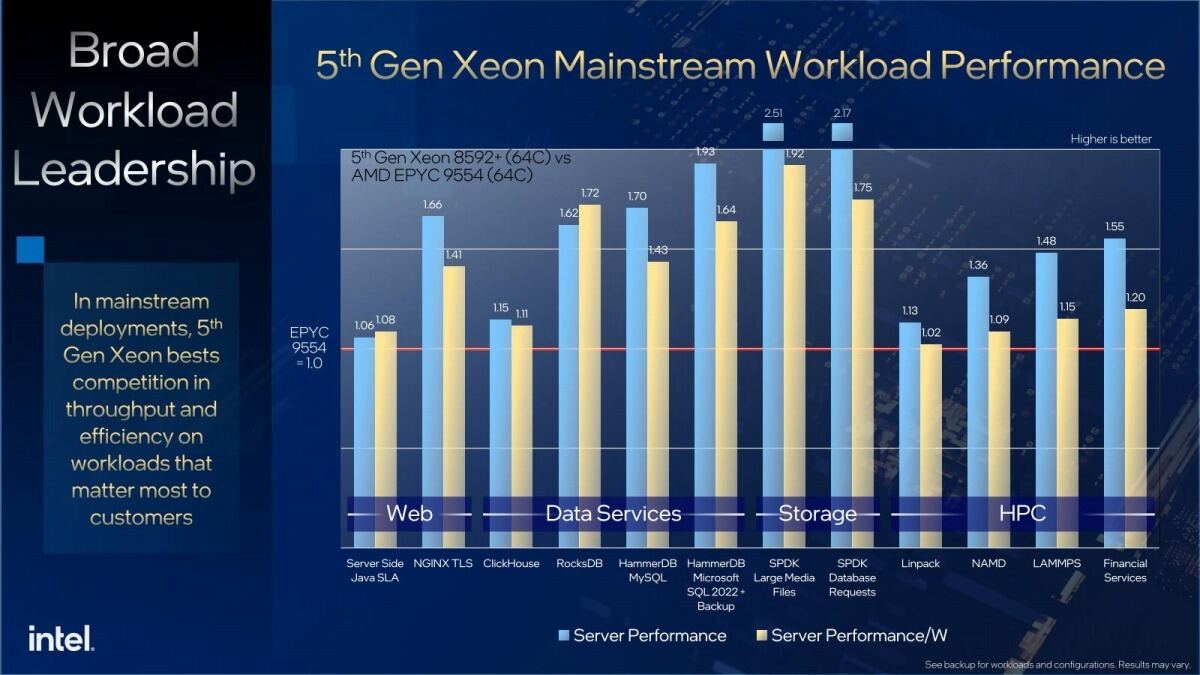
Photo07: 同じ64コア同士での比較となっている。

-
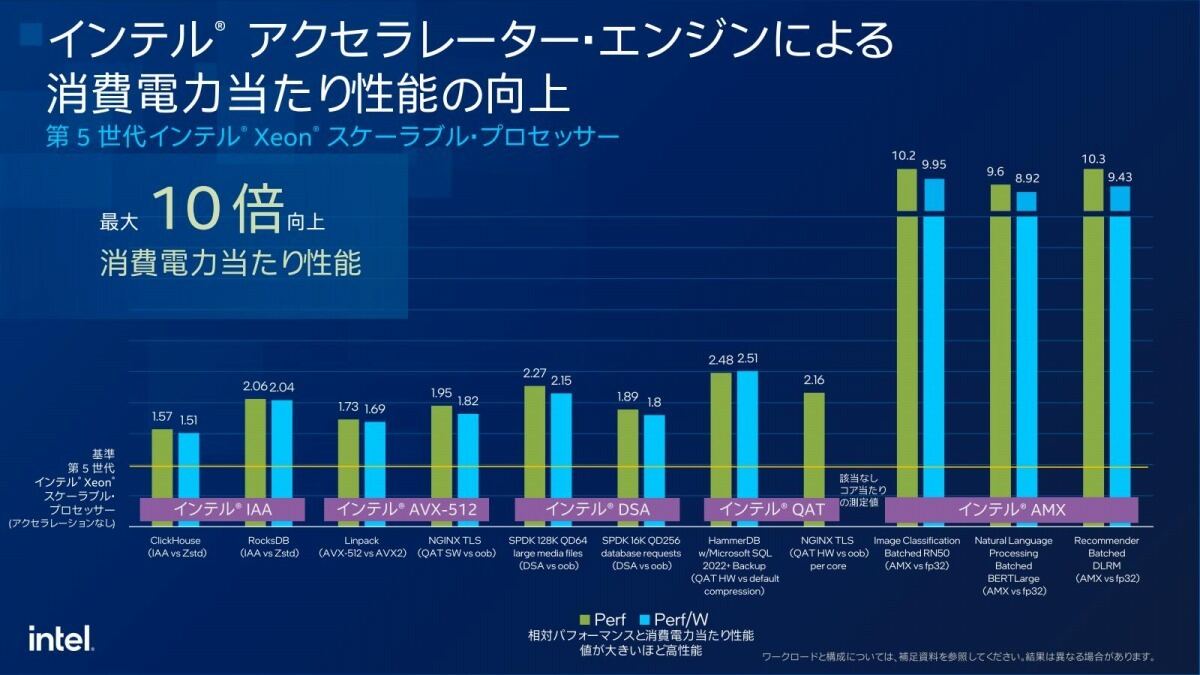
Photo08: これとPhoto07を見比べると、Data ServicesとかStorageの高い性能はプロセッサ単体というよりもAcceleratorを使う事でここまで性能が伸びる、という比較であることが判る。

ところで上で述べた性能/消費電力比の改善であるが、低消費電力時の効率を改善した電源レギュレータや細かな効率向上により、性能/消費電力比を35%改善したとする(Photo09)。またEmerald Rapidsでは新しくOPM(Optimized Power Mode)と呼ばれる動作モードをBIOSレベルで設定可能であり、これを利用した場合に中間負荷における消費電力が大幅に削減できるとされている(Photo10)。