
生成AIって今までのAIと何が違って何ができるの?
生成AIが世間を大きく騒がせています。世間で大きく知られるきっかけとなったのは「OpenAIがChatGPTやGPT-4を発表」に加えて「マイクロソフトがAIを搭載した新しいBing」を発表したことですが、実は「新しいBing」はOpenAIのGPT-4をベースにしたものです。マイクロソフトはOpenAIに投資をしており、マイクロソフトはEdge上のBingのみならず、Office 365やWindowsにも生成AIを組みこむと発表しています。
その生成AIに欠かせないのがGPU。エヌビディア合同会社 テクニカル マーケティング マネージャー 澤井理紀氏が、生成AI開発とその可能性とNVIDIAの役割とテクノロジを紹介しました。説明の前半は、生成AIに至るまでのAI開発の歴史と、ブレークスルーとなったアイディアを説明しました。
-

エヌビディア合同会社 テクニカル マーケティング マネージャー 澤井理紀氏。公式画像なので証明写真みたいなのはご容赦を
-

生成AIのすごいところは(ChatGPTという名前でテキストオンリーと思われがちですが)、GPT-4になり様々な入力、出力が行えるマルチモーダルな点にあります
-

convaiと共に作成した技術デモの一例。SFチックなラーメン屋の主人は状況に合わせた様々な会話を行うので、従来のRPGのNPCとは一味違います……ラーメン注文しろよ!
-

生成AIが市場でもてはやされているポイントは企業の生産性を飛躍的に上げる可能性が高いというところです




かつての機械学習は特定の問題を解決するために多くのデータを使って学習を行い、新たな状況に対して予測を行うものでした。これをさらに人に近づけたのがディープラーニングで、人間の脳と同じようなニューラルネットワークを作り、多くの教師付きデータを学習させることで新たな状況下でも過去の学習からの推測結果を導きます。画像認識で人の認知度を超えたことで注目されました。
-
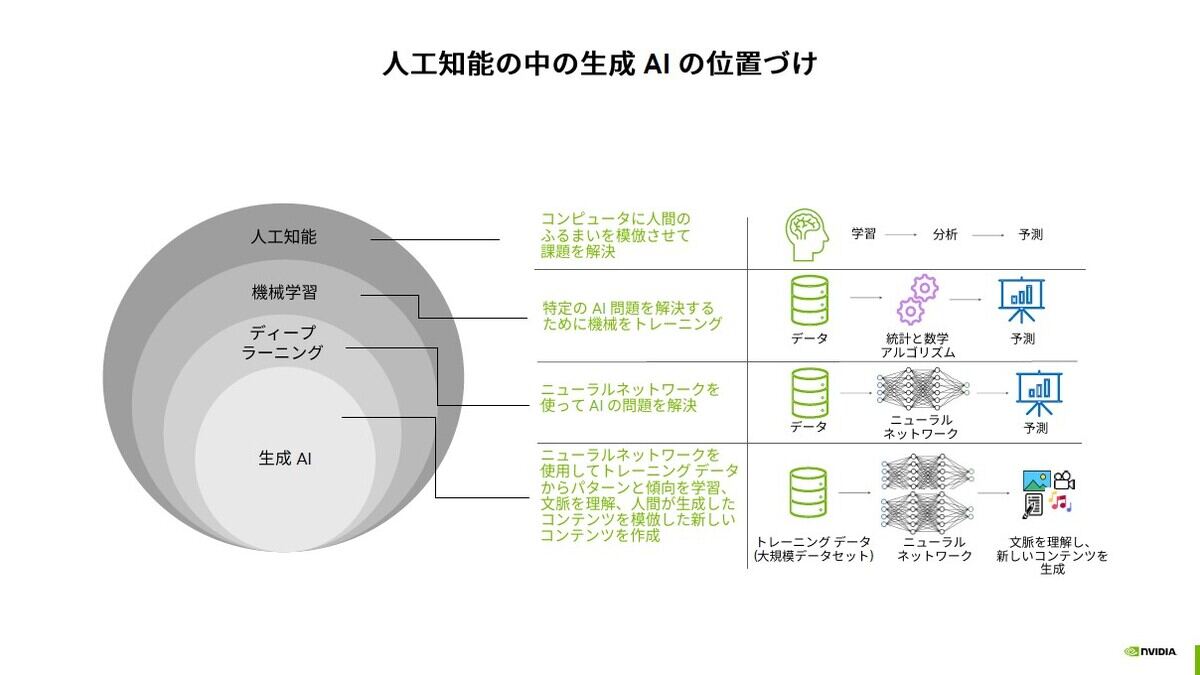
広く人工知能というと何らかの方法で学習し、新たな入力を分析して予測するもの。機械学習は分析に統計的なアルゴリズムを使い、ディープラーニングは分析にニューラルネットワークを使用。生成AIはニューラルネットワークを使うのは同じですが学習データ、パラメーター共に非常に多くなっています

