
◆Sandra 2021(グラフ72~136)
Sandra 2021
SiSoftware
https://www.sisoftware.co.uk/
久々のSandraフルコースである。ちなみにこちらのグラフの表記であるが、MT+MC(Multi-Thread+Multi-Core)に関しては冒頭で述べた通りであるが、1T(Single Thread)テストに関してはE-CoreとP-Coreを別々に記している。Zen 4の方はそもそもUnified Coreという事もあり、特にこの表記は無い。また、1Tの場合でも.NETではそもそもSingle Threadという動作が無いので、一応P-Core扱いとして結果を示している。
-
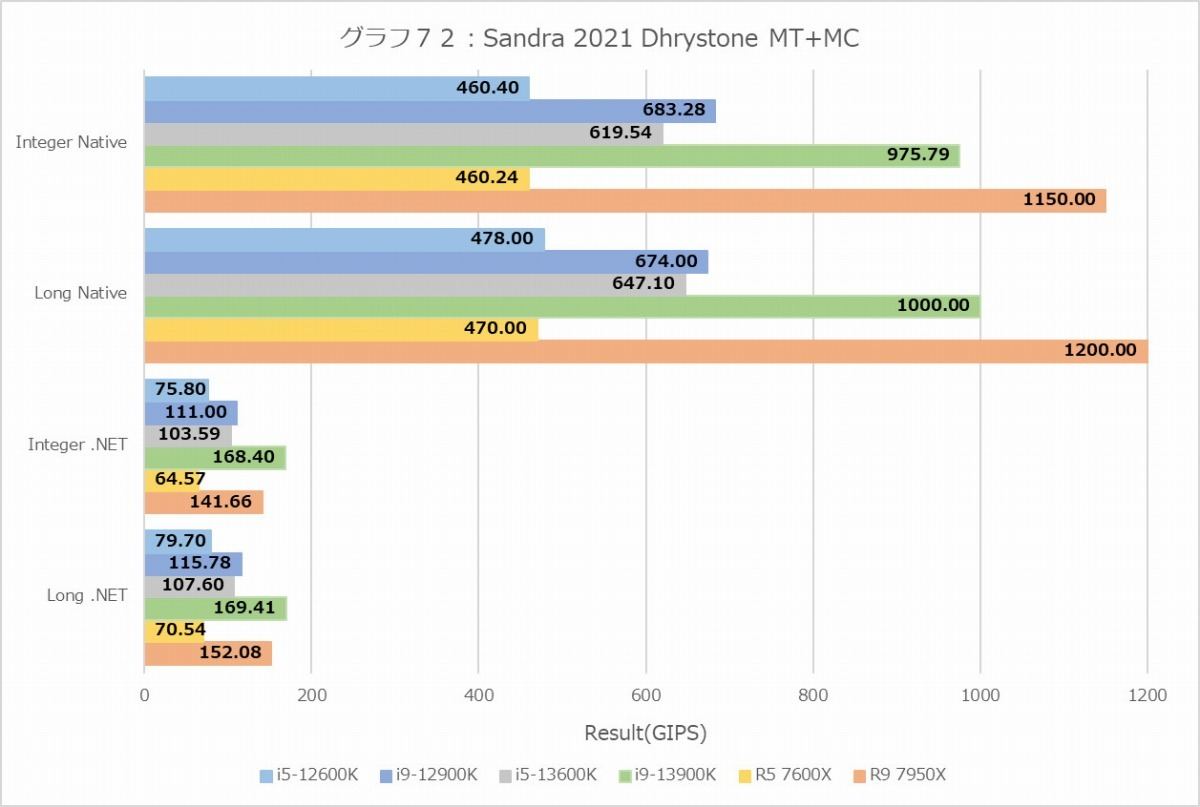
グラフ72

-
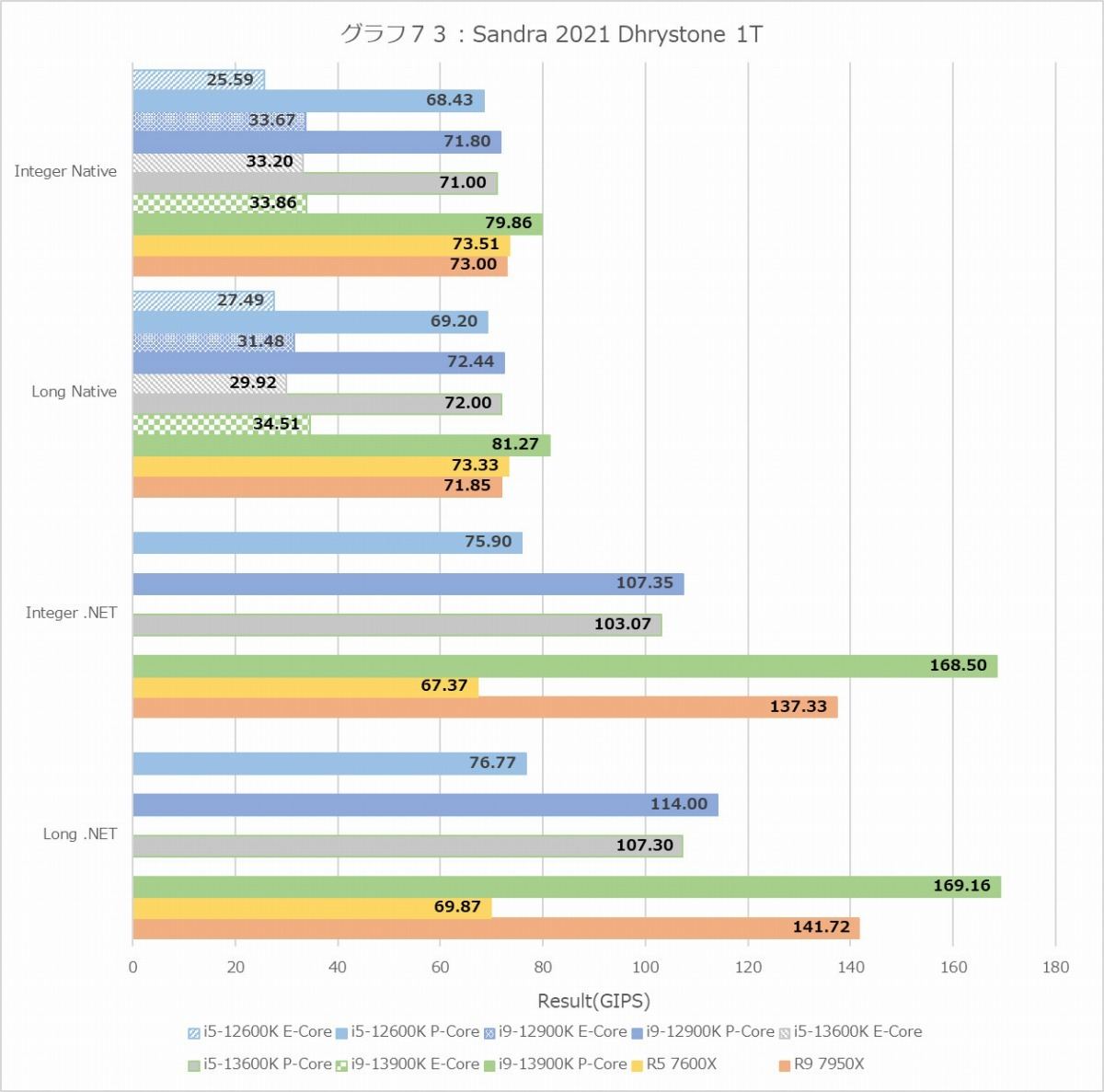
グラフ73

-
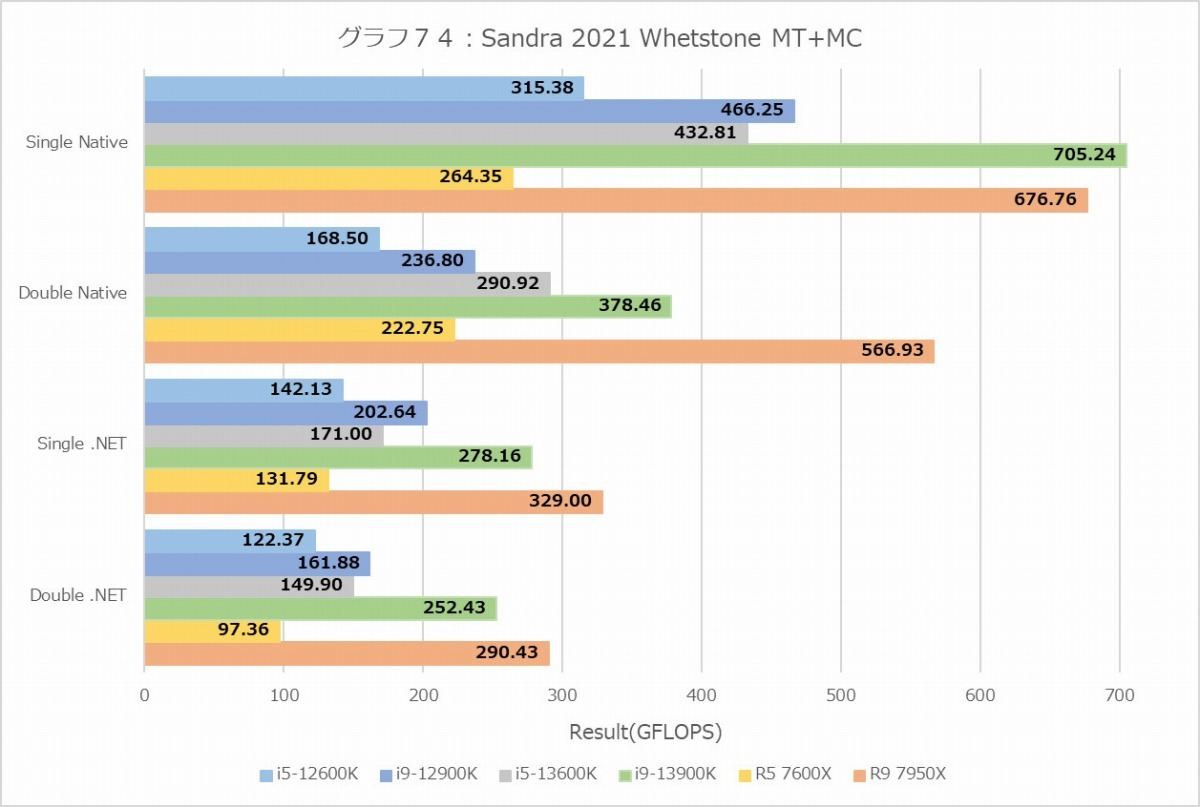
グラフ74

-
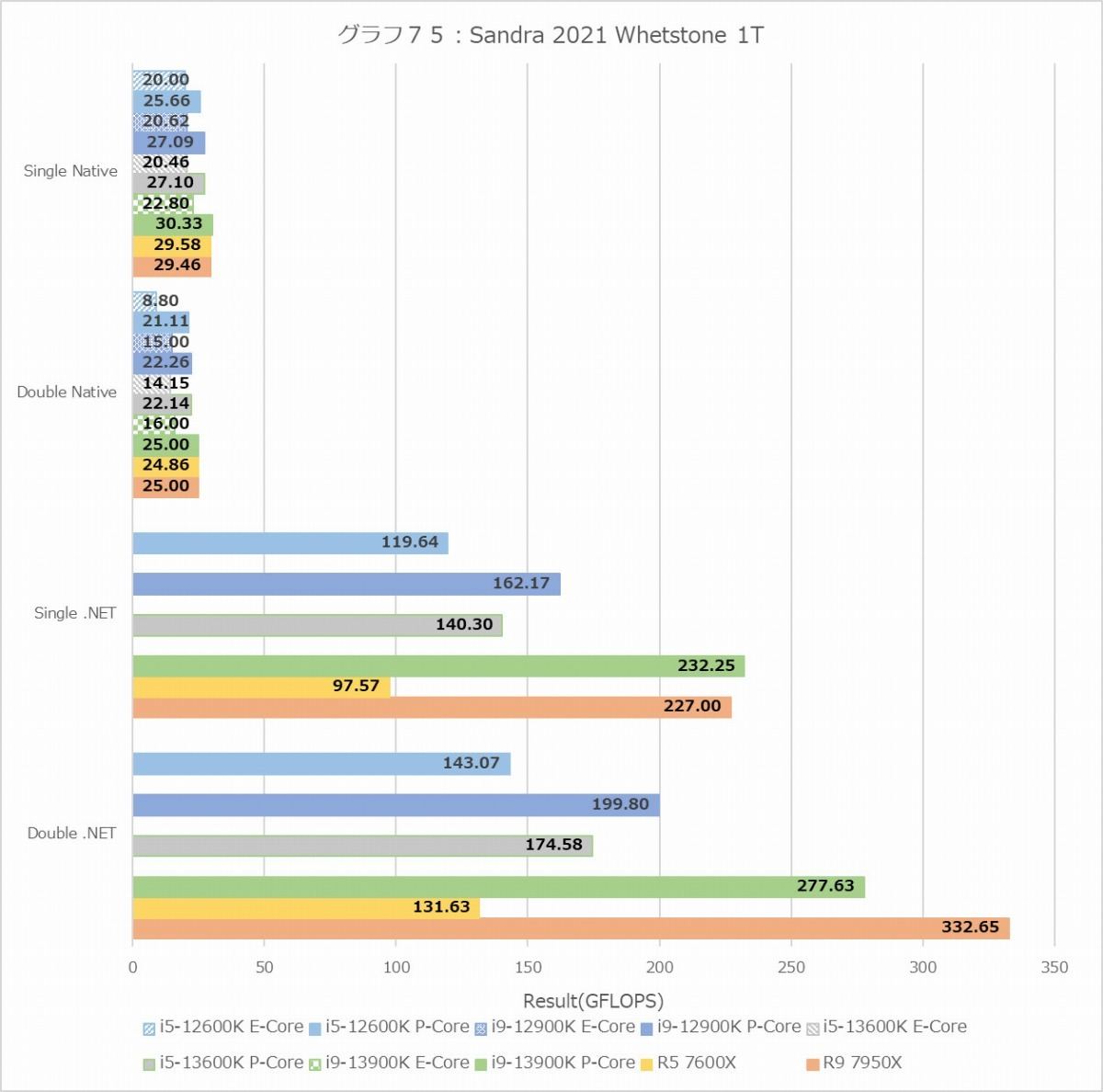
グラフ75

ということでまずはDhrystone(グラフ72・73)とWhetstone(グラフ74・75)。なんとなく想像出来た事であるがMT+MC、つまり全コアをフルに使うケースで言えばRyzen 9 7950Xが最速という結果になった。勿論色々付帯条件は付き、ALUはRyzen 9 7950Xが最速だがFPUではCore i9-13900Kが最速の座を奪い返している。まぁこれはある意味当然で、Zen 4コアはFPUに関しては1cycleあたり同時2命令発行(実行ユニットは4つあるが、補完的に動くのでFPU命令は実質2つ)なのに対し、Alder Lake/Raptor LakeのGolden Coveは限定的ながら3命令の発行が可能だからだ。ただWhetstone MT+MCで見てもCore i9-13900Kが優位なのはSingle Nativeのみで、Doubleあるいは.NETだとRyzen 9 7950Xの方が性能が上なあたりは、実はCore i9-13900Kの優位はそう大きくは無いと言える。それともう一つはCore i5-13600Kの性能の高さで、ほぼCore i9-12900Kに匹敵する事がここからも確認できた。
一方で面白いのが1T。ALUにおけるE-CoreことTremontの性能は、P-CoreことGolden Coveのざっくり半分といったところ。一方でFPUでは6~7割程度と、ALUよりはやや性能が高い。Core i9-13900KがWhetstoneのMT+MCで最速なのは、このE-Coreが16個もあるお蔭で、トータルではP-Coreが10個分位の性能を叩き出していることで、元々のP-Core×8とあわせて実質18コア相当位になっていることが効果的に作用している様にも思われる。
あと面白いのは、ALUの場合は動作周波数の差もあってかRyzen 9 7950XはCore i9-13900Kに及ばないのに、FPUでは互角な事だろうか。このあたりは非常に興味深い。
-
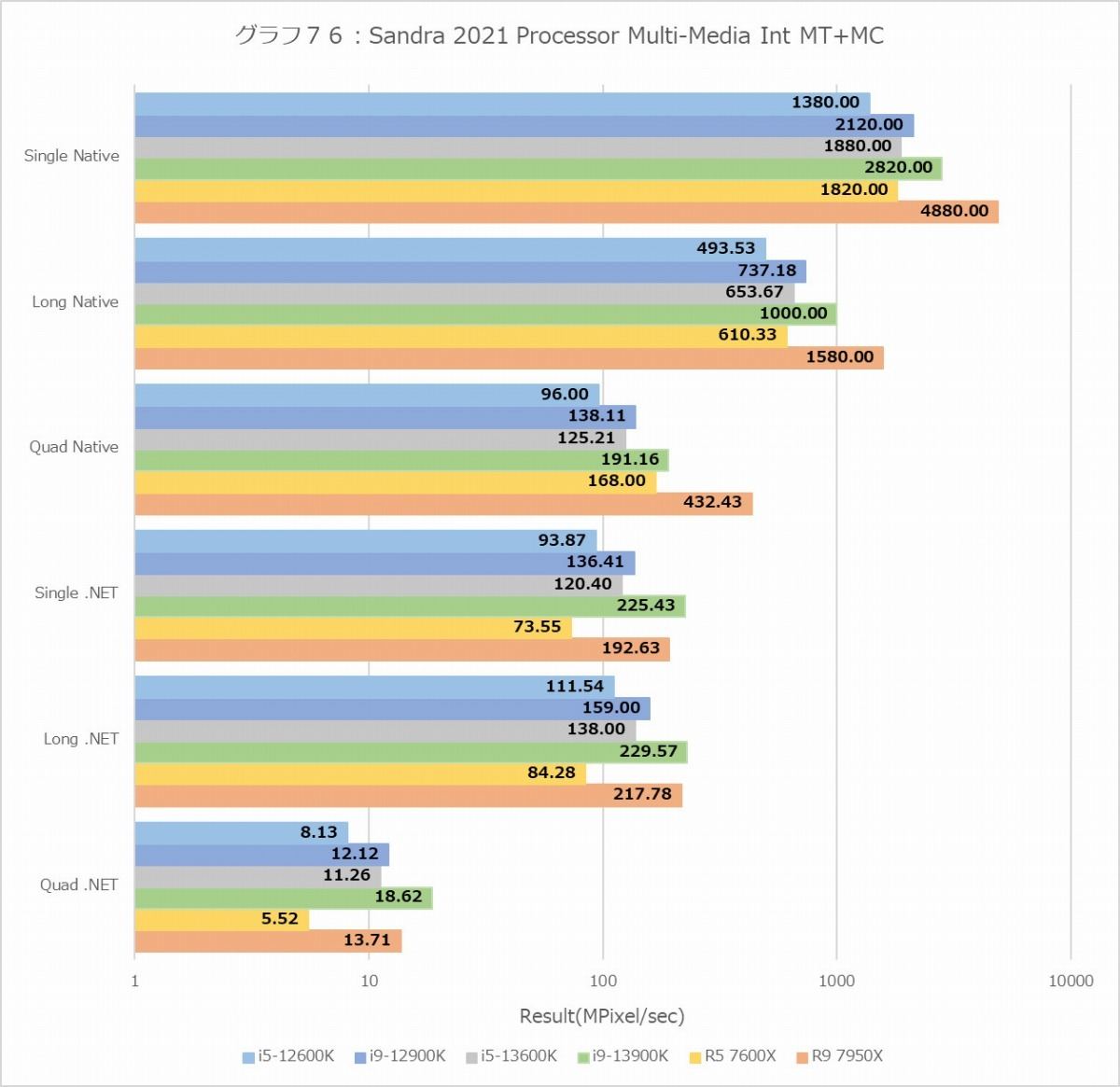
グラフ76