消費電力回りで言えば、従来Intelの製品ではSSE/AVXの稼働時に動作周波数を下げるAVX Offsetがあり、Sapphire RapidsではこのAVX Offsetでの動作周波数の下げ幅を緩和するといった形で改良がなされていたが、Emerald RapidsではそもそもOffsetの段階(これをCdyn:dynamic capacitanceとして表記する)を5段階にし、更にClass 0をさらに拡張している(Photo11)。そのまま見比べると3が増えているだけに見えるが、実際にはAMXのUltra-Lightも新たに定義されており、AMXを使いやすくするための工夫が凝らされている事が判る。これにより、一部の処理ではより動作周波数を引き上げやすくなり、5%とか9%といった僅かな数値ではあるものの性能が向上しているという訳だ。
-

Photo09: 待機時の消費電力100W減というのも凄いというか、それだけSapphire Rapidsは無駄に消費電力を費やしていたという事になる訳で、それはそれですさまじい。

-
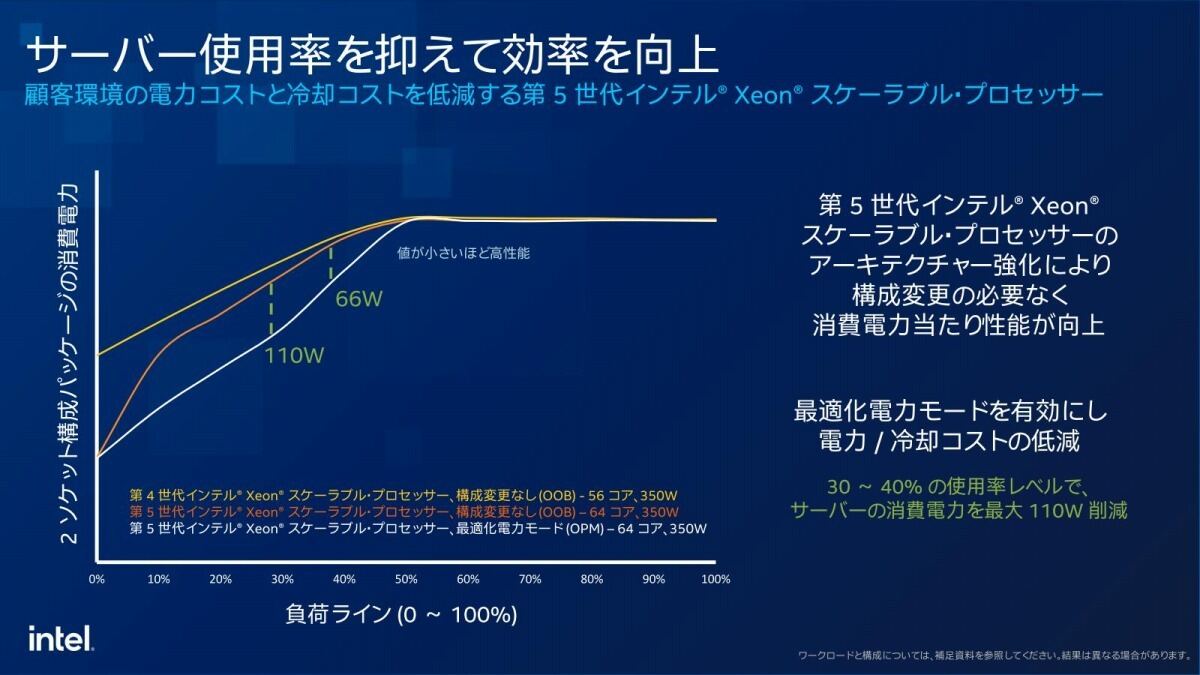
Photo10: ただし絶対的な性能としてはやや下がるので、絶対性能を取るか、性能/消費電力比を取るかという議論になる。この辺は実際のワークロードを実行して判断する事になるのだろう。

-
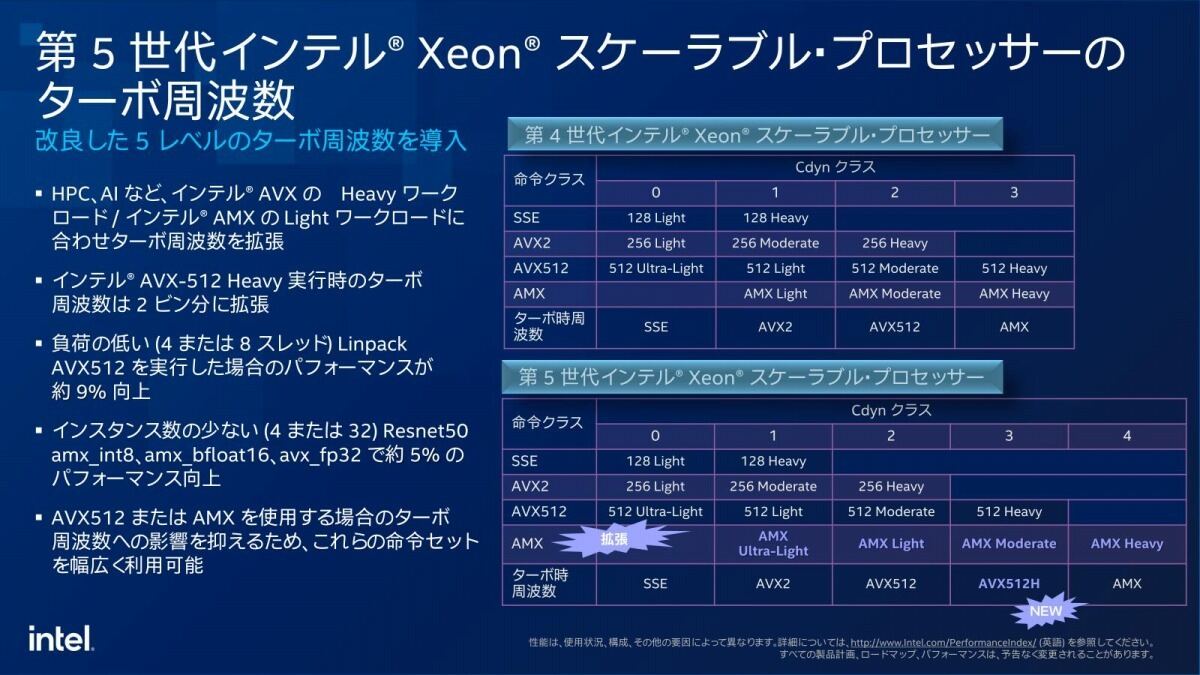
Photo11: Cdynは名前の通りキャパシタのダイナミックな容量である。負荷が高い処理ほど同じ動作周波数でも必要とする電力が増えるため、これを供給するキャパシタの能力が厳しくなる。なのでキャパシタの限界を超えない様に、処理に合わせて動作周波数を抑える必要があり、この処理の重さを示す指標としてCdynが定められている。