とはいうものの従来は演算能力に限りがある他、教師付きデータを大量に用意するのも難しいのですが、2つのブレークスルーが出ました。
1つは大規模言語モデル(LLM)というもので、文章を複数のトークンに分割してそのつながりを学習するものです。大規模言語というだけあって大量の文章を入力する必要がありますが、インターネット上のように大量の文章がある状況下では、十分な演算能力さえあればさほど難しくはありません。
もう1つがTransfomarという手法で、入力データの重要度を差分的に重みづけするディープラーニングの手法です。並列化が容易で学習させやすいという特徴があります。これらによって生まれたのが生成AIで入力された文脈を理解し、新たなものを生成するのです。
-
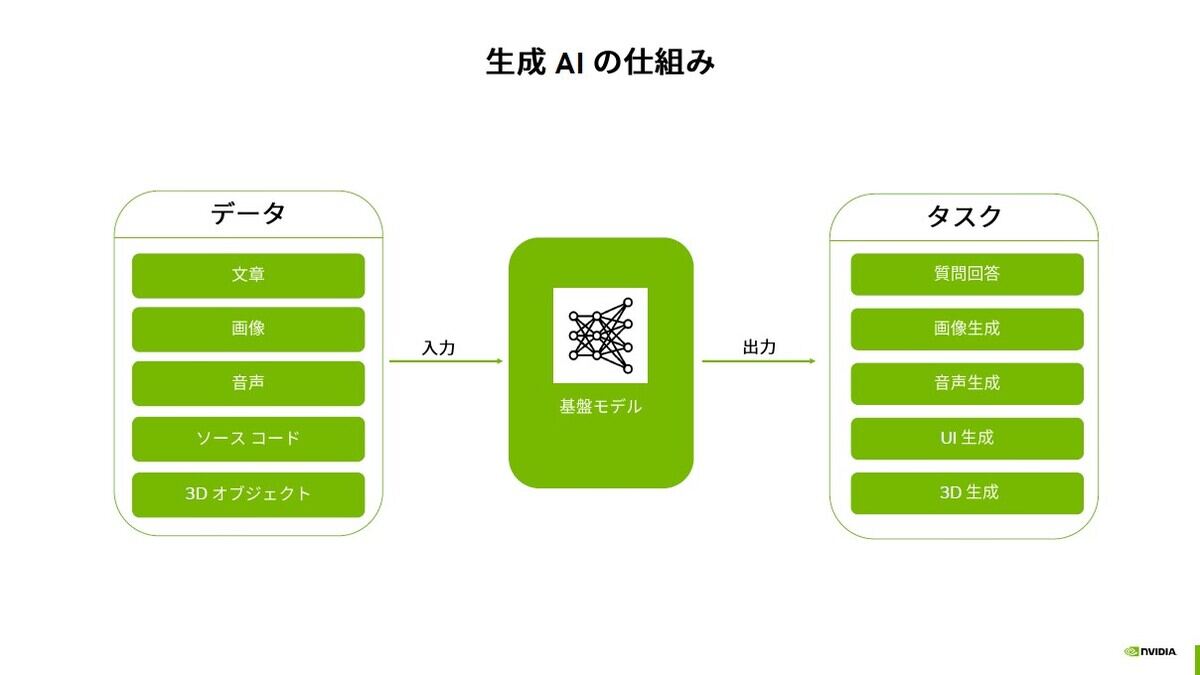
生成AIは事前に膨大なデータを入力して基盤モデルを作成し、これをもとに推論を行います
-