-
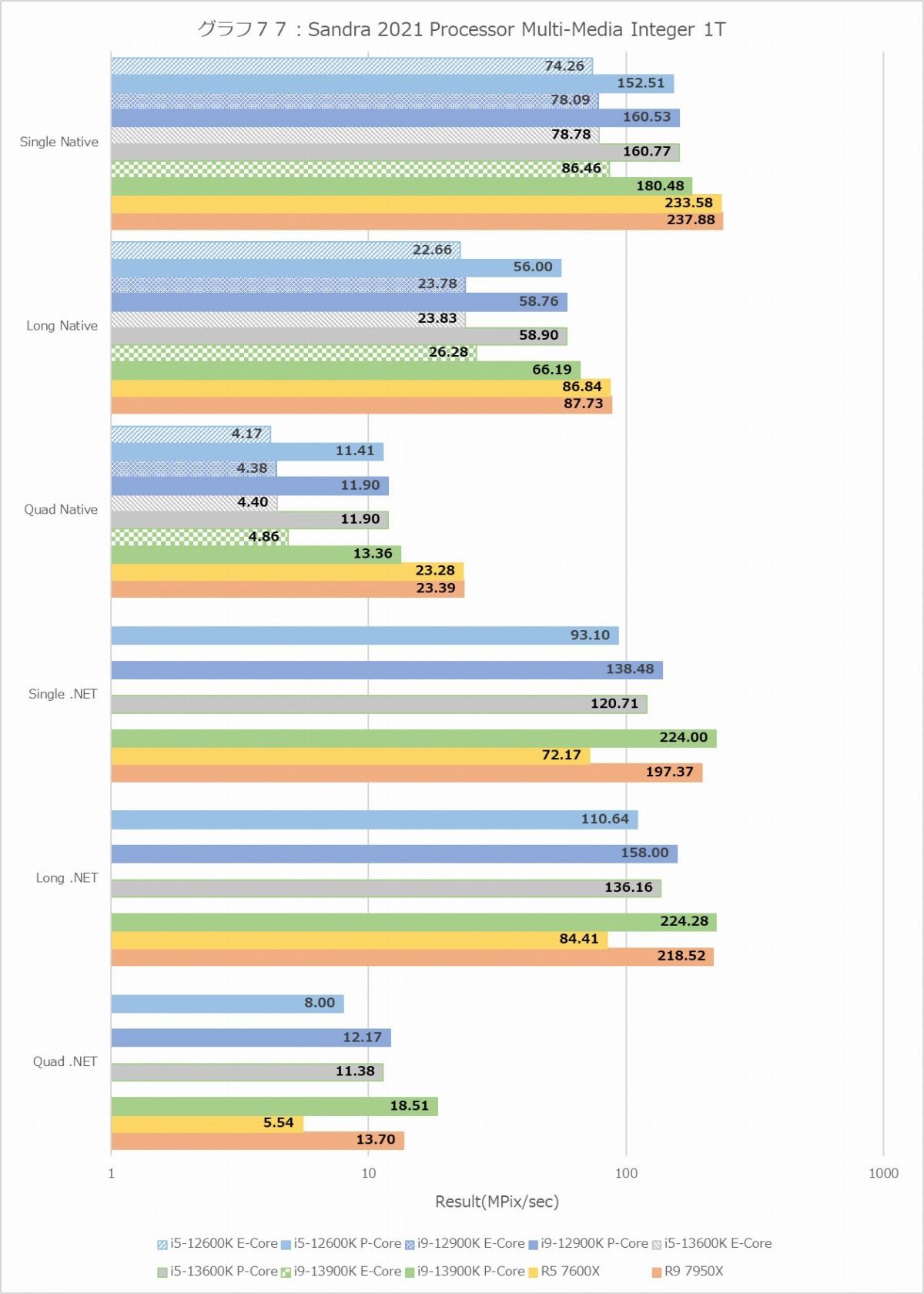
グラフ77

-
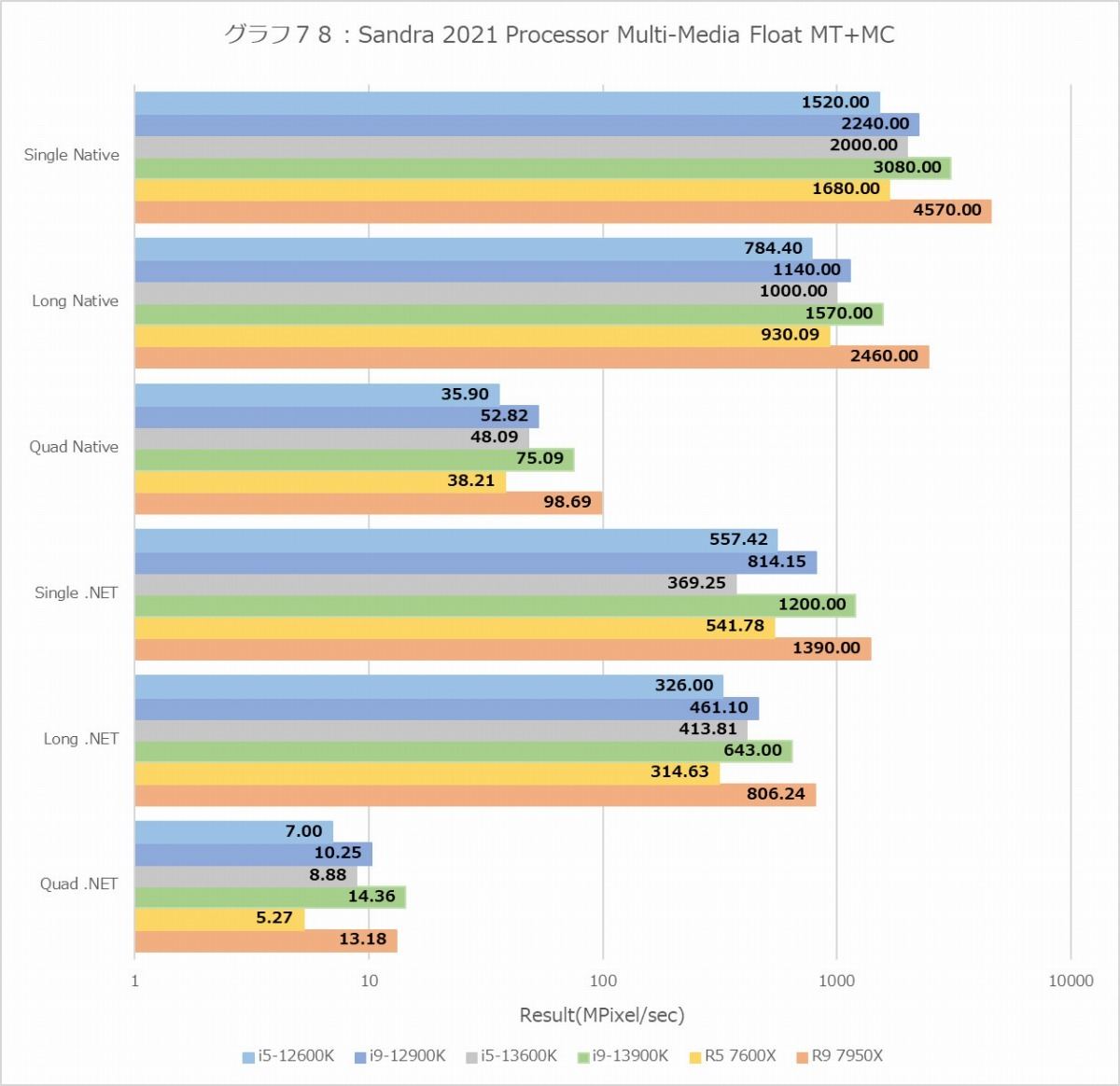
グラフ78

-
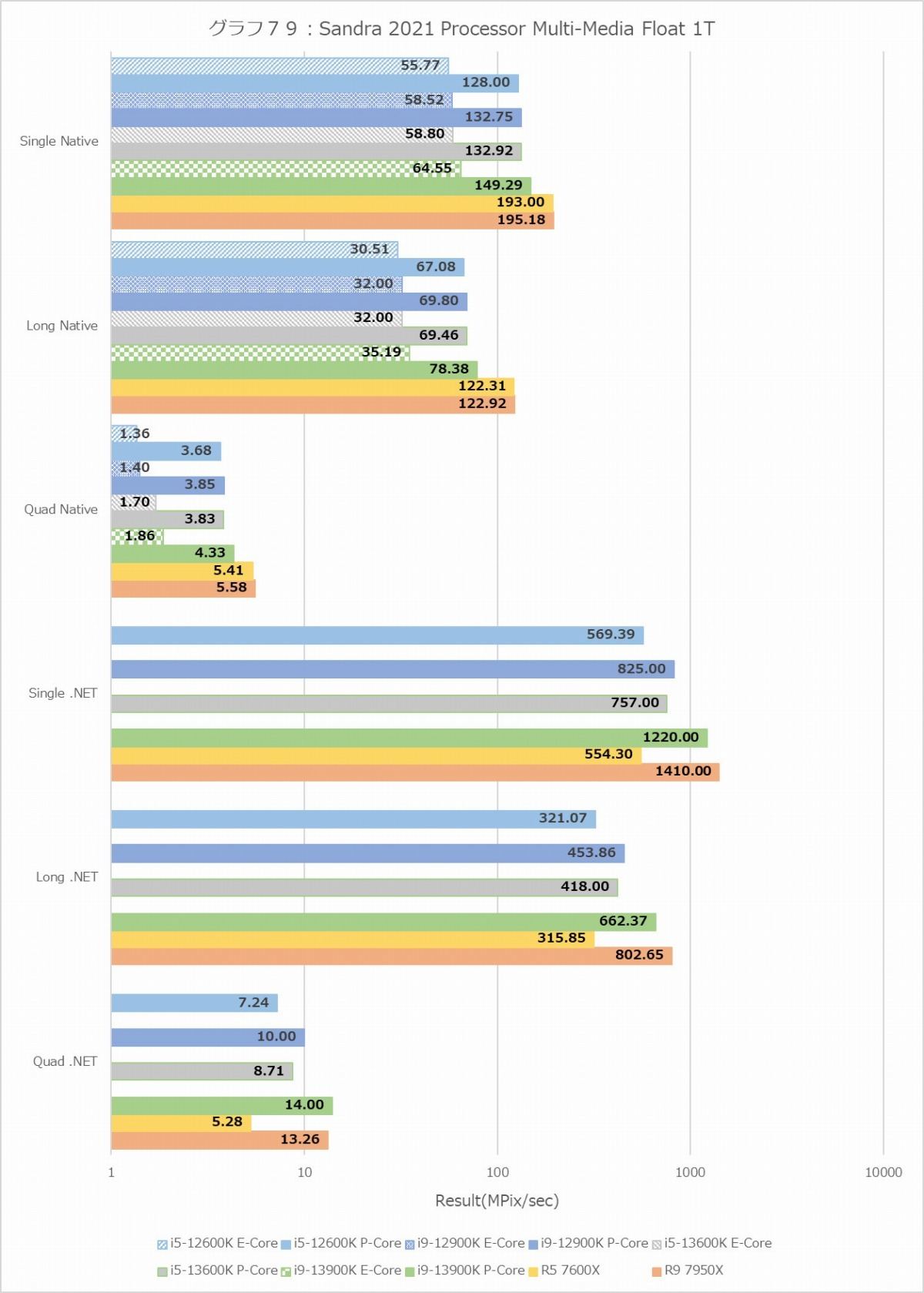
グラフ79

次がProcessor Multimedia(グラフ76~79)であるが、結果に2桁の幅がある関係で、横軸は対数軸である。なので棒グラフそのものではなく結果の数字を見て判断していただきたい。さて、意外にもInt/Float、MT+MC/1Tを問わずRyzen 9 7950Xが最速なのはちょっと面白かった。FloatでもRyzen 9 7950Xが優位、というのは単に実行ユニットだけの問題ではないのかもしれない。またここでもTremontの性能はALUに関してはGoldenCoveの半分だが、FPUは半分未満まで落ちているあたりも興味深い。
-
グラフ80