このAMXユニット稼働時の動作周波数の最適化やコア数/LLC容量の増強、更により高速なメモリのサポートなどにより、AI WorkloadはSapphire Rapids比で10%~44%の向上を果たした(Photo12)としており、EPYCと比較しても十分に高い性能が期待できる(Photo13)とする。また大規模なLLMでも、すべての処理を100ms以内で実行できるとしている(Photo14)。
-
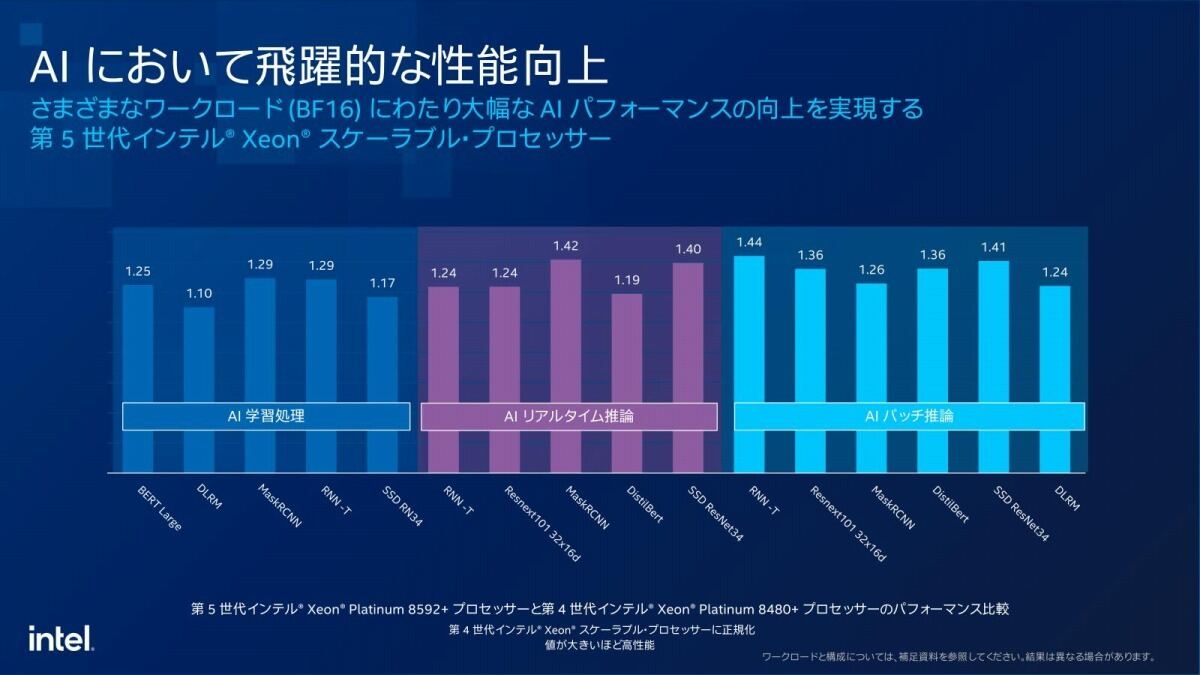
Photo12: この殆どはキャッシュ/メモリアクセス性能の向上と、AMXの動作周波数向上の相乗効果と考えられる。

-
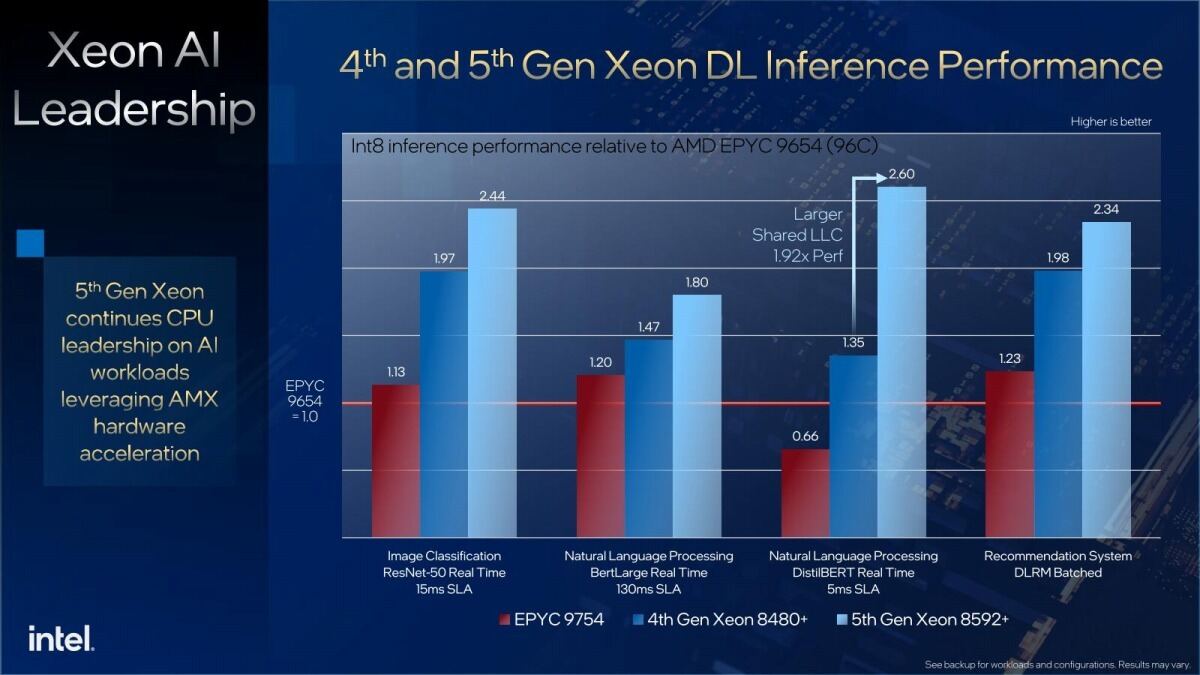
Photo13: もともと現在のEPYCはこうした処理に向いておらず、またAMXも搭載しないから、この性能差そのものは不思議ではない。