生成AIを語る上で欠かせないのが大規模言語モデル。従来のディープラーニングよりもはるかに多いデータとパラメーターを使い学習させます
-
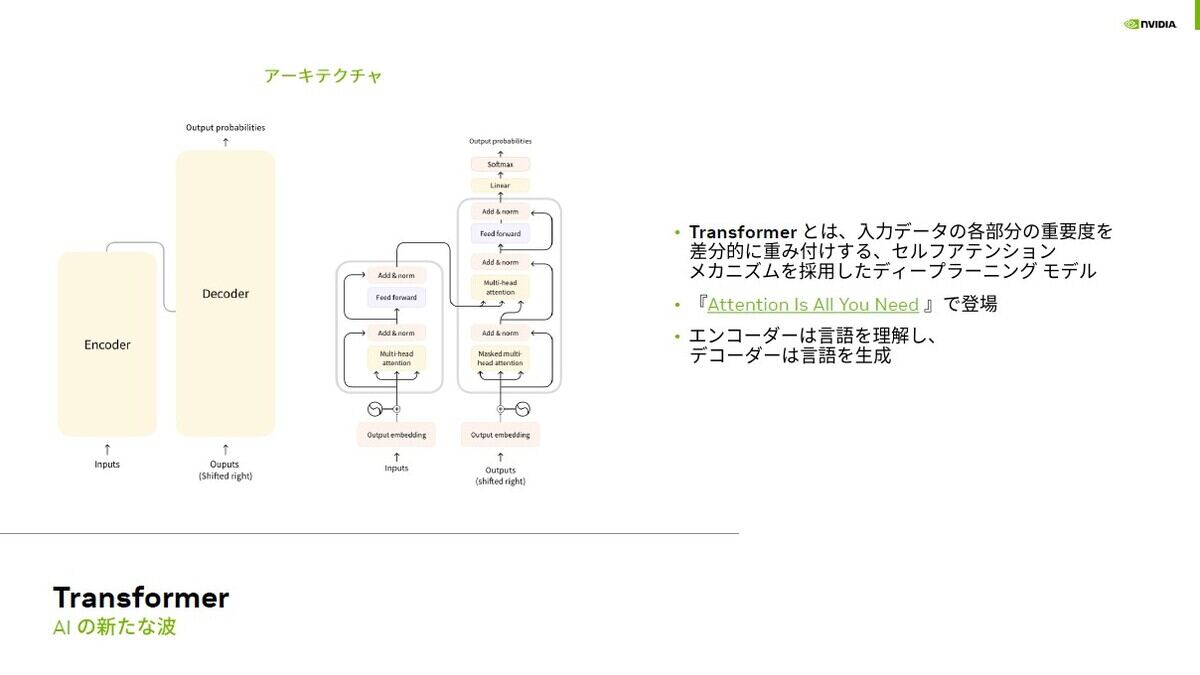
生成AIを語る上でもう一つ重要なのがTransformerと呼ばれる手法。これによって並列処理で効率よく学習を行えます



従来のディープラーニング手法では数億のパラメーターが用意されている一方、入力データにラベル付けが必要でデータセットを用意するのが難しく、作成したモデルも特定のタスクにしか利用できないものでした。
しかし、LLMは数十億~数兆のパラメーター(パラメーターが多ければ多いほど性能が高くなる)一方、データのラベル付けが不要でしかも基礎学習を済ませたモデルは多くのタスクに利用できるという特徴があります。パラメーターが膨大になったために、ChatGPTでは1万個のNVIDIA GPUを数週間使わないと学習できないほどの膨大な計算資源が必要となります。
-
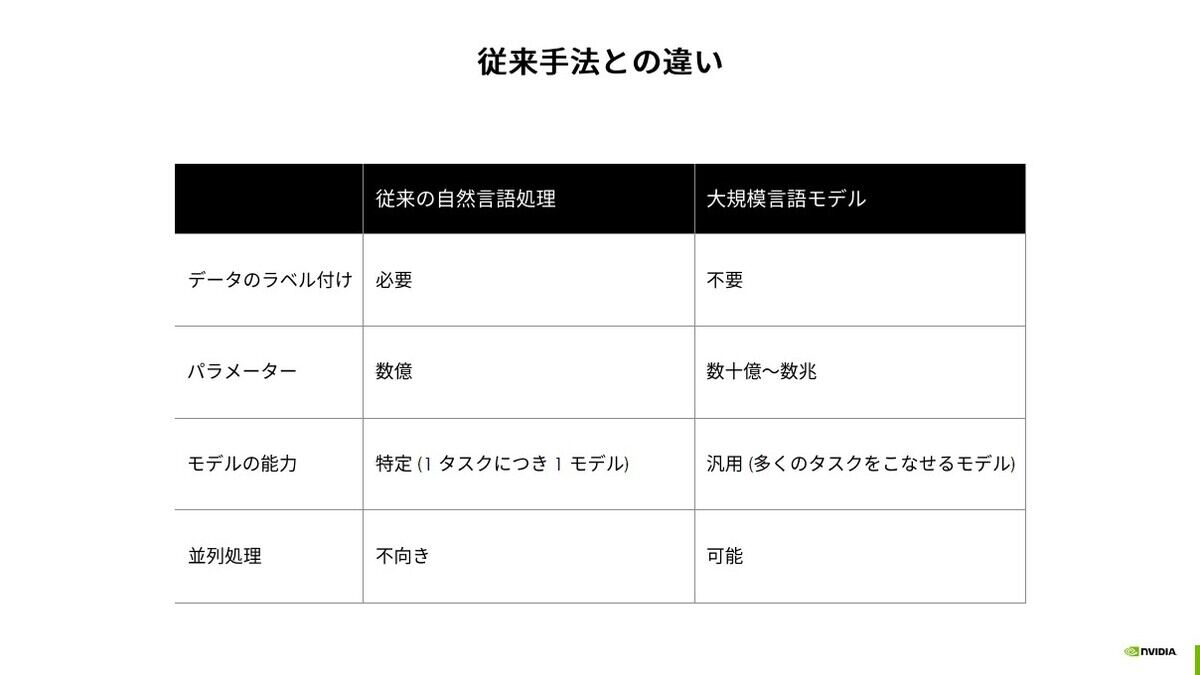
従来の自然言語学習はデータのラベル付けが必要でしたが、大規模言語モデルでは不要です。一方でパラメーターは数桁違う膨大なもの。しかし、並列処理に向いておりかつ基盤モデルを作ることで多くのタスクに応用が効きます