-
グラフ81

-
グラフ82

-
グラフ83

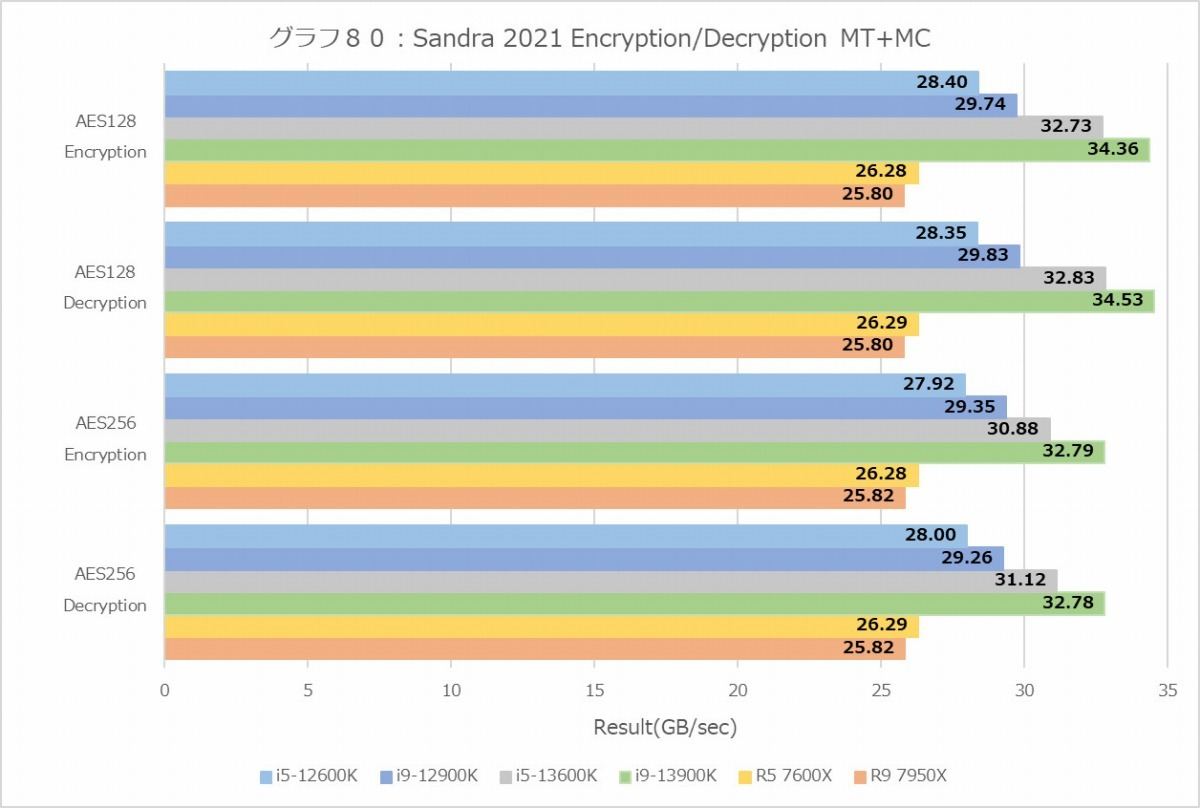
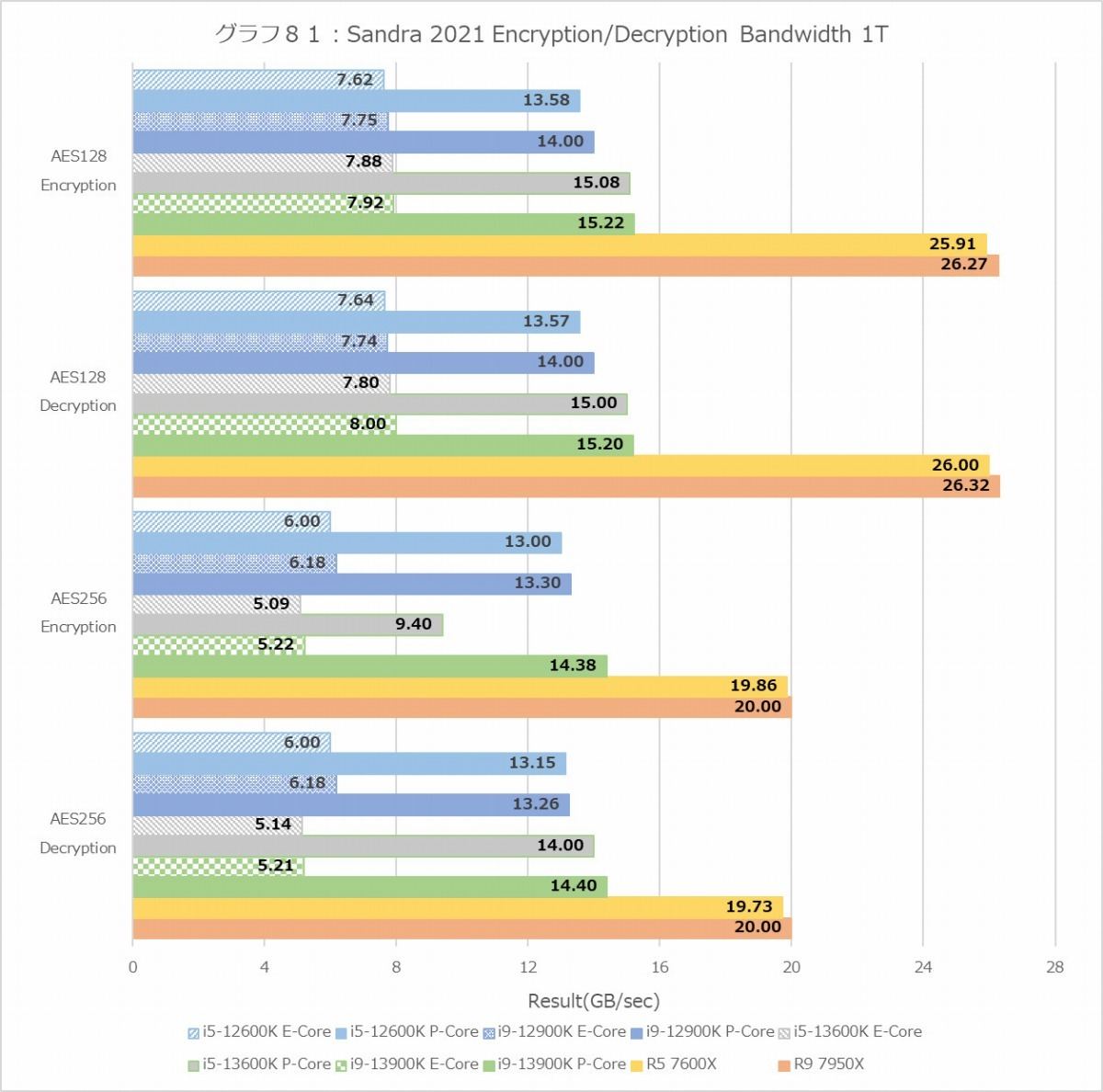
Cryptography(グラフ80~83)も楽しい。まずAESのEncryption/Decryptionであるが、MT+MCではAlder Lake/Raptor Lakeの方が高速なのに、1TだとZen 4が圧倒的に性能が上である。更に言えば、Zen 4はMT+MCと1Tで殆どスコアが変わらない。これは何かといえば、要するにコアに統合されたAES命令(AES-NI)の処理性能そのものはZen 4の方が高速であるという話で、ところがメモリコントローラがボトルネックになってZen 4では1Tの場合でもMC+MTの場合でもほぼスループットは同じ。対してAlder Lake/Raptor Lakeではコアあたりの性能はZen 4の半分だが、メモリアクセスがもう少しスケールするためにトータルでは性能が上、という話だ。あとTremontコアには暗号化エンジンがDualで搭載されている筈だが、1Tでの性能を見るとGolden Coveの半分というあたりは、Sandraではこの暗号化エンジンを使っていない公算が高い。
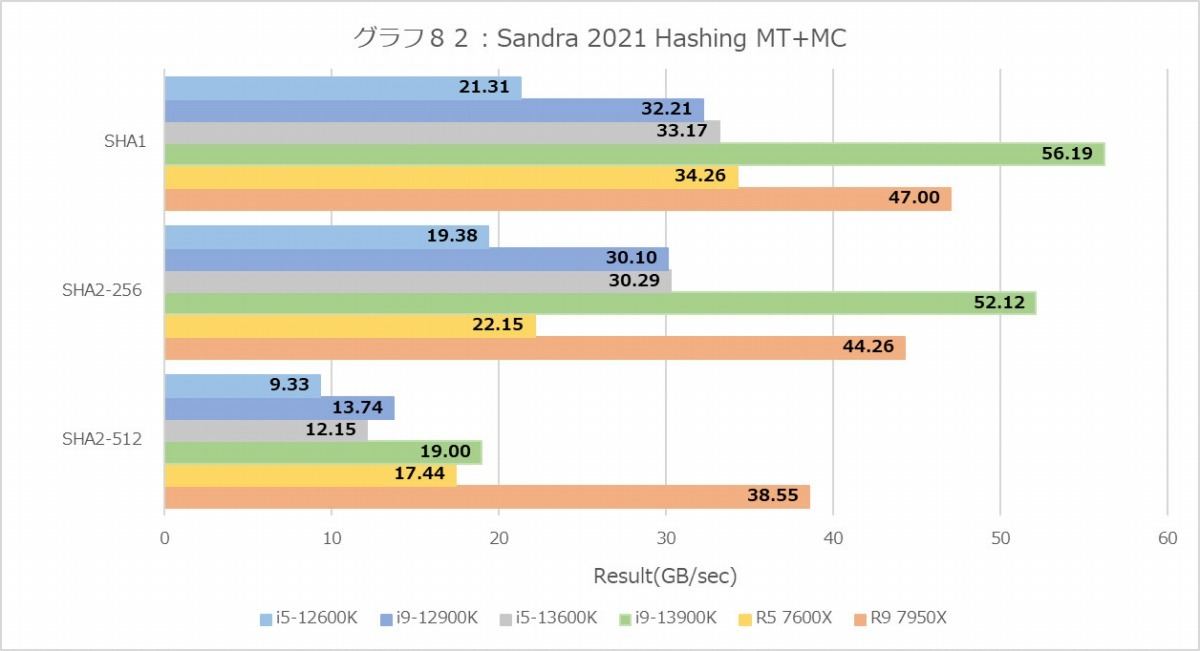
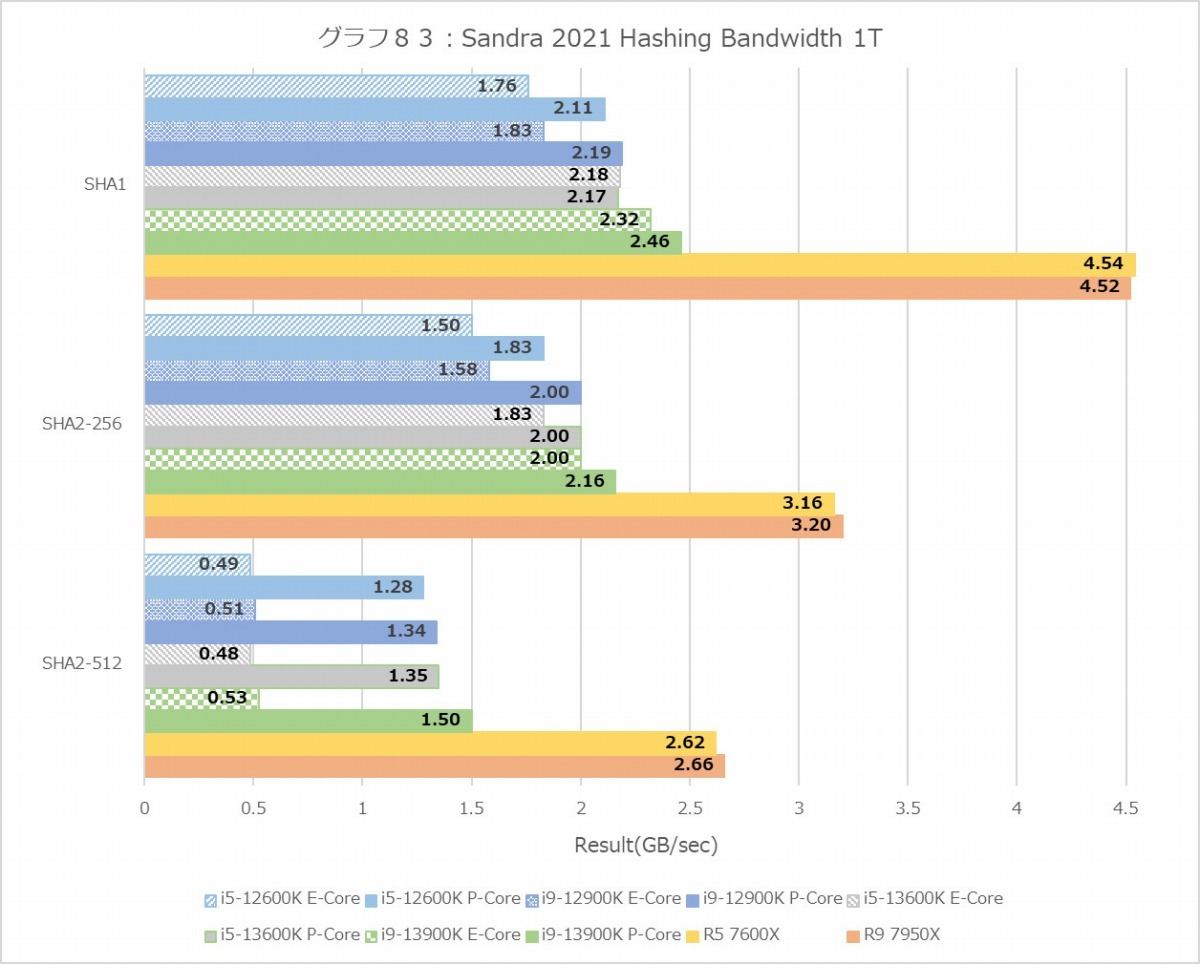
一方Hashingの方であるが、MT+MCではCore i9-13900Kが何とかRyzen 9 7950Xを上回っているが、1TではZen 4の圧勝といったところ。あと、以前の記憶ではSHA-512に関してはAMDよりもIntel系の方が良い成績を出していた記憶があるのだが、今回見る限りZen 4はAlder Lake/Raptor Lakeを完全ブッチギリといったところ。なにせCore i9-13900KとRyzen 5 7600Xが同等に近いというあたりは、相当Zen 4でここを強化した事が伺い知れる。
-
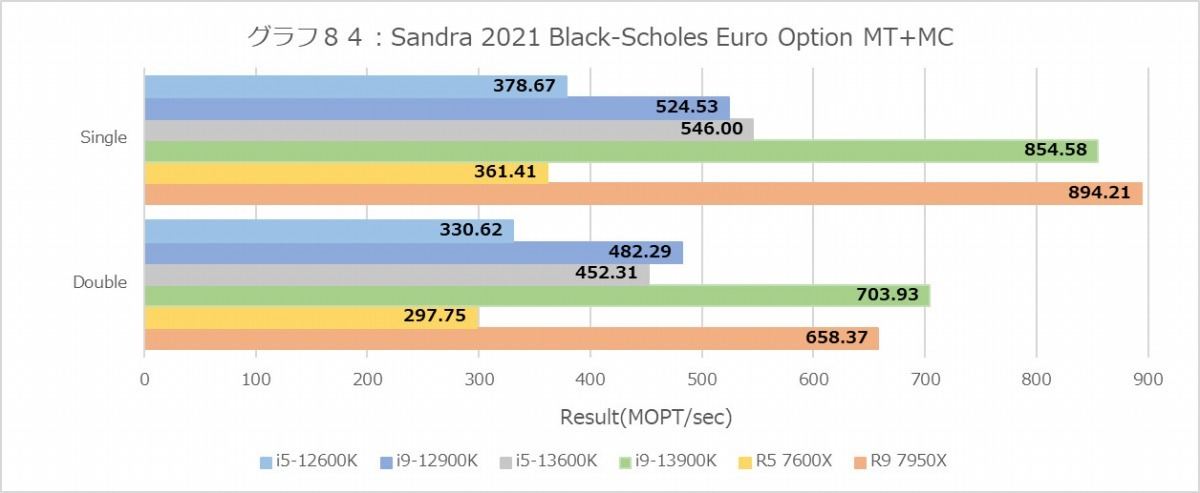
グラフ84