-
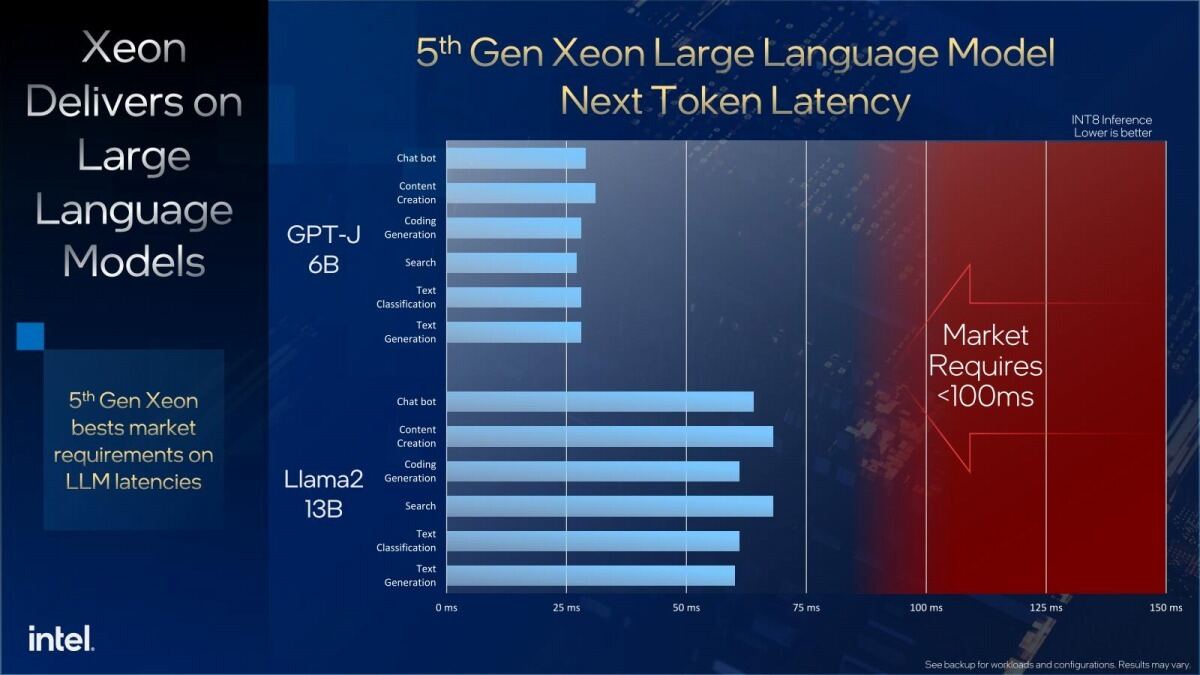
Photo14: 勿論これはInferenceの性能である。60億パラメータのGPT-Jと130億パラメータのLlama2のどちらも、これを利用した際のLatencyが75msec未満だとする。

ところでSapphire Rapidsでは最大32コアのMCCと最大60コアのXCC、それにXCCをベースにHBMを搭載可能にしたHBM(最大56コア)の3つ種類が存在するが、Emerald Rapidsでは20コアまでのEE LCCと32コア以下のMCC、それと2ダイで最大64コアのXCCという形になった。MCCを2つ並べるとXCCという訳ではなく、MCCとXCCは完全に別のダイである。ただSapphire RapidsのXCCの場合、鏡対称に2種類のダイが存在したが、Emerald Rapidsでは同じダイを2つ搭載する格好である。