多くのタスクに対応できると言っても、通常のLLMが持っているのは「基礎教養」です。専門性を持たせ、仕事で実用にするためには専門教育というカスタマイズが必要となります。
カスタマイズにはレベルがあり、基本的な生成AIサービスをそのまま、あるいはプラグイン等を付加して利用する手法では最短の時間で利用可能ですが専門性に関しては今一つなのと、推論一回ごとに利用料がかかります。
これに対して、基本トレーニング済の学習モデルをさらに専門教育を施すファインチューニングを行うケースでは開発に数週間~数ヶ月の期間と開発リソースが必要ですが、より高精度な結果を出すことが可能です。
さらにカスタムの基盤モデルを構築したり、広範なファインチューニングを施すケースでは大規模な開発リソースと半年以上の開発期間が必要となりますが、一部報告されている事例では業務効率を大きく改善させることが可能となります。
-

応用が効くと言っても、そのためには追加トレーニングが必要ですが、基盤モデルほどの学習は不要です
-

生成AIを業務に利用するためにはカスタマイズが必要ですが、カスタマイズが多ければ費用と時間がかかるので見極めが必要


発表の中で澤井氏は、金融に特化したBloombergGPT(Bloombergが蓄積した過去の英語の金融文書からの3630億トークンと公開データセット3450億トークンを加えた大規模な学習モデル)を紹介プレスリリース。金融に特化したGPTゆえに、金融のタスクとBloombergのタスクで他のモデルよりも高い性能となっています。
また、カルフォルニア大学Berkley校はAPIコールに特化したGolliraと呼ばれるLLMを追加学習によって作成しました。APIコールに特化した専門教育によって、APIコールに関する質問ならばGPT-4を超える性能になっています。
-

金融とAPIコールに特化したカスタマイズを施した例。BloombergGPTはほぼ一から作った大規模カスタマイズモデルで業務特化型モデル。UC BerkeleyのGorriraはAPIコールの生成に特化したカスタマイズによりGPT-4以上の精度があります

NVIDIAが生成AI構築にサポートできるもの
このように生成AIは従来よりも高い実用性を備えているのですが、生成AIを作るためにはいくつもの課題があります。
基盤モデルから作るためには膨大なトレーニングデータとトレーニングと推論用の大規模な計算資源が必要で、必然的に大規模なインフラ構築に加えて専門知識を持った人材が必要です。
業務特化型に一から作成した基盤モデル以外は企業や専門知識を含みませんし、学習させた段階以降の質問には回答できない、あるいは不確実なものになります(澤井氏は“幻覚”と表現していました)。
-

生成AI開発には膨大なトレーニングデータとそれを処理するための大規模な計算資源が必要ですし、アルゴリズムも複雑で高い専門知識が必要。またこの基盤モデルは作った時点までの知識しか含まれておらず、業務に適した訓練もされていません。さらに間違った結果、不適切な結果を出す可能性もあります

基盤モデルの構築にはNVIDIAが頼りになると澤井氏は主張。実際現在多くのAI学習でNVIDIAのGPUが使われています。
GPUではH100 TensorコアGPUが最新世代です。PCIe接続のボードからこれを8つ組み合わせたHGX H100、ストレージも組み合わせたDGX H100も用意。H100はTransfomerの演算を高速化するために必要に応じてFP8とFP16を切り替える機構が含まれています(ちなみにH100の80GBモデルのボードは、470万円の受注販売。これでも前世代よりもコスパはよくなったとの事)。さらにDGX Cloudを提供。必要に応じて利用できるだけでなくNVIDIAのエキスパートによるサポートも受けられます。
-