-
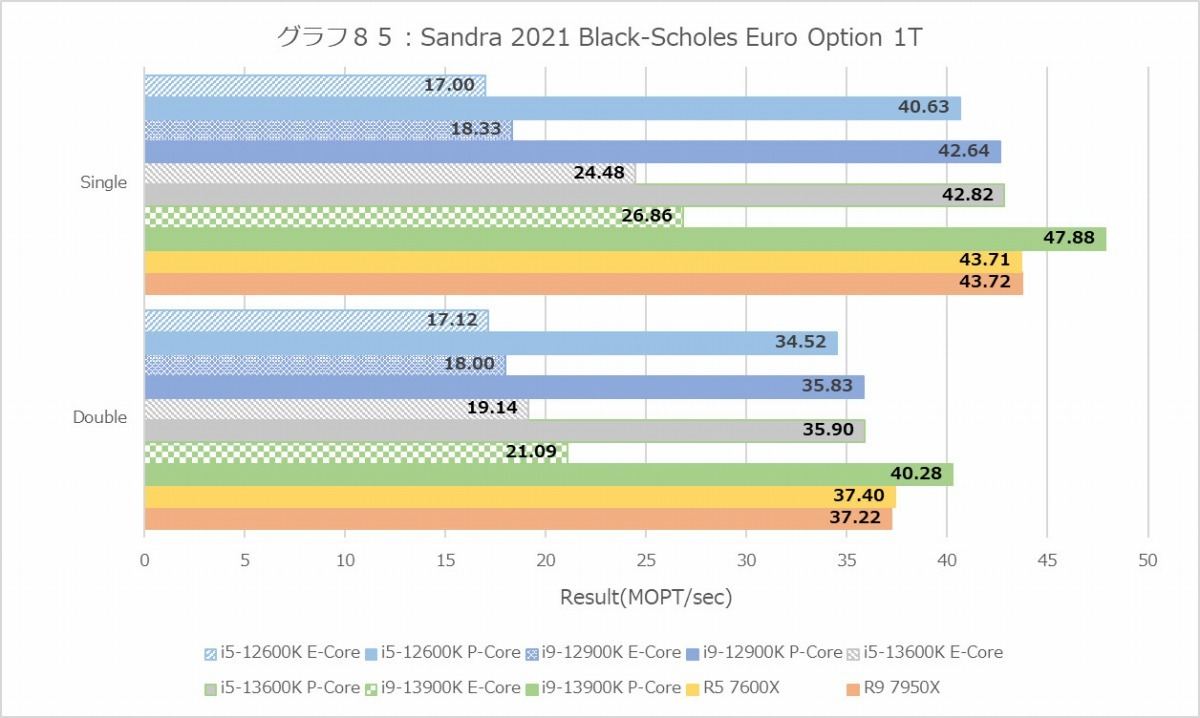
グラフ85

-
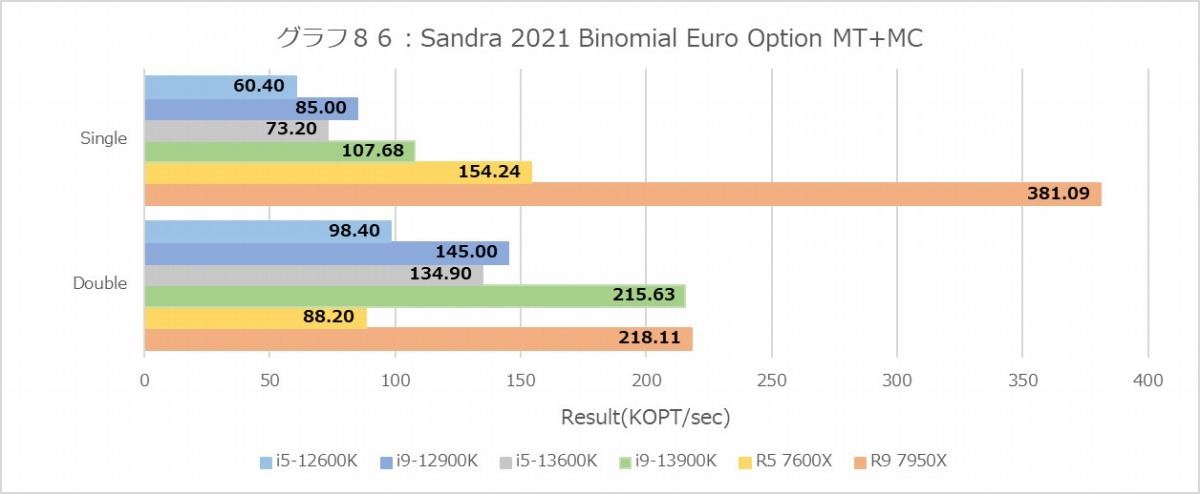
グラフ86

-
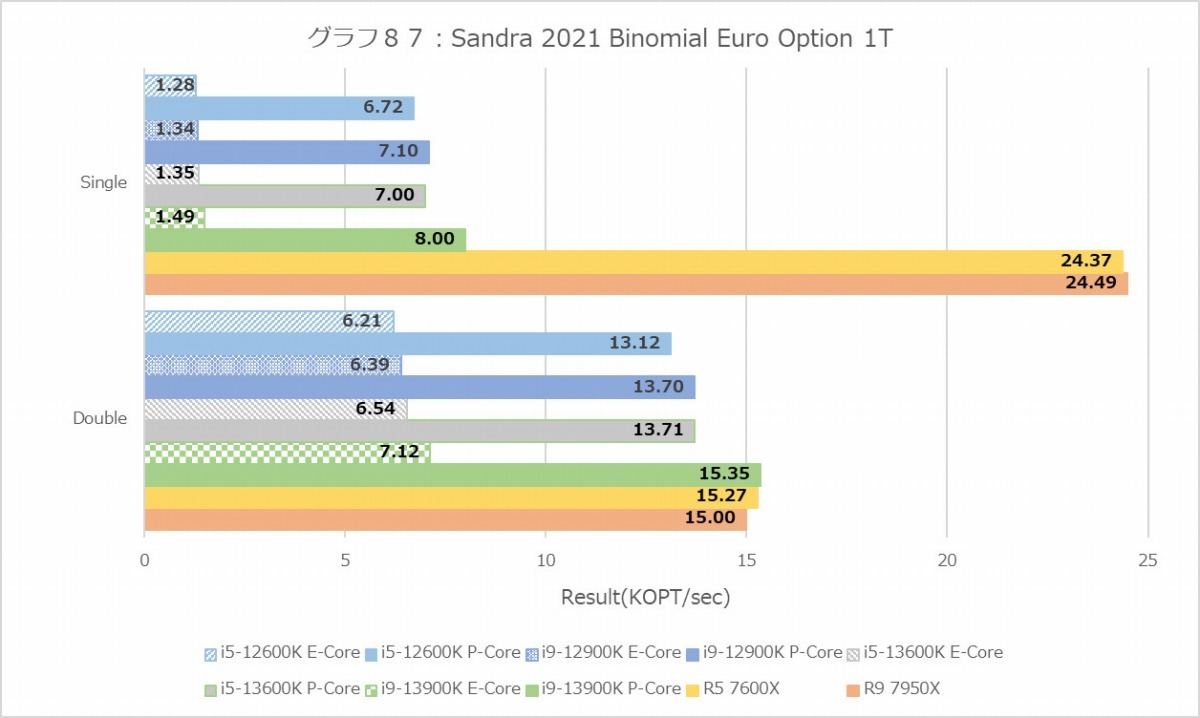
グラフ87

-
グラフ88

-
グラフ89

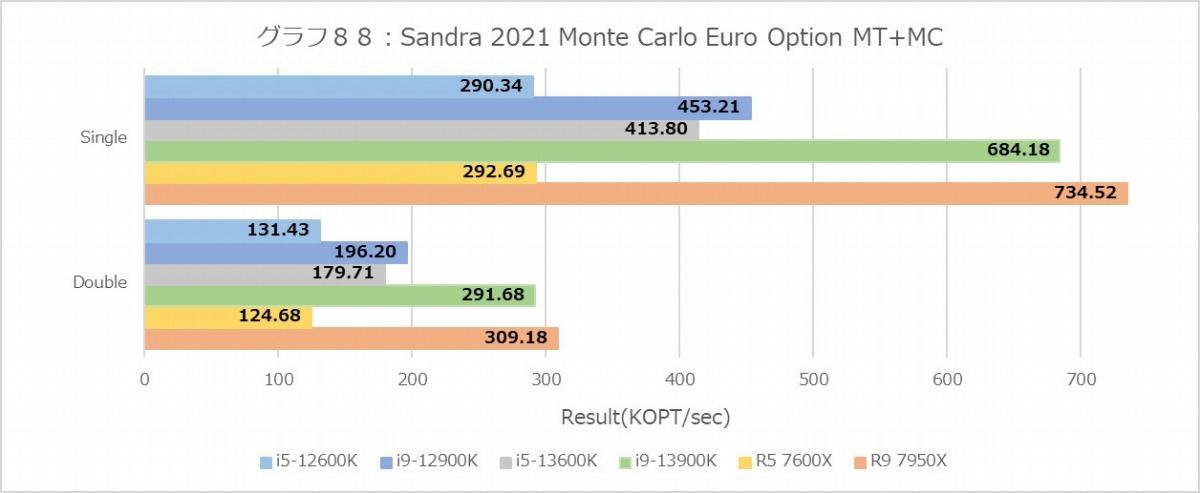
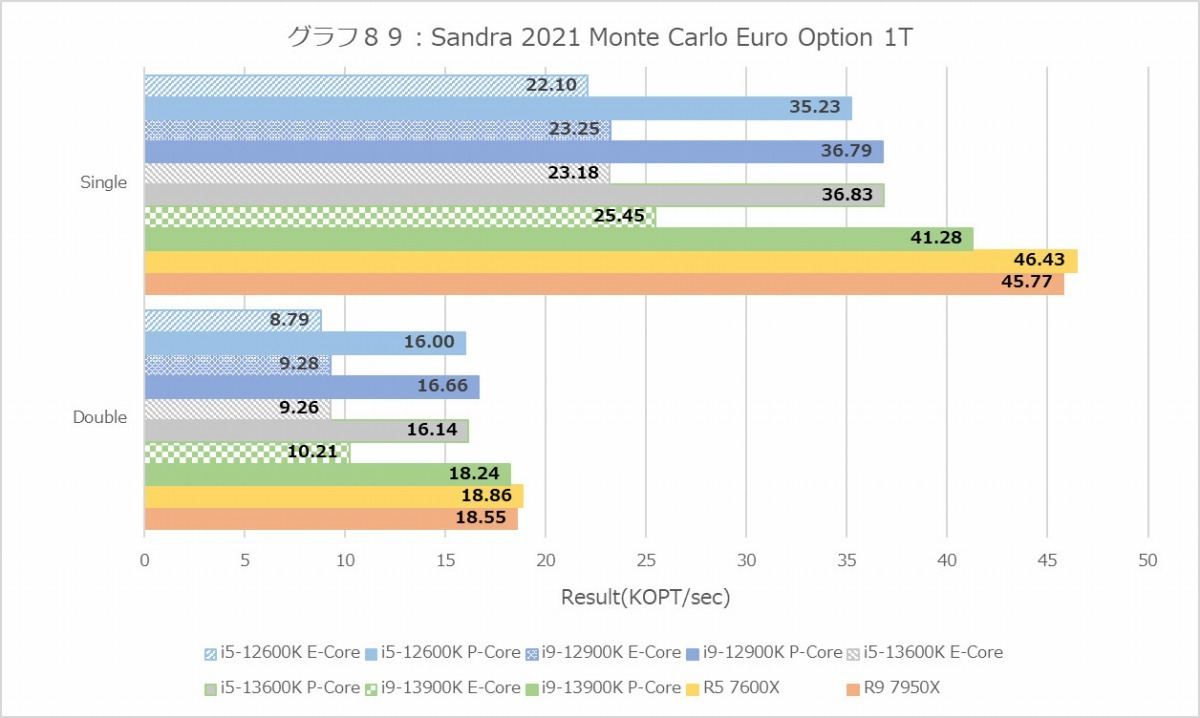
Financial Analysis(グラフ84~89)は再びZen 4系が有利な結果になっている。勿論Core i9-12900KとCore i5-13600Kのスコアがほぼ同じというあたり、Raptor Lakeも健闘しているのは間違いないのだが、ここに関してはZen 4の方が明らかに有利になっている。
ちなみにE-CoreというかTremont、Black-ScholesとかMonte Carloでは概ねGolden Coveの半分程度の性能だが、なぜかBinomialでは1/4近くまで性能が低下している。アプリケーション次第では結構TremontコアのFPUの性能は落ちるようだ。
-
グラフ90

-
グラフ91

-
グラフ92

-
グラフ93

-
グラフ94

-
グラフ95

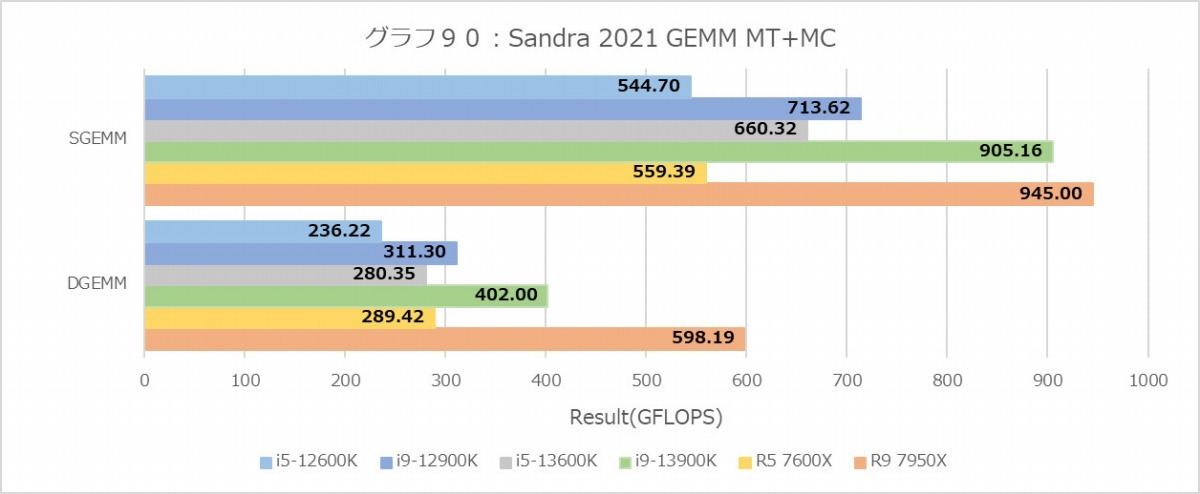
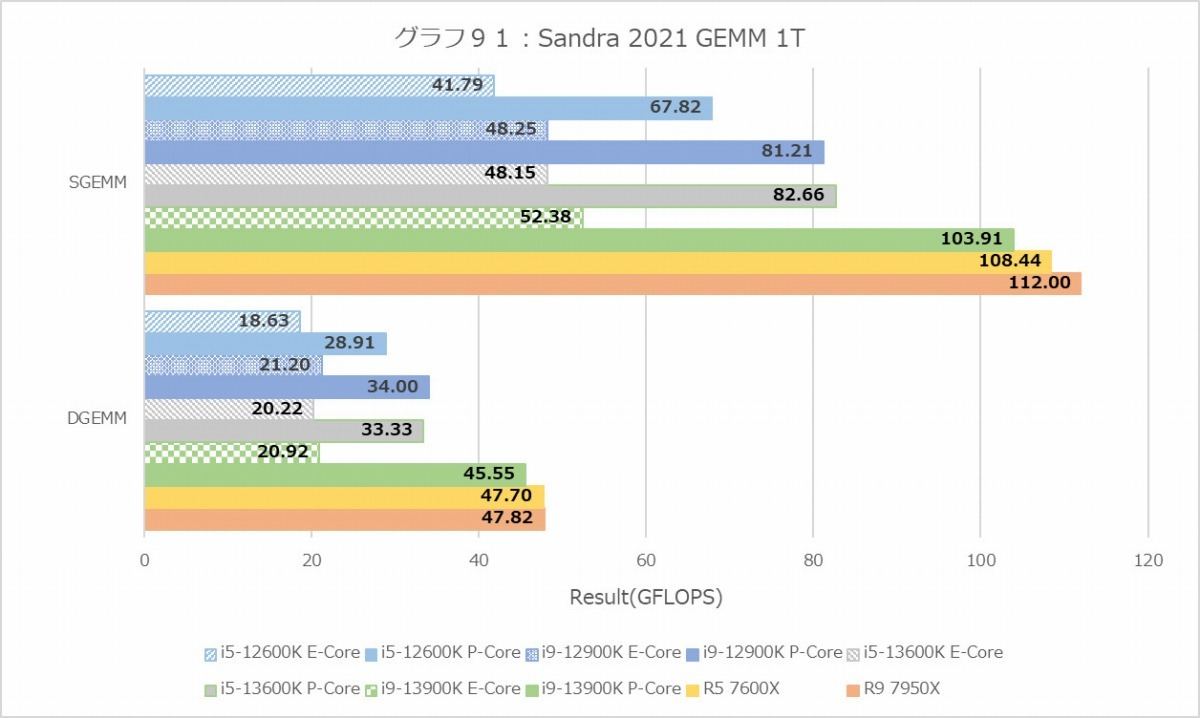
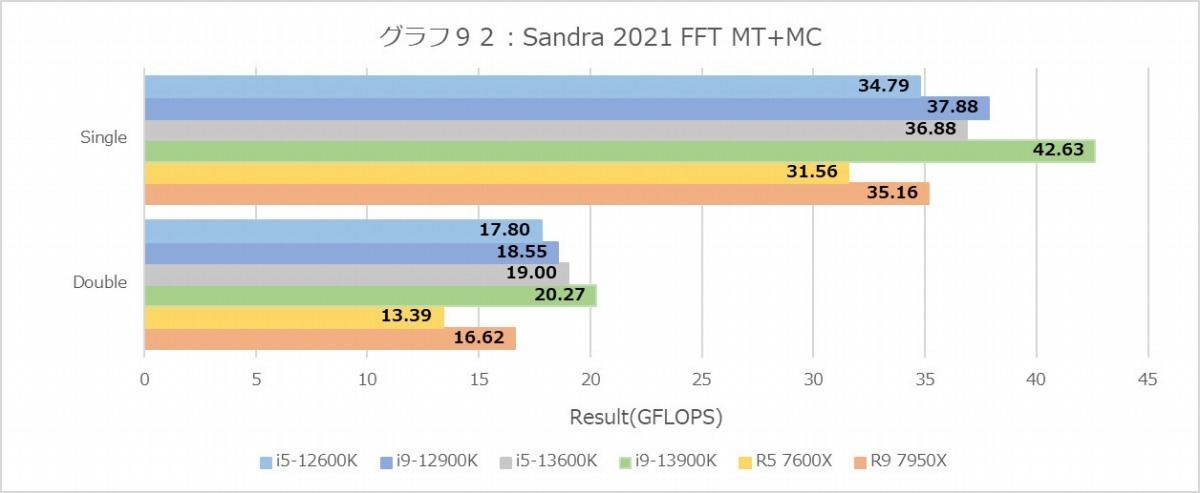
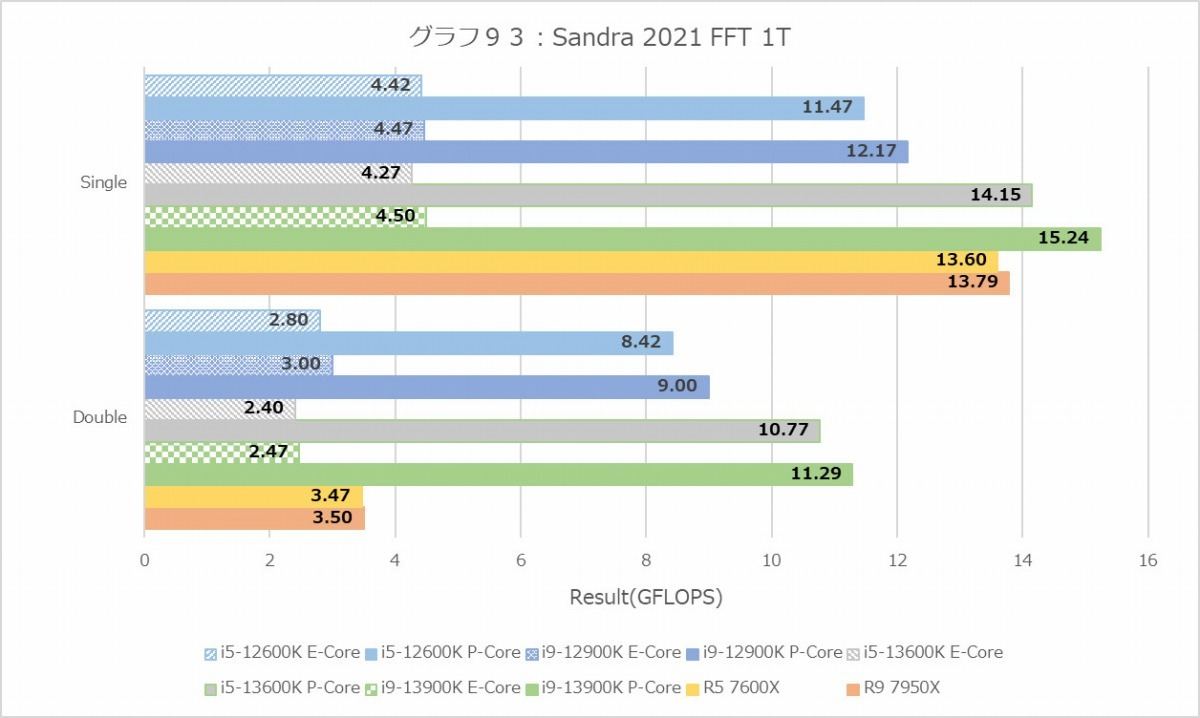
グラフ90~95はScientific Analysisの結果だが、まずGEMMのMT+MCで興味深いのはRyzen 5 7600Xの成績が悪くない事。Core i5-12600Kを凌駕し、Core i5-13600Kにかなり近い(DGEMMでは凌駕している)。1TではCore i9-13900Kを超えており、かなり性能の上乗せが見られる。もっともFFTでは逆にかなり性能が低く、特にDoubleの1TではZen 4コアの性能はTremontコアよりちょいマシという程度。逆にこのDouble、Golden Coveコアの場合1TとMT+MCの性能がそんなに違わないという辺りは、先にメモリがボトルネックになっているっぽい。
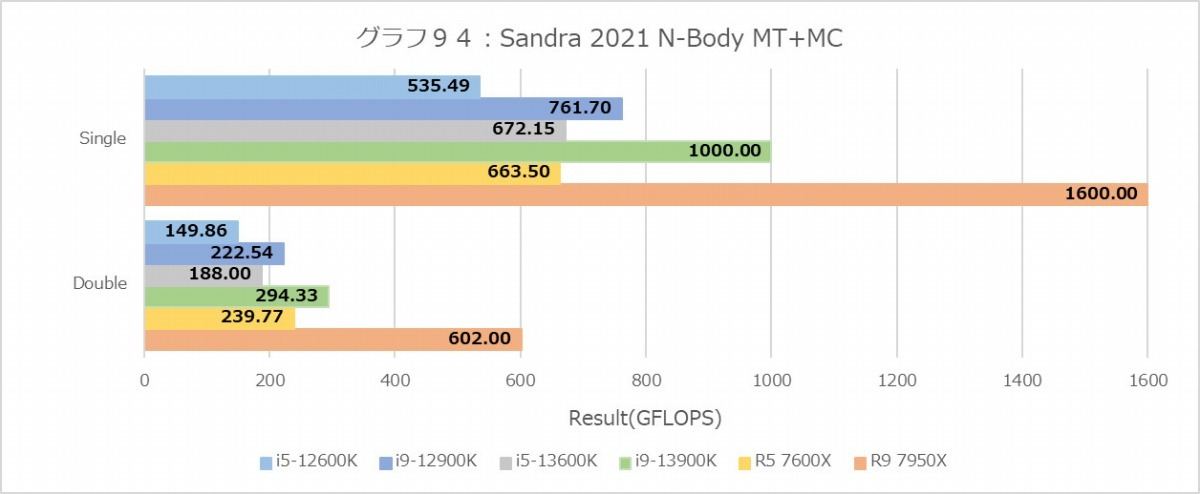
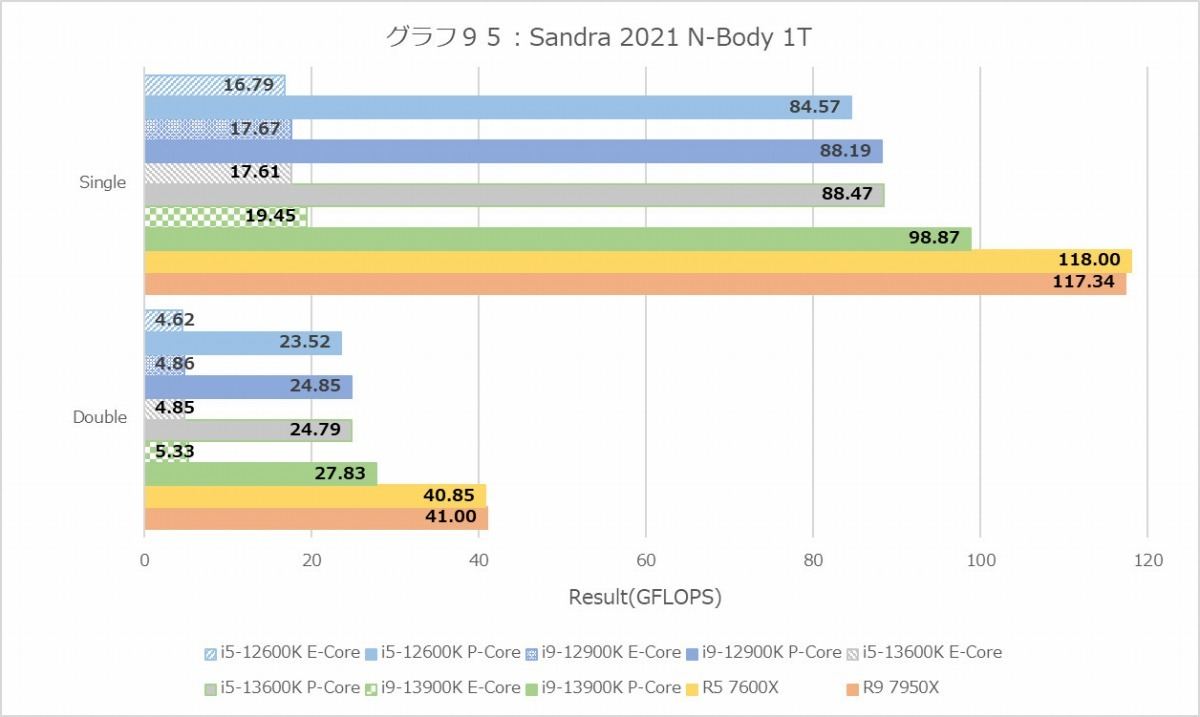
N-Bodyでは再びZen 4コア有利で、しかも1Tの場合で見るとTremont Coreの性能はこれも1/4以下に落ちているあたり、あんまりTremontコアは数値計算をやらすべきではない、という気もする。
-
グラフ96