製造プロセスそのものはSapphire Rapidsと同じIntel 7と発表されているが、コアがRaptor Lakeと同じRaptor Coveなあたり、ひょっとするとRaptor Lakeと同じIntel 7+の方かもしれない。
SKU一覧は表の通りである。全製品ともSapphire Rapidsと同じFCLGA4677パッケージで、PCI Express Gen5が最大80レーンとなっている。一部の製品はHigh Priority CoreとLow Priority Coreが判れており、それぞれ動作周波数が異なっている。製品価格は現時点ではまだ公開されていない。
-
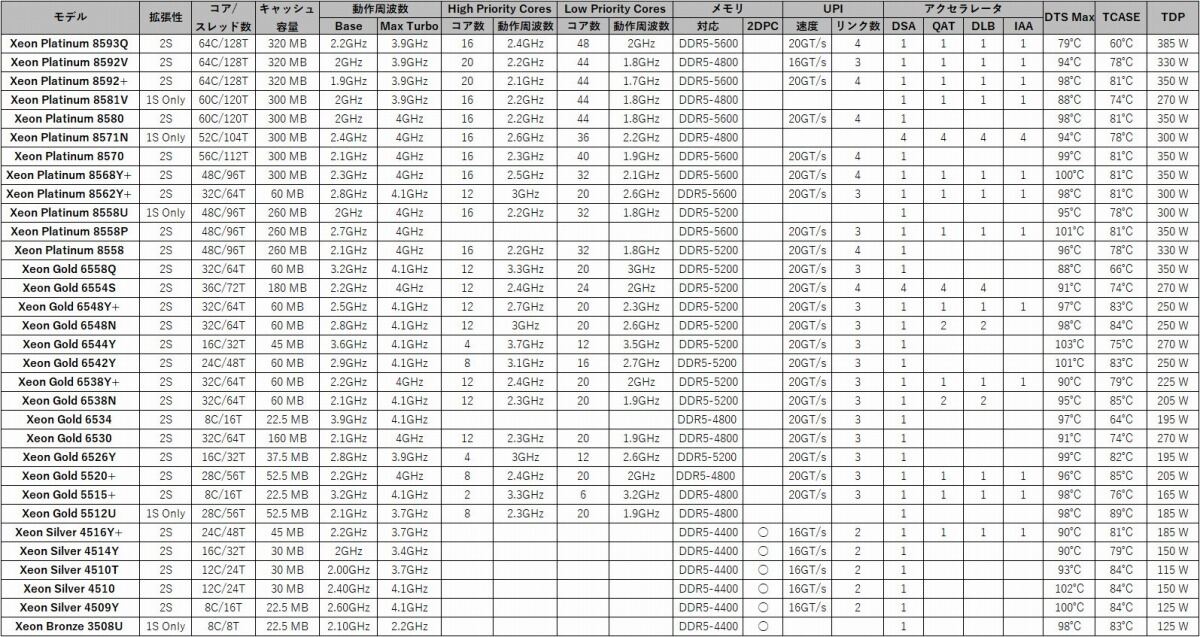
■5th Gen Xeon Scalable(Emerald Rapids) SKU一覧表