NVIDIAは高速なCPU/GPUだけでなく、データのオフロードを行うDPU、ネットワークと言ったハードウェアから、システムソフト、ライブラリとフルスタックで対応
-

NVIDIAのGPU 10000基を数週間使わないとChatGPTのトレーニングが終わらなかったとの事で、とてつもない演算能力が必要なことがわかります
-

そのGPUの最新製品がH100 Tensorコア。PCIe接続の一般的なボードから、複数まとめたHGX H100、ストレージも含めたDGX H100、これをまとめたDGX SuperPODとラインアップは豊富
-

オンプレミスで製品を買わなくてもCloudで利用可能。NVIDIAのAIエキスパートサービスも含んでいます




ちなみに、GPUの性能向上はムーアの法則を超えるレベルで行われています。結果として前世代のHGX A100が320基と同等の性能をHGX H100 64基で実現しており、保有コストは1/3、エネルギー効率は3.5倍になっているそう。
次の製品として、H100 GPUにGrace CPUを搭載したGH200 Grace Hopper Superchipを紹介。PCIe Gen5の7倍の速度を持つNVlink-C2CでCPUとGPUを接続するほか、NVlinkで階層的に接続することで最大256台のGH200を繋いだDGX GH200を年末に提供を開始。256基のGrace Hopper Superchipで合計144TBの高速メモリを備えているだけでなく、ソフトウェアからは1つの巨大GPUとメモリプールとして扱えると紹介していました。
-

日本国内での主なH100の導入事例。来春稼働予定の東工大TSUBAME 4.0はNVIDIA H100 TensorコアGPUを960台搭載予定です
-

H100は前世代のA100よりも5倍の性能で同等のAIパフォーマンスならコストは1/3(って事はボードコストは1.67倍)、エネルギー効率は3.5倍。一方、それだけの演算能力があればさらなるパラメーター数のモデル構築も行えることに
-
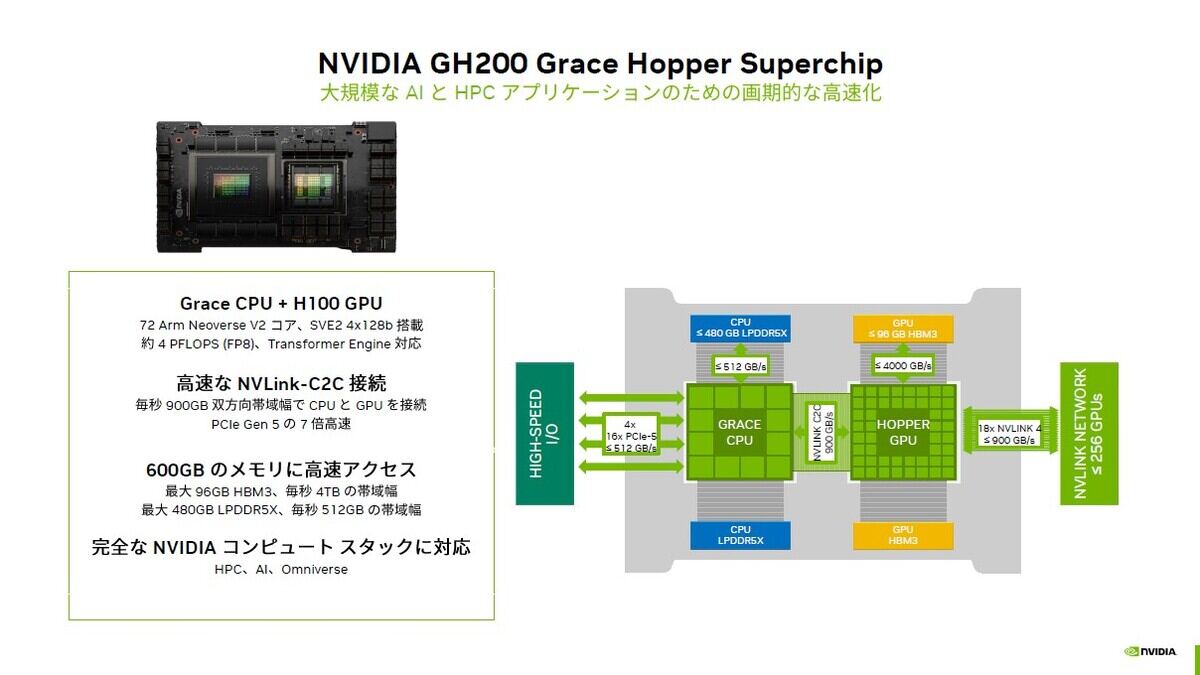
次の製品もすでにCOMPUTEX 2023で発表。ArmコアのCPUとH100 GPUを一つのボードにまとめたGH200は高速なインターコネクトとボード当たり600GBのメモリを搭載
-