-
グラフ97

-
グラフ98

-
グラフ99

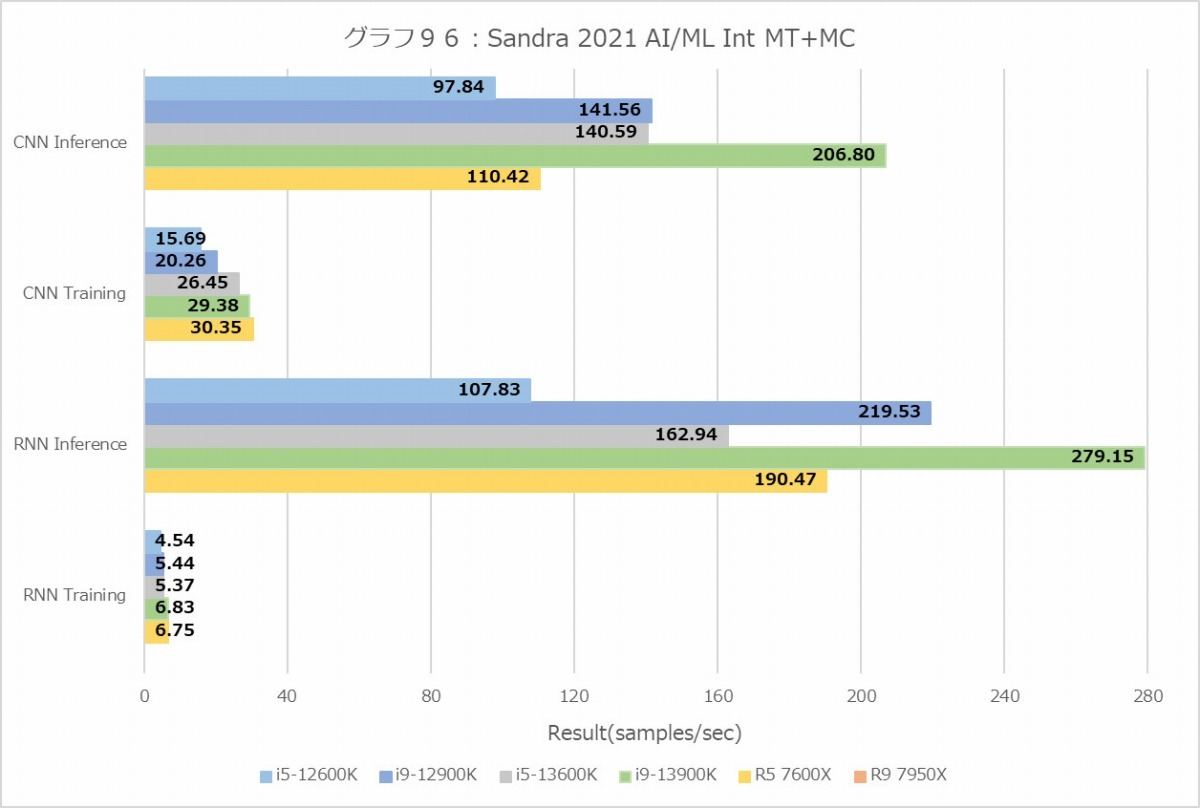
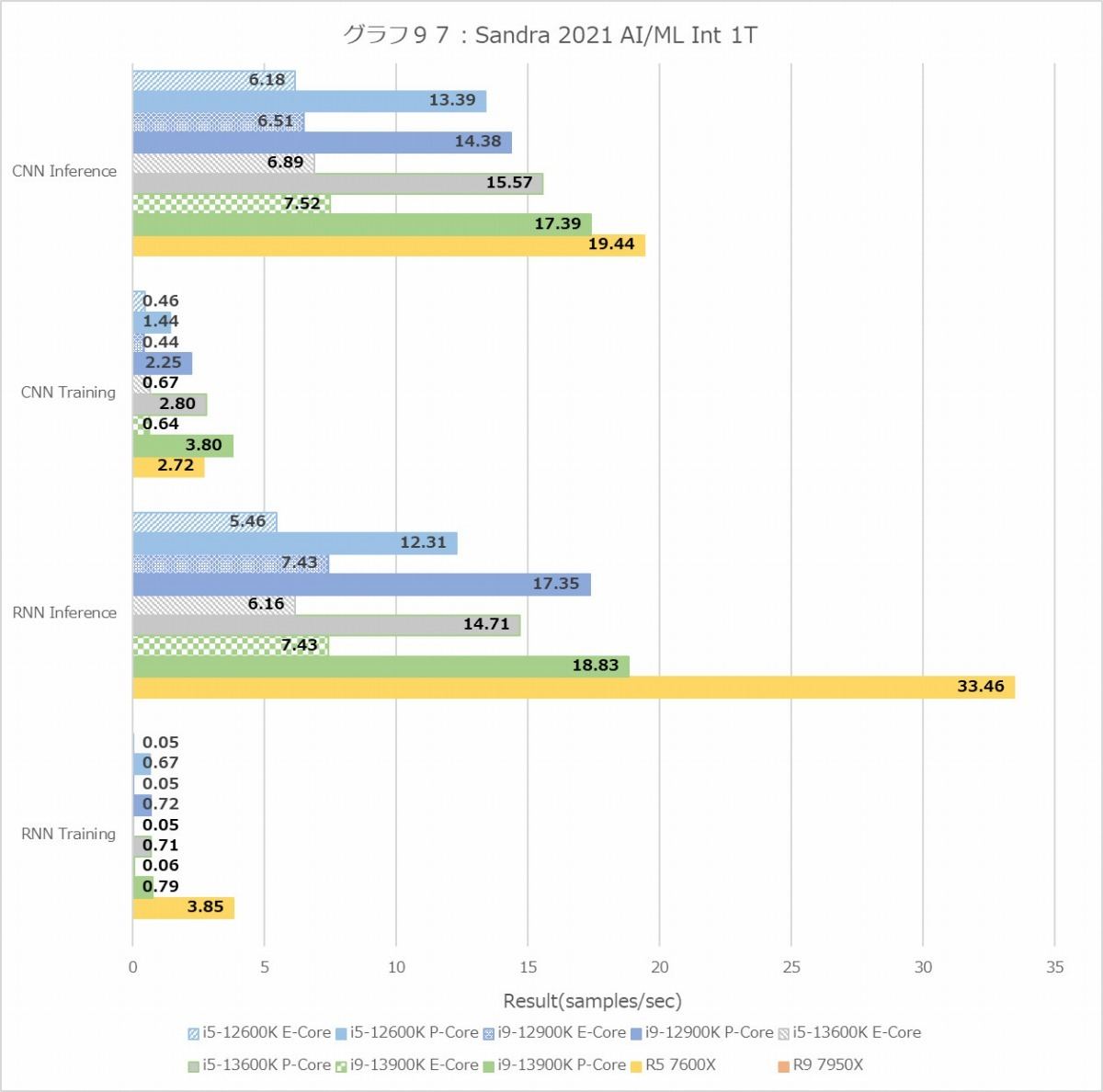
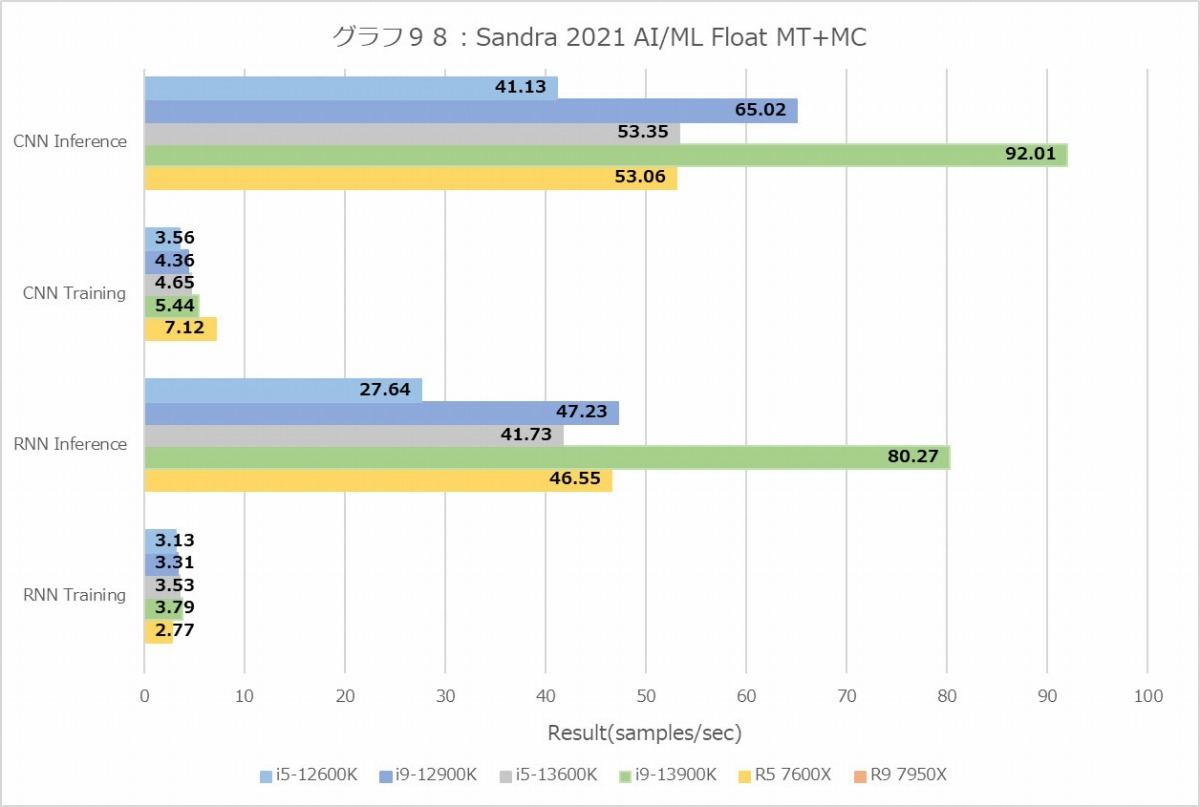
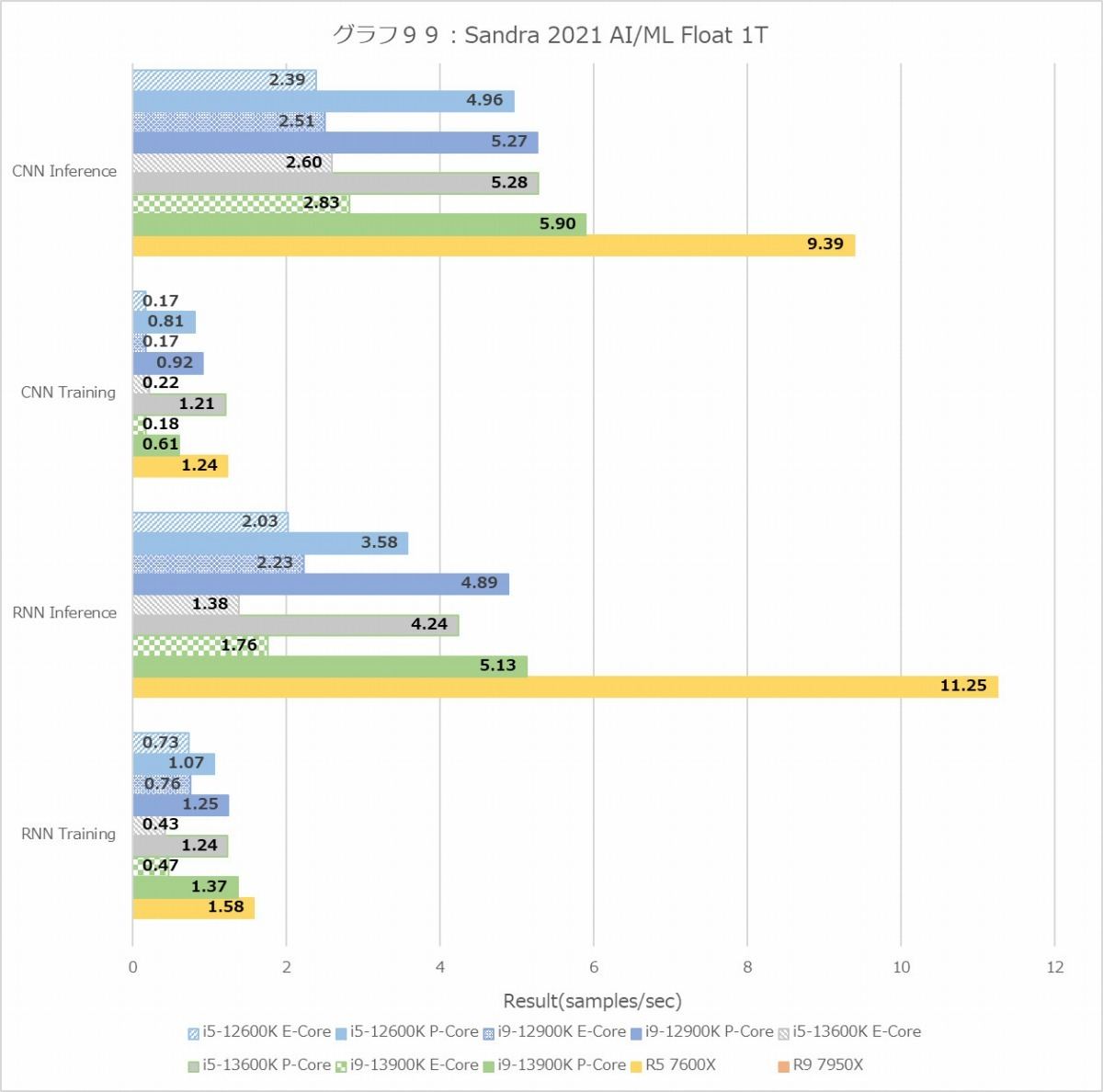
次のAI/ML Training/Inferenceは、なぜかRyzen 9 7950Xのみテストがエラーになってしまうためデータが取れない。なのでこれのみRyzen 9 7950Xを外しての結果となる。まぁこうなると、Core i9-13900Kの無双か? と思ったらこれが面白いことに。IntのMT+MCで、Inferenceは確かにCore i9-13900Kが最高速なのだが、TrainingはRyzen 5 7600Xが最高速と言う結果に。またInferenceでもRNNだとRyzen 5 7600XがCore i9-12900Kを上回る成績を出している。1Tだとこれが顕著で、InferenceでRyzen 5 7600XがCore i9-13900Kを上回る性能である。RNNのTrainingでは、Threadあたりの性能では他を圧倒している。にも拘わらずMT+MCだとそこまで性能が伸びないのは、やはりメモリ帯域がボトルネックになるからというあたりだろうか。
Floatだと性能の出方がまた変わり、MT+MCではやっぱりCore i9-13900Kが最高速だが、Ryzen 5 7600Xの性能も悪くなく、Core i5-13600Kと並ぶ程度。1TだとRyzen 5 7600Xがブッチギリである。つまりコア単体の性能で言えば、Zen 4はGolden CoveやTremontを凌駕するが、メモリアクセス性能で足を引っ張られる結果としてトータルではGolden Goveがやや有利、というあたりだろうか。Ryzen 9 7950Xがもし正常に動作したら、L3が64MBという事になる訳で、このあたりどういう性能になったのか興味深いところで、テストが動作しなかったのが本当に残念である。
-
グラフ100

-
グラフ101

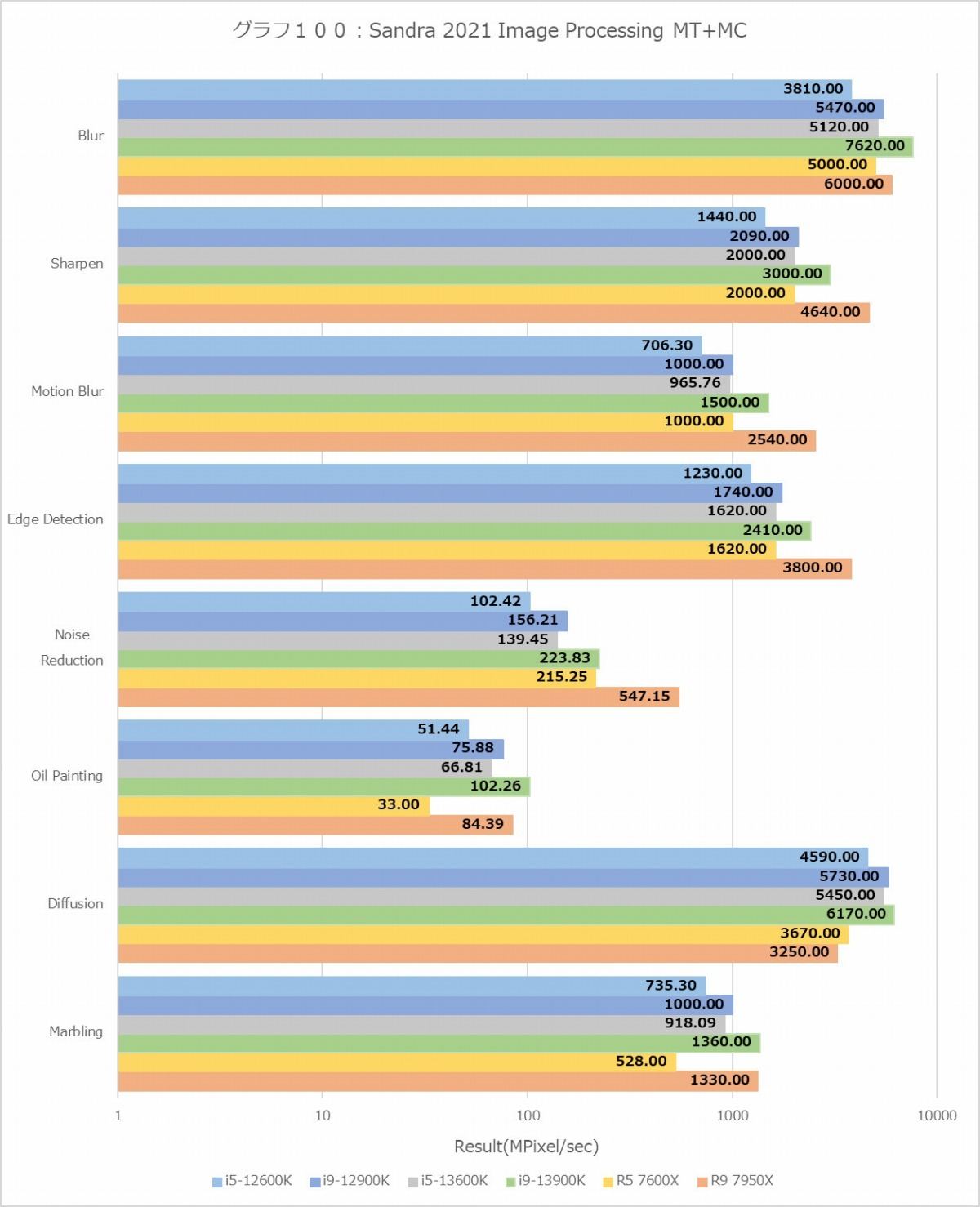
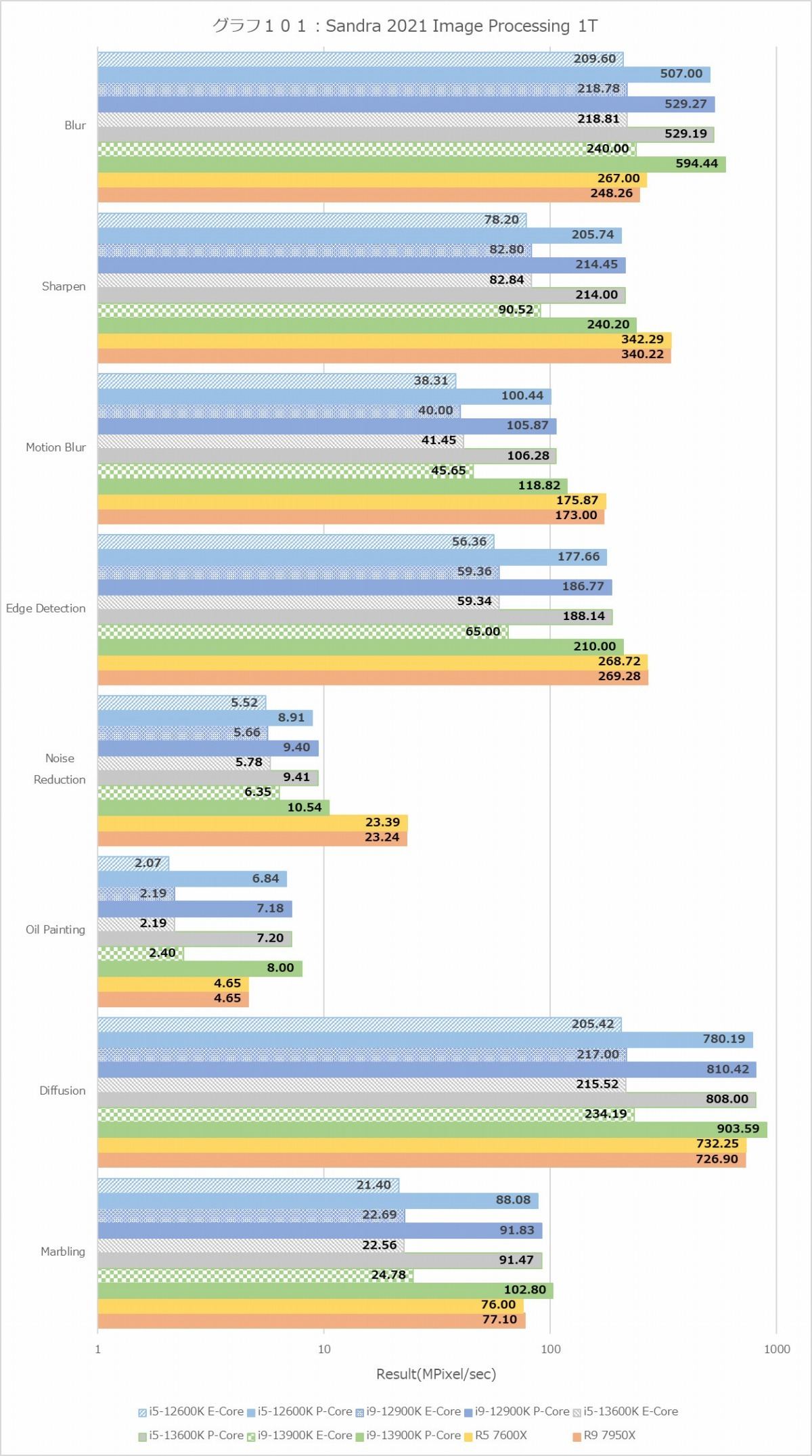
グラフ100・101はImage Processingの結果である。先のProcessor Multimedia同様に横軸は対数グラフになっているので注意されたい。項目によって性能のバラつきがかなりあるため、一概にどれが最高速かは比較しにくいのだが、MT+MCのケースでCore i5-12600Kのスコアを100とした場合のそれぞれのテストの結果の平均値をとると
| Core i5-12600K | 100.0 |
|---|---|
| Core i9-12900K | 141.6 |
| Core i5-13600K | 131.4 |
| Core i9-13900K | 194.2 |
| Ryzen 5 7600X | 121.2 |
| Ryzen 9 7950X | 262.3 |
という事になって、トータルで言えばRyzen 9 7950Xが最高速で次点がCore i9-13900K、ついでCore i9-12900Kという順だ。同様に1TでCore i5-12600KのE-Coreを100とした場合では
| Core i5-12600K E-Core | 100.0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Core i5-12600K P-Core | 295.7 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Core i9-12900K E-Core | 105.0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Core i9-12900K P-Core | 309.4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Core i5-13600K E-Core | 105.6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Core i5-13600K P-Core | 309.6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Core i9-13900K E-Core | 115.7 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Core i9-13900K P-Core | 346.4 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ryzen 5 7600X | 6 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ryzen 9 7950X | 3 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ということになり、動作周波数の差を考えてもZen 4コアが最高速であり、Golden Coveはやや及ばない程度になる。
-
グラフ102

-
グラフ103

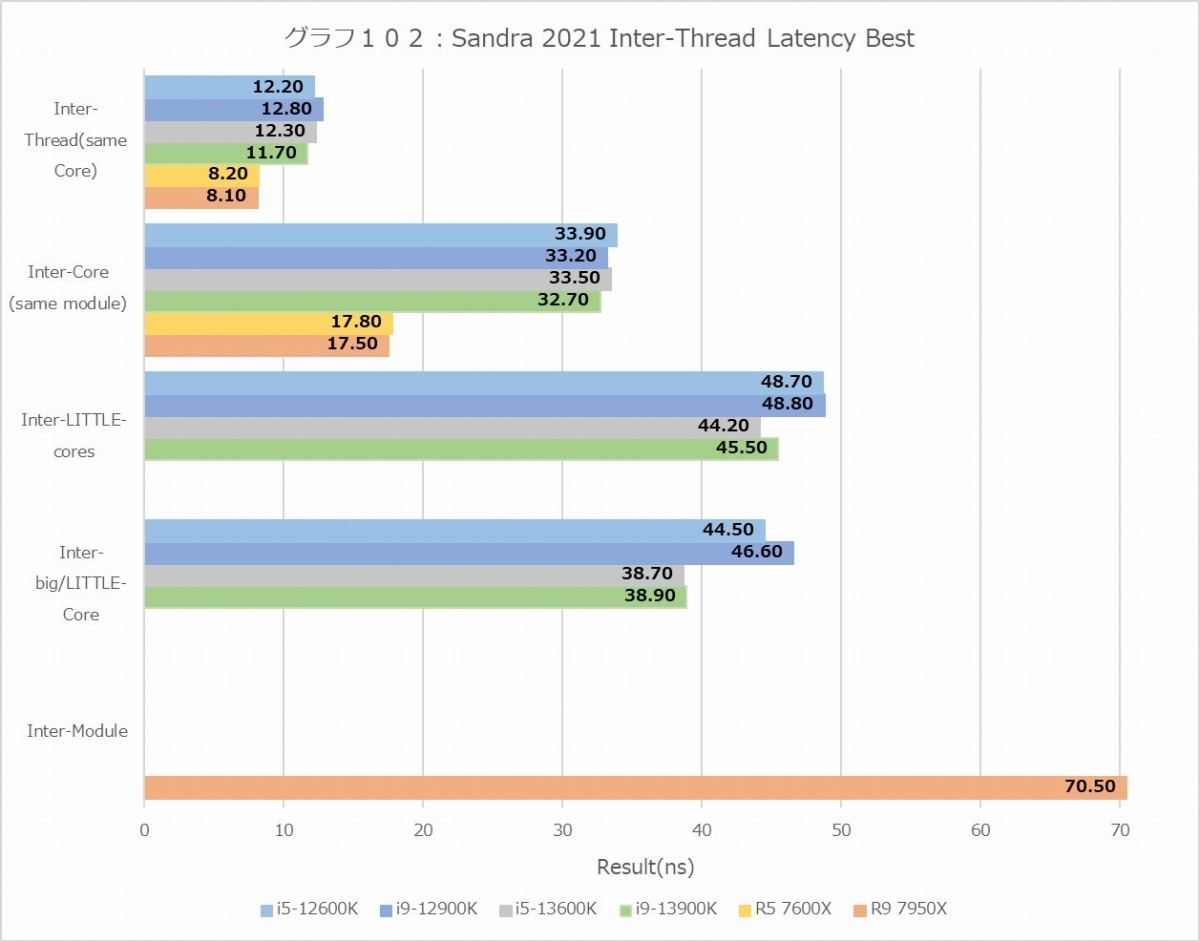
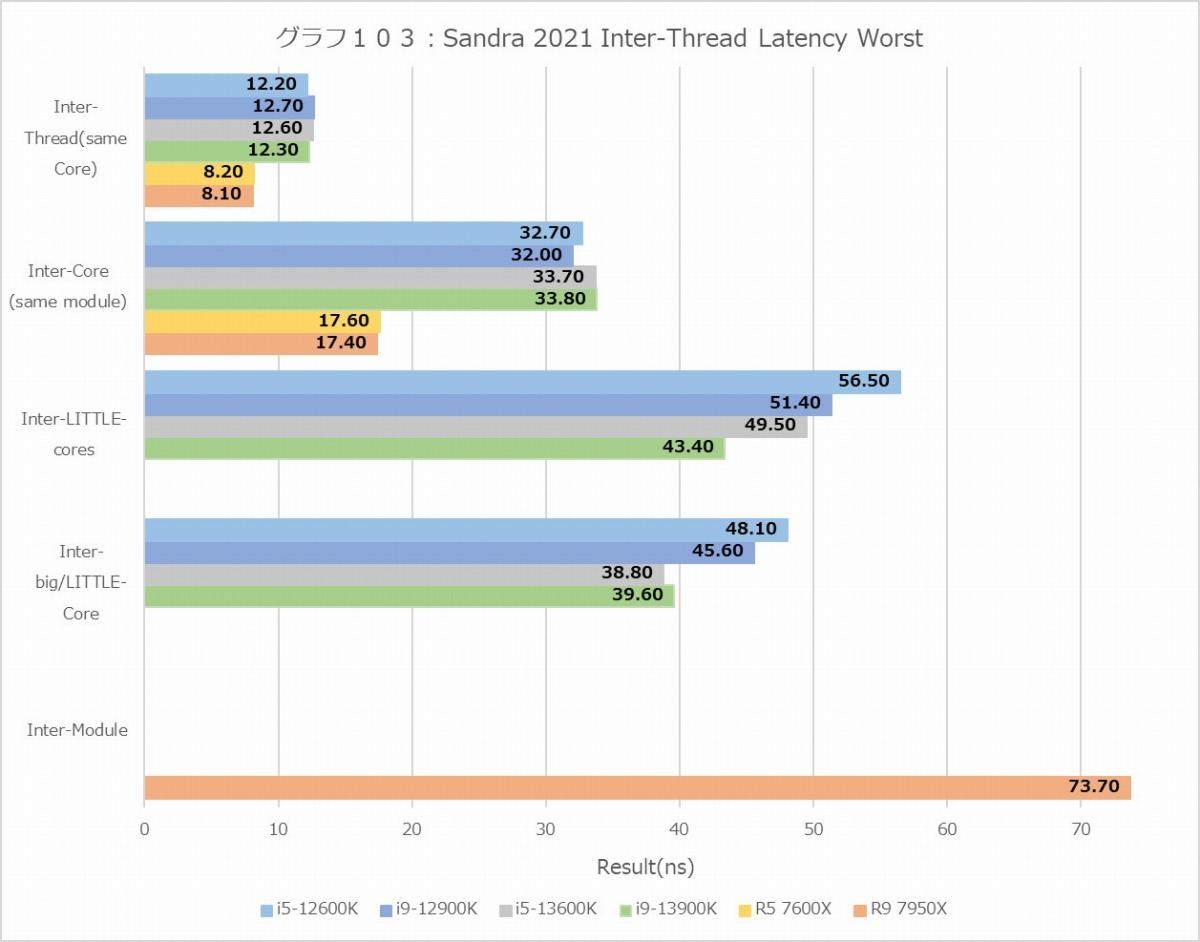
さてここからはコア周辺の話になる。まずはInter-Thread Latency&Bandwidth(グラフ102~107)。まずInter-Thread Latencyを見ると、BestとWorstのどちらも意外にAlder Lake/Raptor Lakeが大きいのが気になる。勿論絶対値と言う意味ではRyzen 9 7950XのCCD間のLatencyが一番デカいのだが、同一ダイの中のE-Core同士とかE-CoreとP-Coreの通信が40ns台というのはちょっと解せない。Raptor Lakeで多少高速化はしているが、これは内部の転送速度が上がったのが理由で、何かLatencyを削減するためのメカニズムが入った訳ではない。逆に言えば、1 CCD構成のRyzen 5 7600Xが文句なくLatencyは一番低いあたりは、ちょっとAlder Lake/Raptor Lakeの構成には問題を感じる。まぁ理由は明白で、P-Coreは1コア単位でInterconnectと接続しているが、E-Coreは4コアのClusterの形で実装されており、InterconnectはこのClusterが接続される形だ。だから、同一Cluster内の通信はともかく、異なるCluster間だとCluster内→Inter Cluster→Cluster内という、余分にLatencyが掛かる構成になるためだ。
-
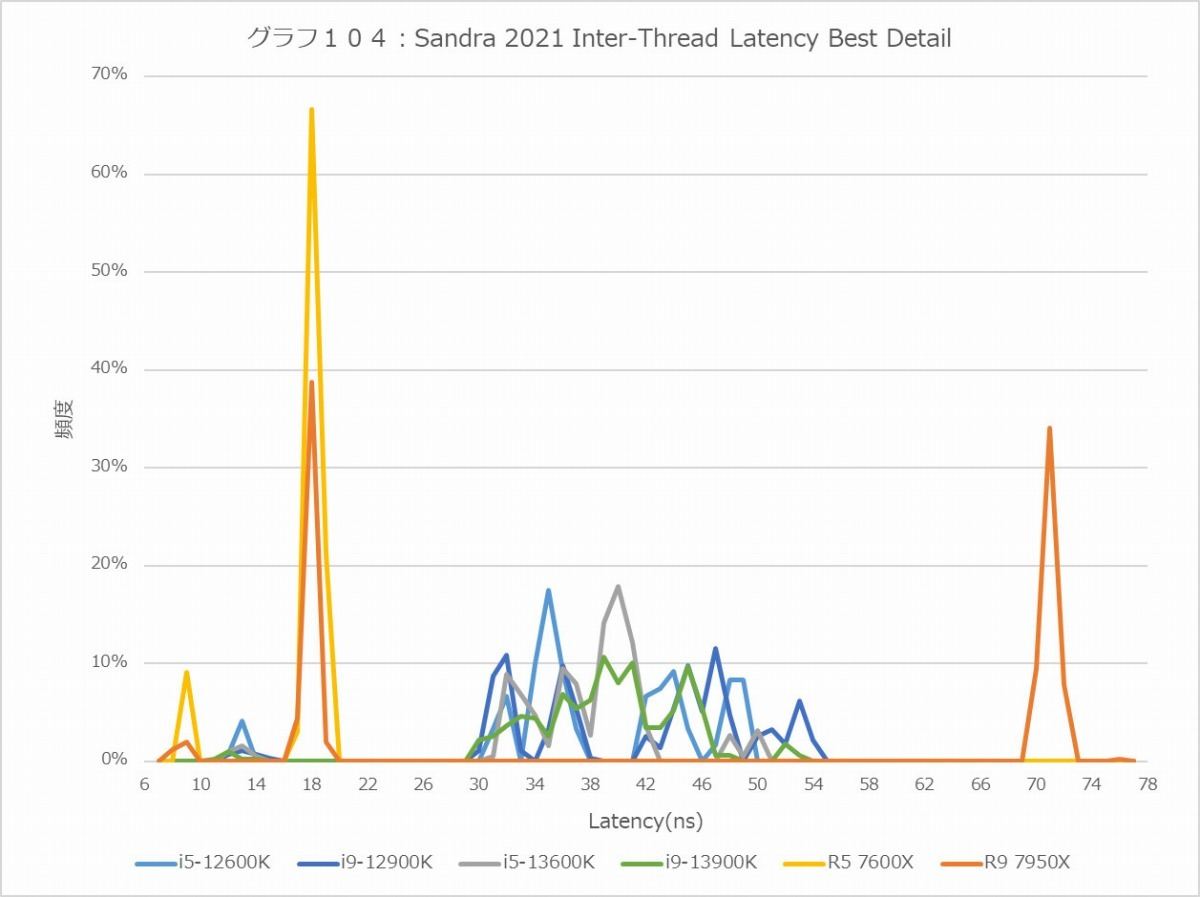
グラフ104