さらにGH200は最大256基をスイッチで仮想的にまとめることができ、DGX GH200はAI時代のスーパーコンピューターに。ソフトからは一つのGPUとして扱えます




学習と比較して少ないリソースで済む推論用環境でのGPUも豊富に用意。最上位には先に紹介しているGH200やH100 NVL(二基のH100をNVlinkで接続したもの)やL4/L40が紹介されていました。L40は前世代よりも10倍高速になっています。
-

学習だけでなく、利用のための推論用GPUも多数用意

ハードウェアだけにとどまらず、ツール類やライブラリに加え、生成AIのファインチューニングに関してはNeMoプラットフォームを提供。これによって企業・ドメイン特化のためのチューニングをサポートし、加えて企業利用に欠かせない「ガードレール」により幻覚や不適切な情報(脱獄や悪意のあるコード等)を出力しないようにします。
-
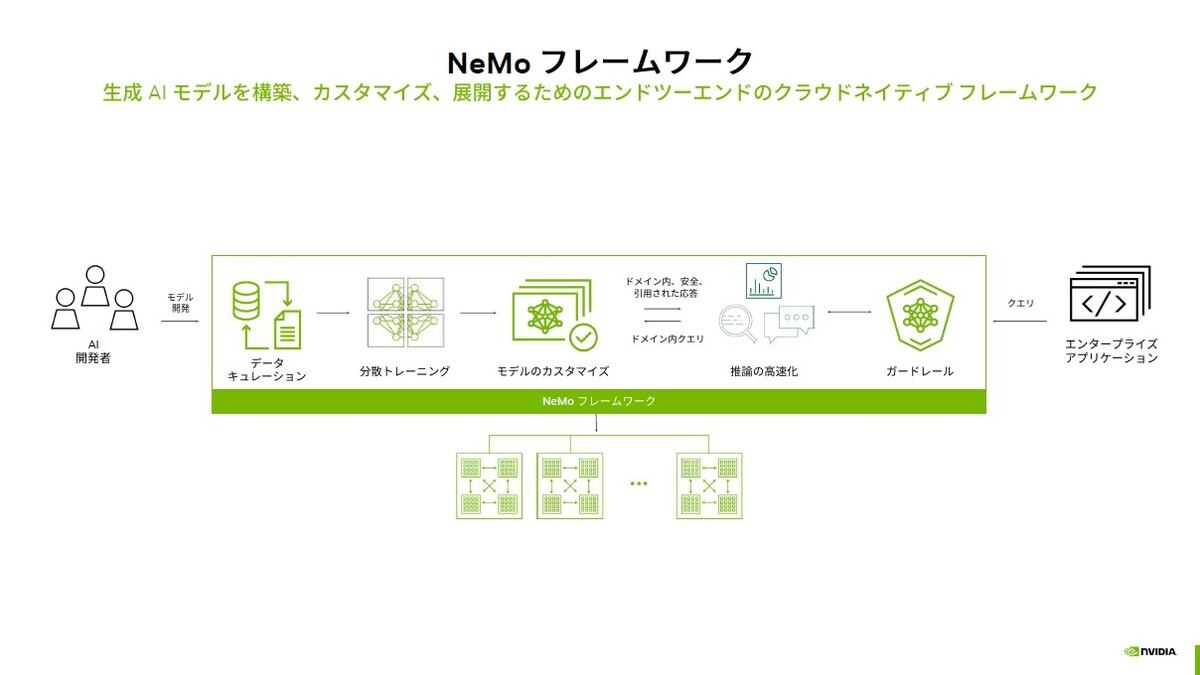
基盤モデルのカスタマイズにはNeMoフレームワークを用意
-
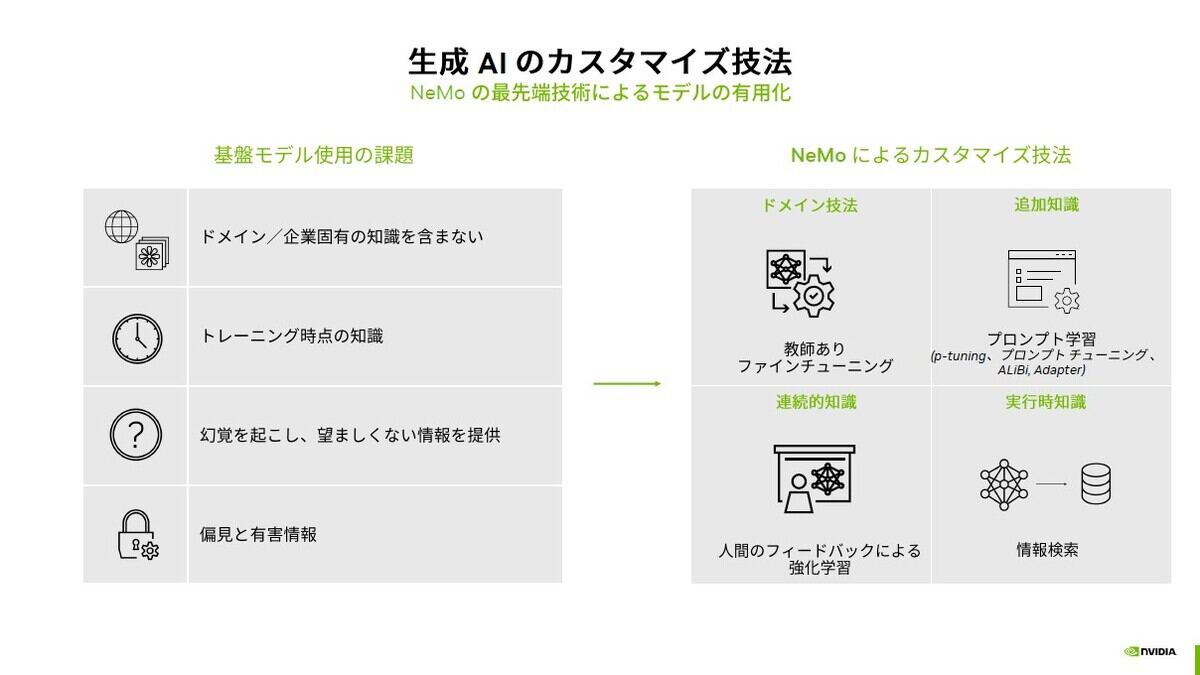
NeMoフレームワークを使用することで追加トレーニングを効率的におこなえます
-
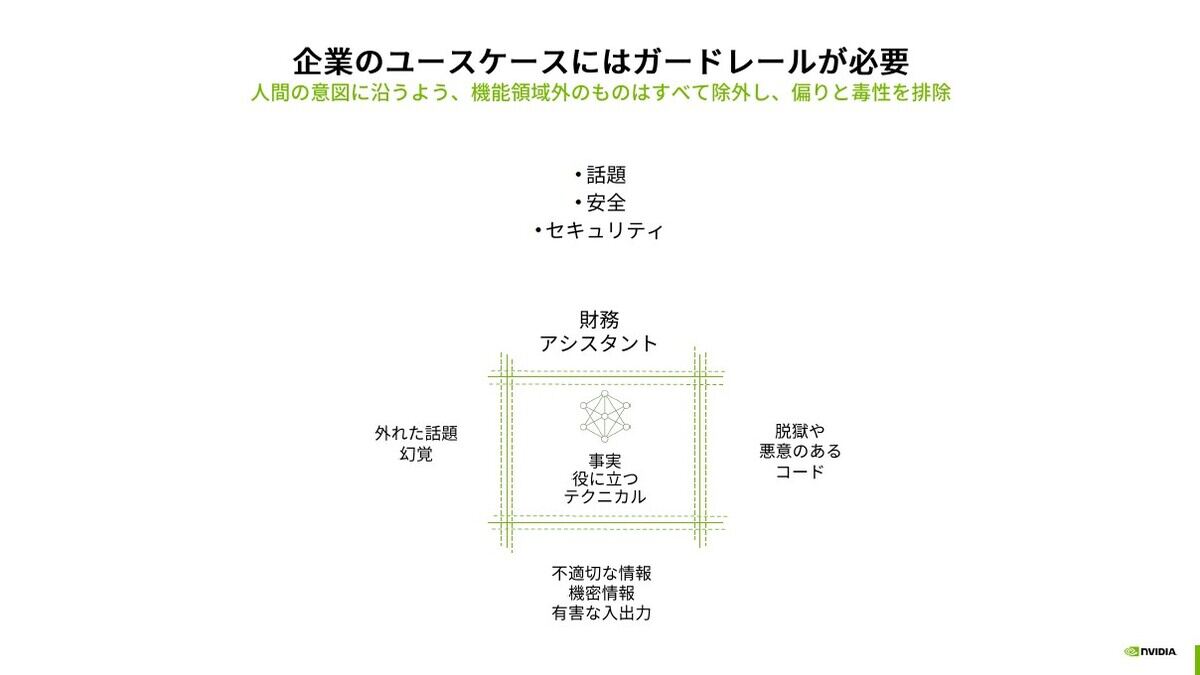
また、企業で生成AIを利用するために幻覚や悪意、不適切な結果を出力しないガードレールも提供