-
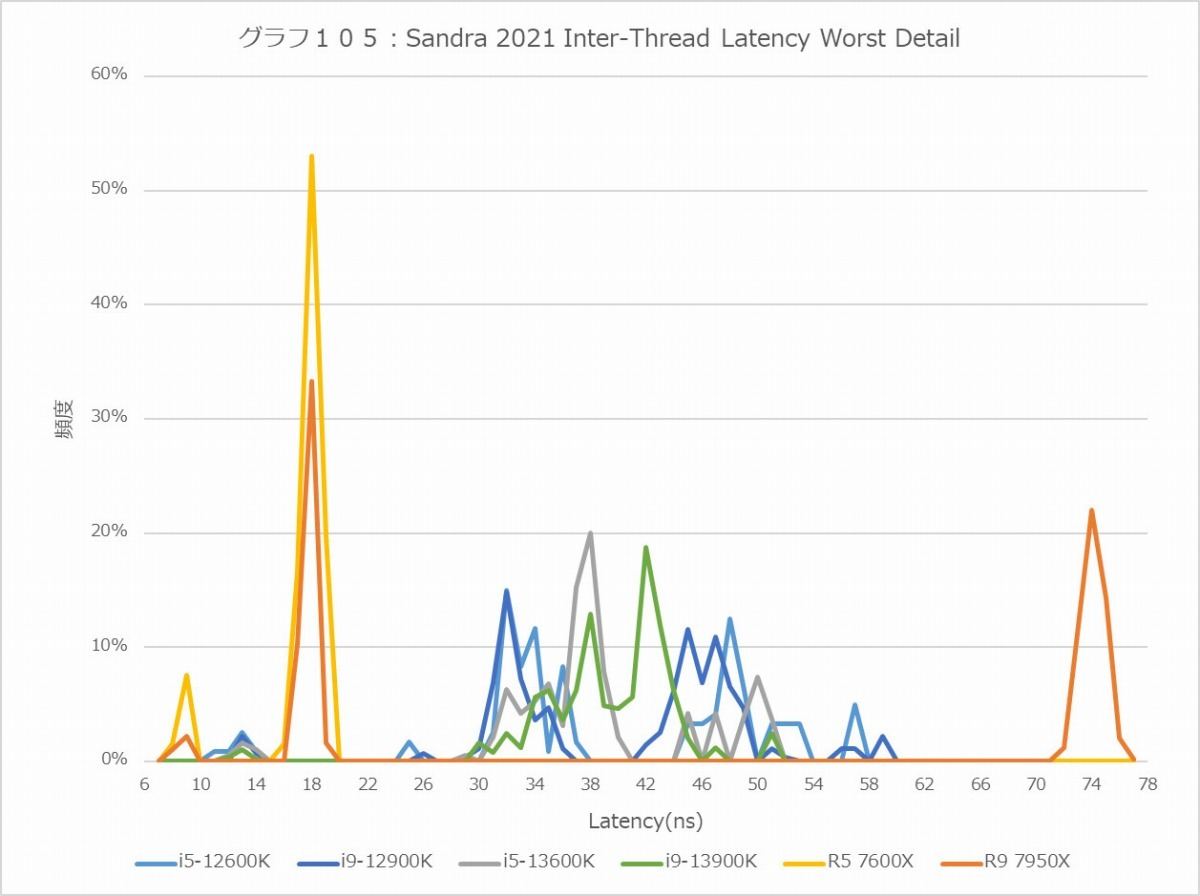
グラフ105

実際、Latencyの頻度分布(グラフ104~105)を見ると、Inter-Thread及びInter-Coreはそれほどバラつきがないが、E-CoreとP-Core間の通信は30ns~54nsでかなりばらつきが見られる。E-CoreのClusterを排除すればこのあたりはもう少し落ち着くだろうが、今度はInterconnectが大変な事になる(Ring BusのRing Stopが大幅に増える)から、あまりうまい案ではない。Hybrid構成では避けられないペナルティと考えるべきなのだろう。
-

グラフ106

-
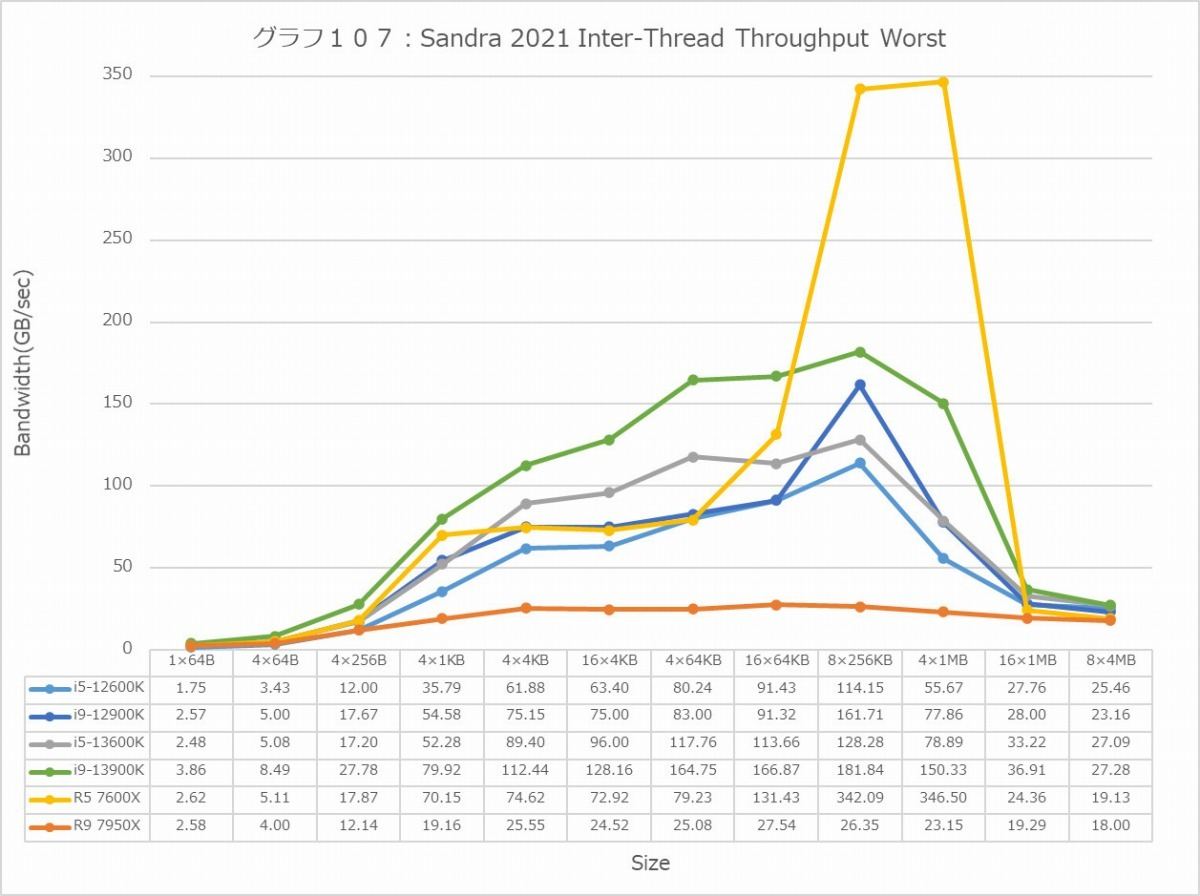
グラフ107

では帯域は? というと、これもなかなか面白い。これまでInter-Thread BandwidthはIntel系が常に上位に来ていたのだが、BestではRyzen 9 7950X、WorstではRyzen 5 7600Xがそれぞれピーク性能を記録するという、これまでに無い傾向が見えている。一つ理由として考えられるのは、Zen 3からCCXが8コアに増強されており、なのでCCXを跨ぐ際のLatencyが削減されているという事だろうか?
-

グラフ108

-
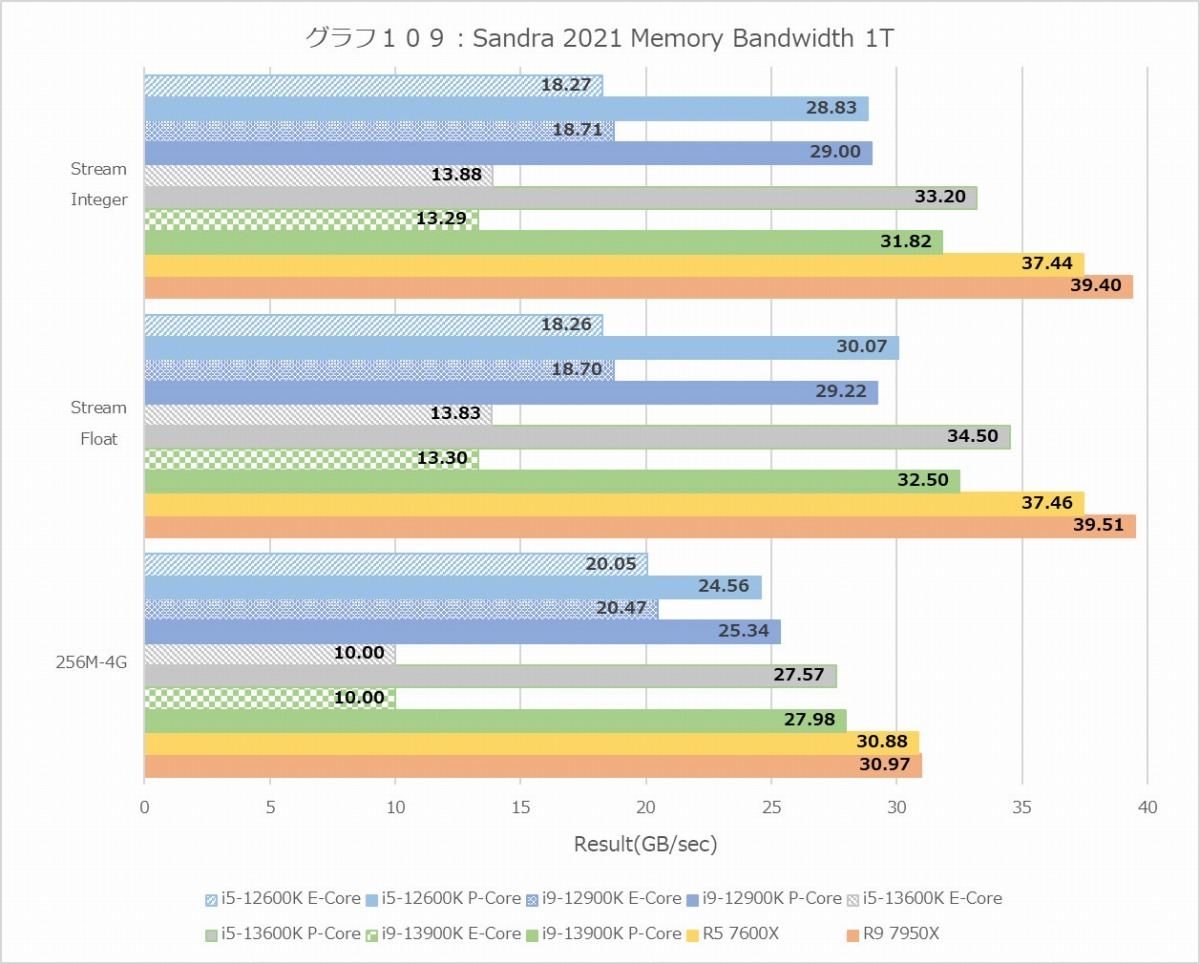
グラフ109

次がMemory Bandwidth(グラフ108~109)。MT+MCのケースだとZen 4が奮わず、一方でRaptor LakeはAlder Lakeを大きくしのぐが、前者は先にRMMTの結果で示したようにZen 4は2 Thread位が一番効率が良く、全Threadアクセスにすると性能が落ちるから。後者は利用しているメモリ(DDR5-4800 vs DDR5-5600)の違いであり、数字そのものには不思議はない。実際1TにするとZen 4はRaptor Lakeを大きく凌ぐメモリアクセス性能を示す。またTremontコアのメモリアクセス性能はGolden Coveの半分強といったあたり。コアの性能を考えれば丁度このあたりでマッチしていると言える。
-
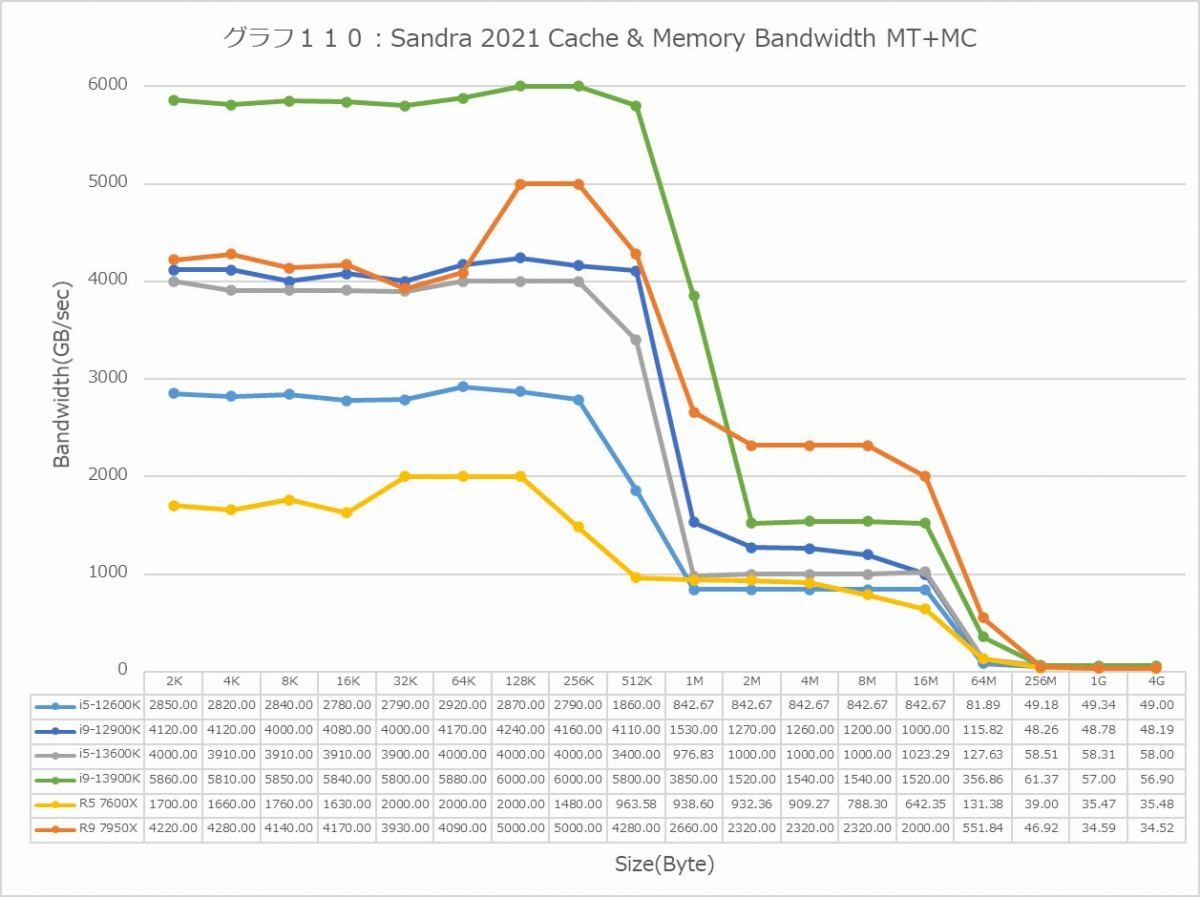
グラフ110