さらに、まだ正式サービスになっていませんがクラウドを通じたAI Foundationを3種類提供します。NeMoサービスは基盤モデルの提供に加えてNeMoフレームワークによるカスタマイズを行うことで、ファインチューニング済のモデルを比較的容易に作成できるものです。
Picassoサービスは画像生成。静止画だけでなく動画や3Dモデルの作成が可能です。3Dモデルに関してはオムニバースでの利用を想定しているようです。
BioNeMoサービスは創薬に特化しており、AIが分子の構造やたんぱく質の配列を付加栗化して、新しい分子やたんぱく質を生成したりその物性を予測することができ、時間のかかる創薬の開発時間を短縮できます。そして、いくつかの企業の結果を紹介していました。
-

クラウドを通じたAI Foundationも提供。NeMoだけでなく、画像のPicasso、創薬向けのBioNeMoを提供(予定)
-

NeMoサービスでは利用目的に合わせた3種類の基盤モデルを提供します(が、GPT-8は日本語をサポートしていないので、日本ではGPT-43/540が使われるハズ)。現在早期アクセス中
-

Picassoサービスは静止画、ビデオ、3Dモデルの生成が可能。3Dモデルはメタバースでの利用を想定しているようです。現在プライベートプレビュー中
-

BioNeMoサービスは創薬に特化した生成AI。すでにいくつかの事例が出ていますが、これも早期アクセス中




生成AIの活用例……実はマイナビも実証実験で活用!
生成AIの活用例として、いくつかの例が示されましたが、日本企業に関しての言及はありませんでした。これは別の取材でいくつか聞いておりまして、補足したいと思います。
-

生成AIの応用事例としてServiceNowとエンタープライズIT構築で連携中
-

snowflakeのデータを活用してカスタムLLMの構築でチャットボットの高性能化や要約、検索を実現


その活用事例の1つがマイナビ! といってもマイナビニュースではありません。マイナビバイトはAIスタートアップのELYZAが独自に開発する国産の大規模言語モデル「ELYZA Brain」にマイナビ独自の学習データを加えた原稿執筆生成AIを作成し、昨年から実証実験を行いました。
アルバイト求人広告原稿の草案作成と修正原稿にこの生成AIを使用することで、平均30%の業務効率化を達成し、全面的に採用すると月間約500~700時間の原稿作成工数の削減ができるとのこと(ニュースリリース)。
また、パナソニックコネクトはGPT-4ベースのConnectAIを作成して、国内全社員が利用できるようにしています(参考記事)。
近い将来、ビジネスでAIが当たり前になり社員はAIを利用する一方、社内AIを提供しないとリスクの高いシャドーAIを利用しトラブルとなるので、社内AIを提供することで安全なAI利用を行わせたいという説明を聞いています。
3カ月の運用結果として、想定の5倍以上がAIを利用している他、想定以外の有効利用があったほか、不適切な利用はアラートは上がったものの重大な問題はなかったといいます(「電気分野での自殺回路の意味を教えてください」、「寄生インピーダンスとはなんですか」、「切削加工で四角に穴をあける方法を教えて」のようなプロンプトでアラートが発生したものの「自殺」「寄生」「切削」の単語で機械的に引っかかったと判断)。
業務利用での課題としては「自社固有の質問には回答できない」が挙げられており、これらは公開情報を使用した自社特化AIの試験運用を9月から試験運用するほか、段階的に社外秘を含めたデータも使用するという説明がありました。
なお、7月28日に「NVIDIA 生成AI Day 2023 Summer」と題したオンラインベントを実施します。すでに基調講演のライブ配信枠は満席でイベント終了後にオンデマンド配信で視聴可能、他のセッションも順次オンデマンド配信があるので興味があれば登録されるとよろしいでしょう(外部リンク)。
-

オマケ。新しいBingはGPT-4にBing検索を組み入れたもので、これによって学習後のデータも活用できます。「テクニカルライターの小林哲雄」について問い合わせたところ、検索時点で最新の記事までフォローしていました。一方、以前「小林哲雄」に関して問い合わせたところ「取締役社長で無職」というトンデモ回答をしていましたが、どうやら検索で見つけた二つの小林哲雄の内容を合体させたためのようで、後日箇条書き表記に改定されていました