-
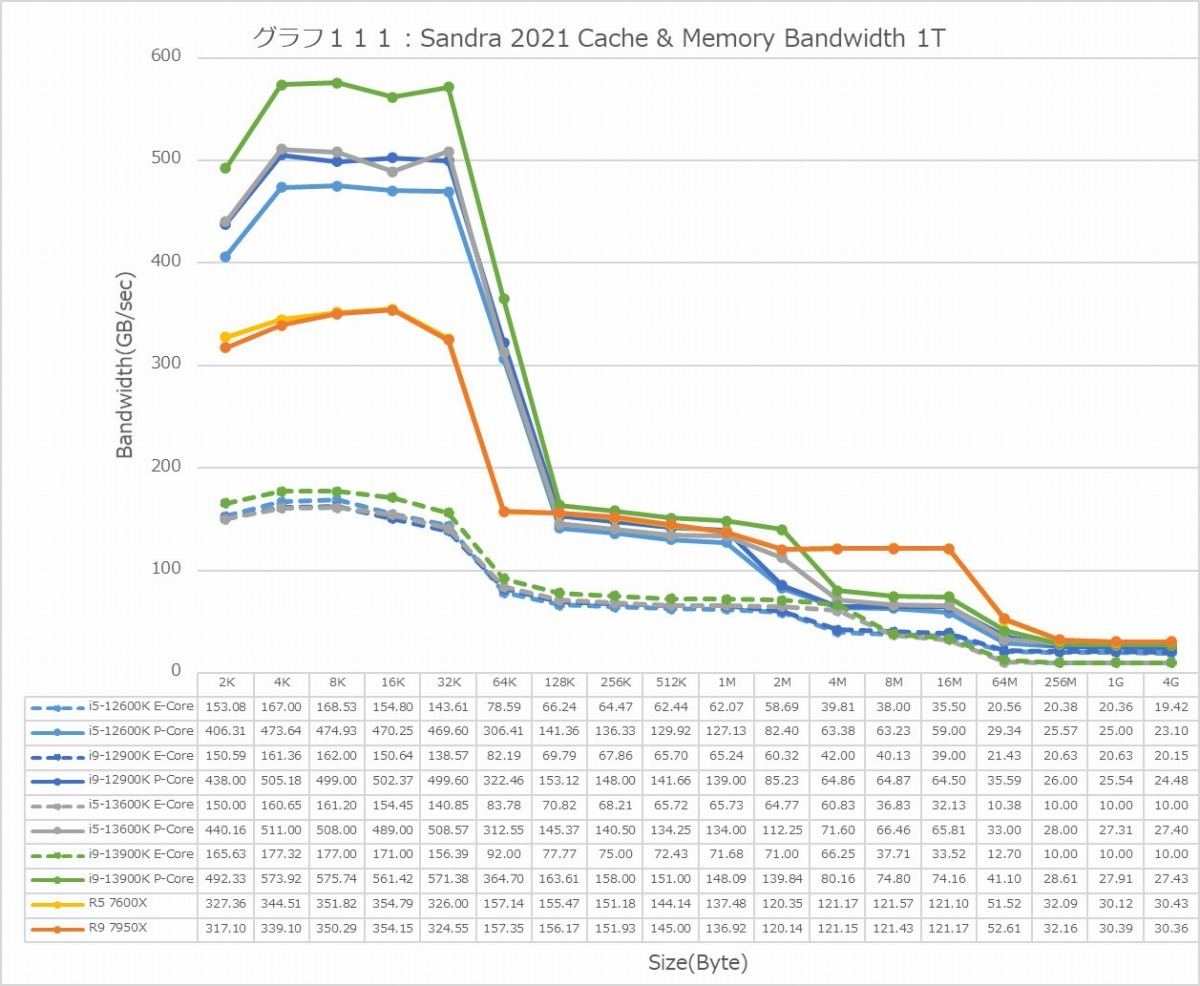
グラフ111

Cache & Memory Bandwidth(グラフ110・111)は主にコアの動作周波数に依存する訳で、ほぼその結果がそのまま反映された格好である。Core i9-13600KのMT+MCにおけるL2までの帯域がかなり広めになっているのは興味深い。コア数からいって、Ryzen 9 7950Xに比肩するのはちょっと考えにくいからだ。一方1Tはもう性能そのままというべきか。Golden CoveはAVX512を同時に2命令実行可能(Alder Lake/Raptor Lakeでは無効化されている)であり、これに対応したLoad/Storeユニットを搭載している。一方でZen 4は1命令のみであり、Load/Storeユニットは当然これに見合ったものになる。なのでL1の領域でGolden CoveがZen 4の2倍近い性能を叩き出すのは当然の事である。逆にAVX512を考慮していないTremontは、ほぼZen 4の半分のLoad/Storeユニットの能力となっており、これもセオリー通りである。
個人的な感想で言えば、ここまでP-CoreとE-Coreの性能というか素性が違うと、Alder Lakeの様なベーシックなbig.LITTLE方式はともかく、Raptor Lakeで実装された改良型のbig.LITTLE、つまり常にE-Coreもフル回転させるやり方はむしろ効率が悪い気がする。むしろP-Coreを10~12コアにした方がバランスが良いのでは? と思われなくもない。
-
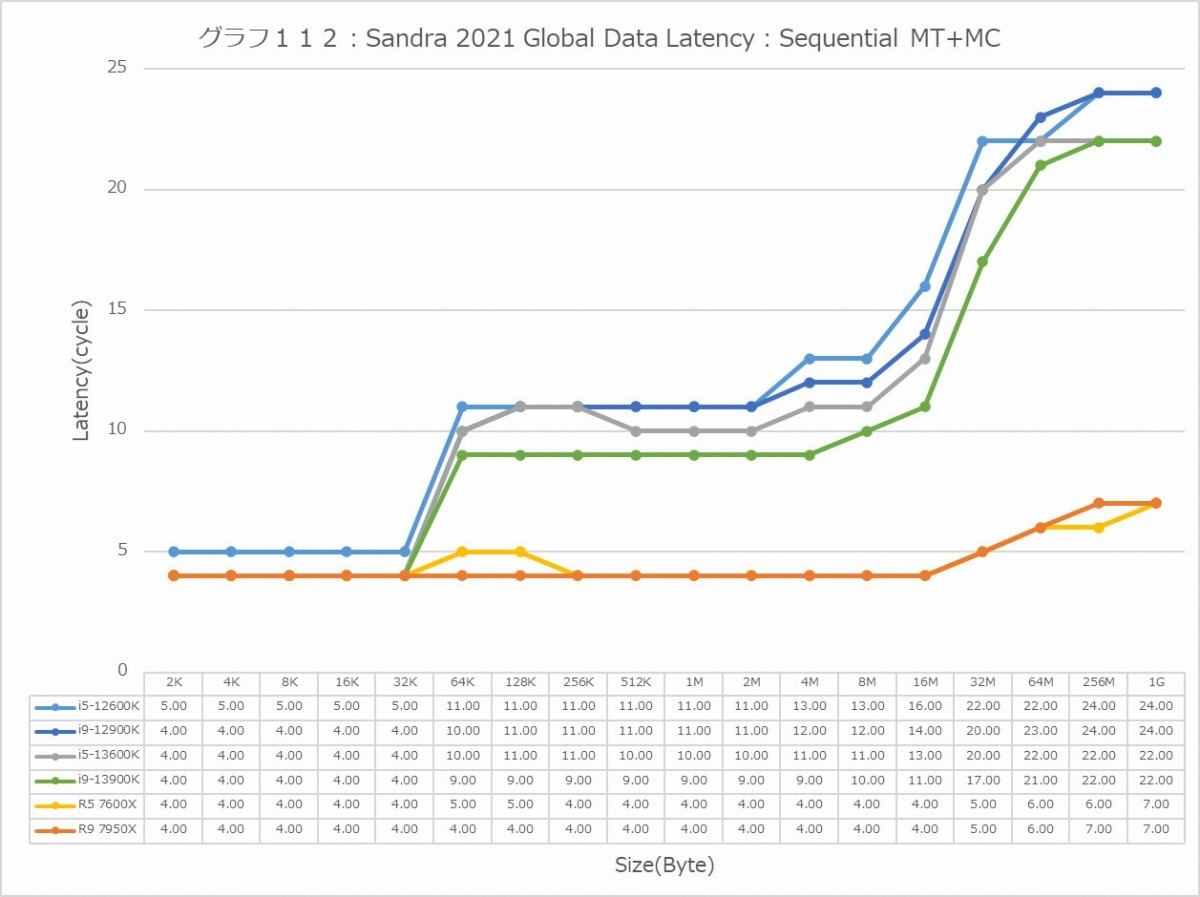
グラフ112

-
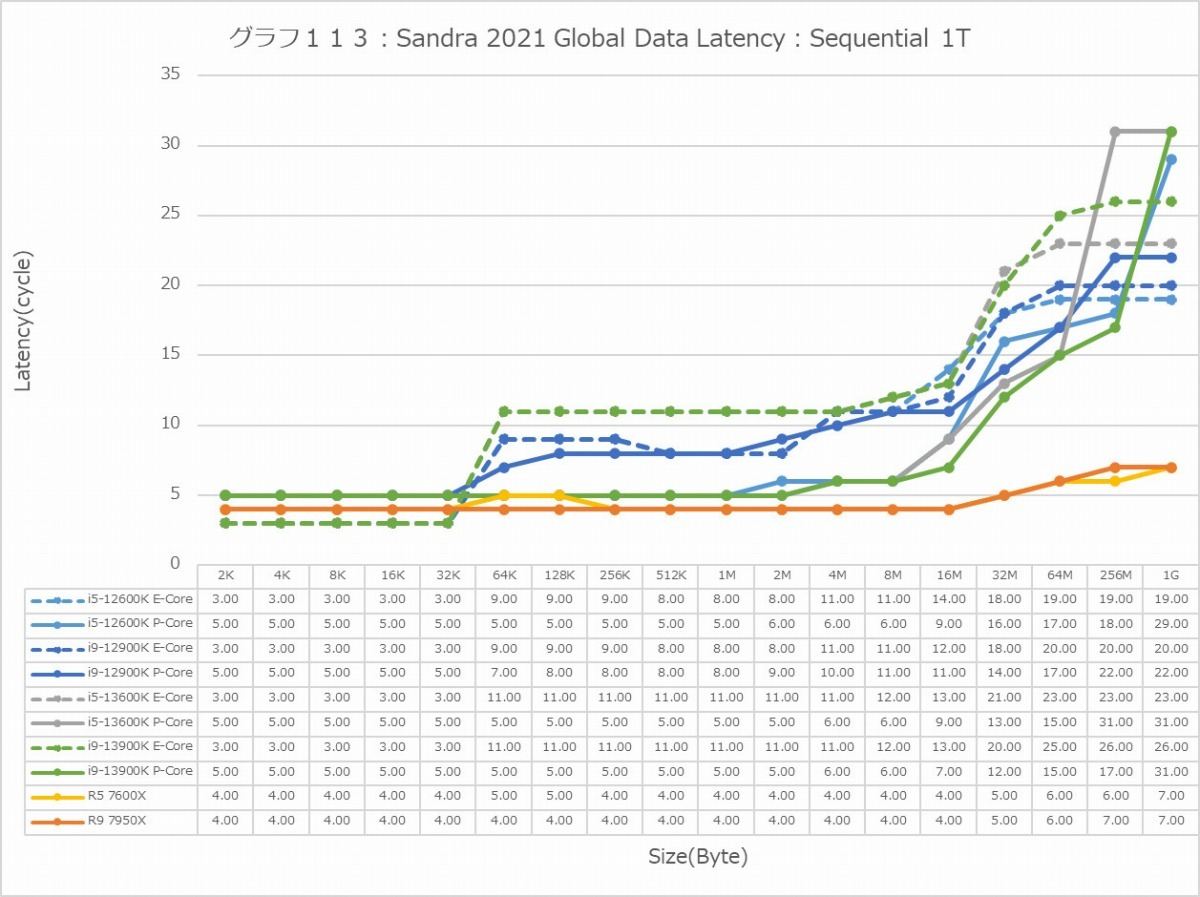
グラフ113

-
グラフ114

-
グラフ115

-
グラフ116

-
グラフ117

-
グラフ118

-
グラフ119

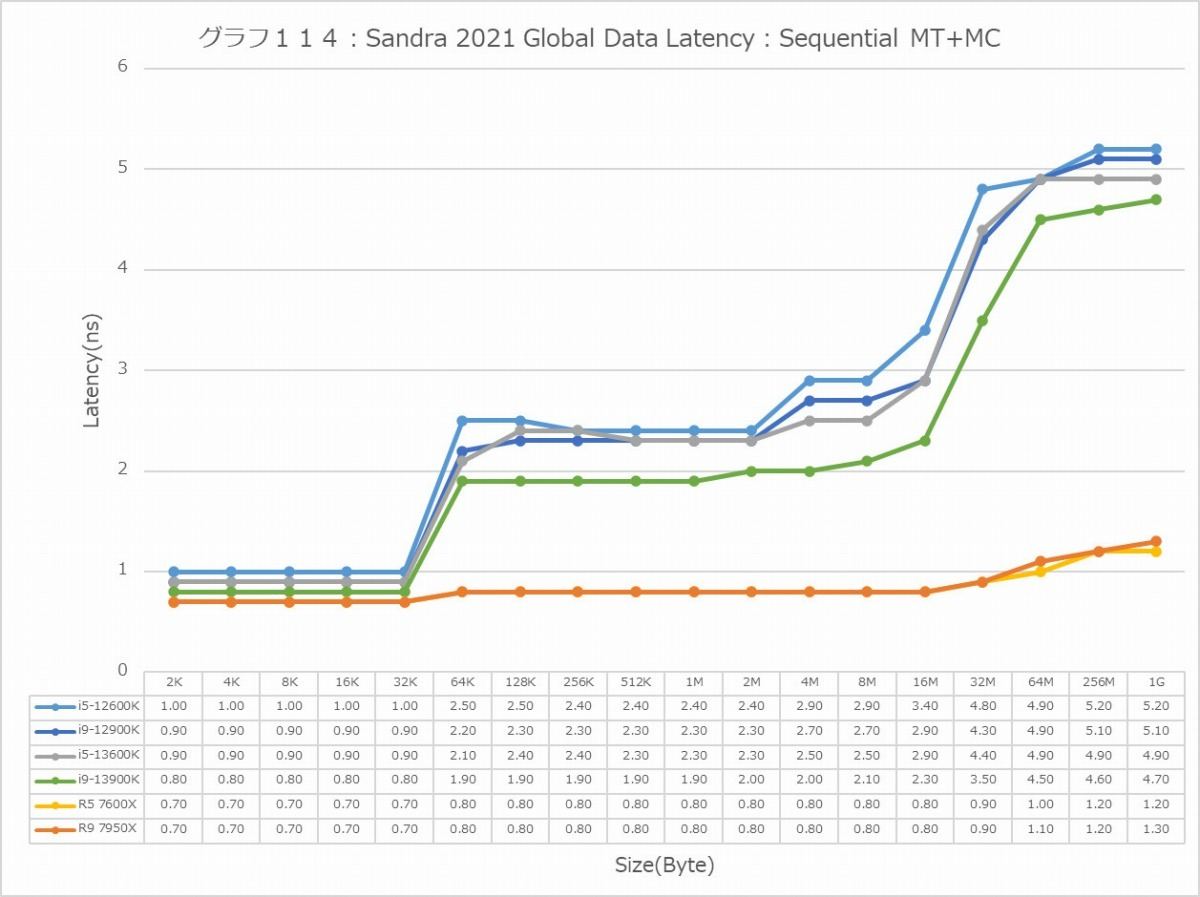
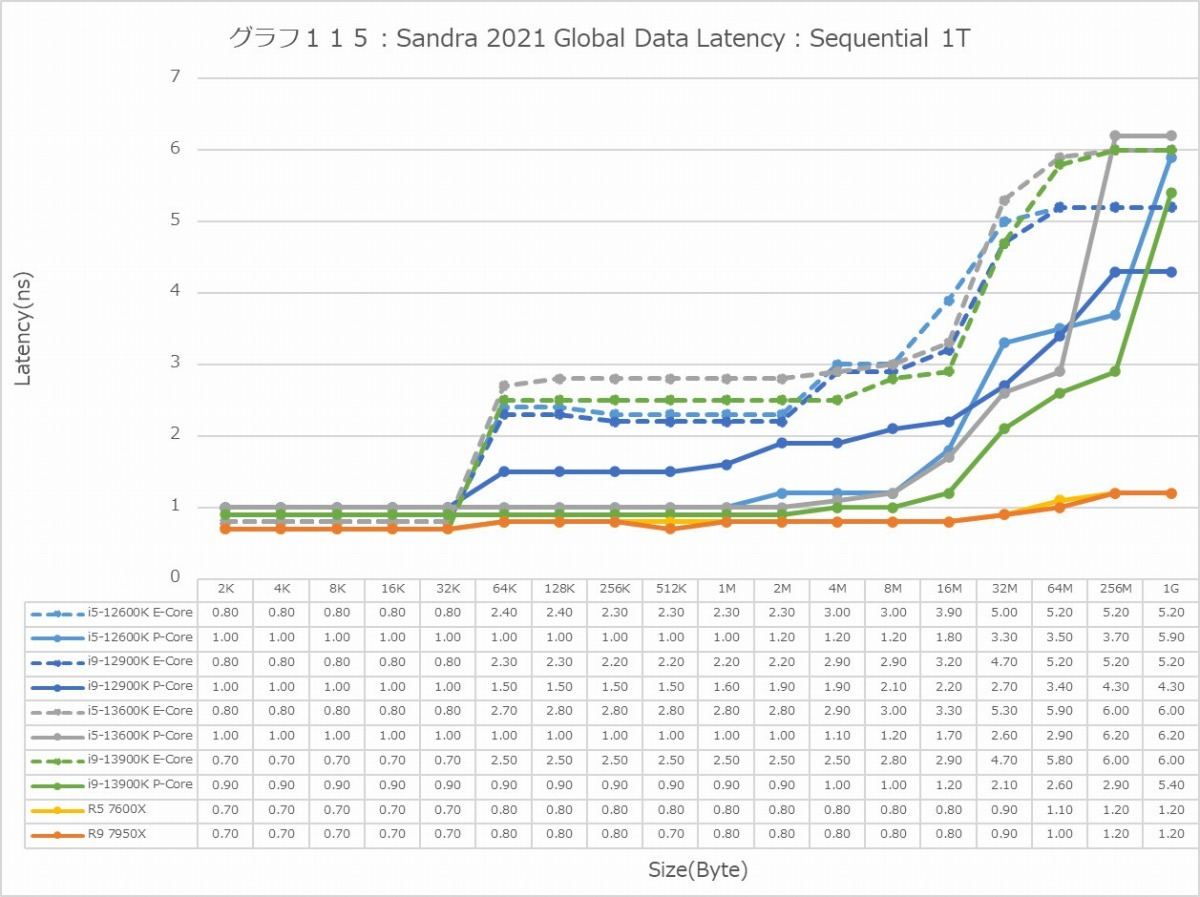
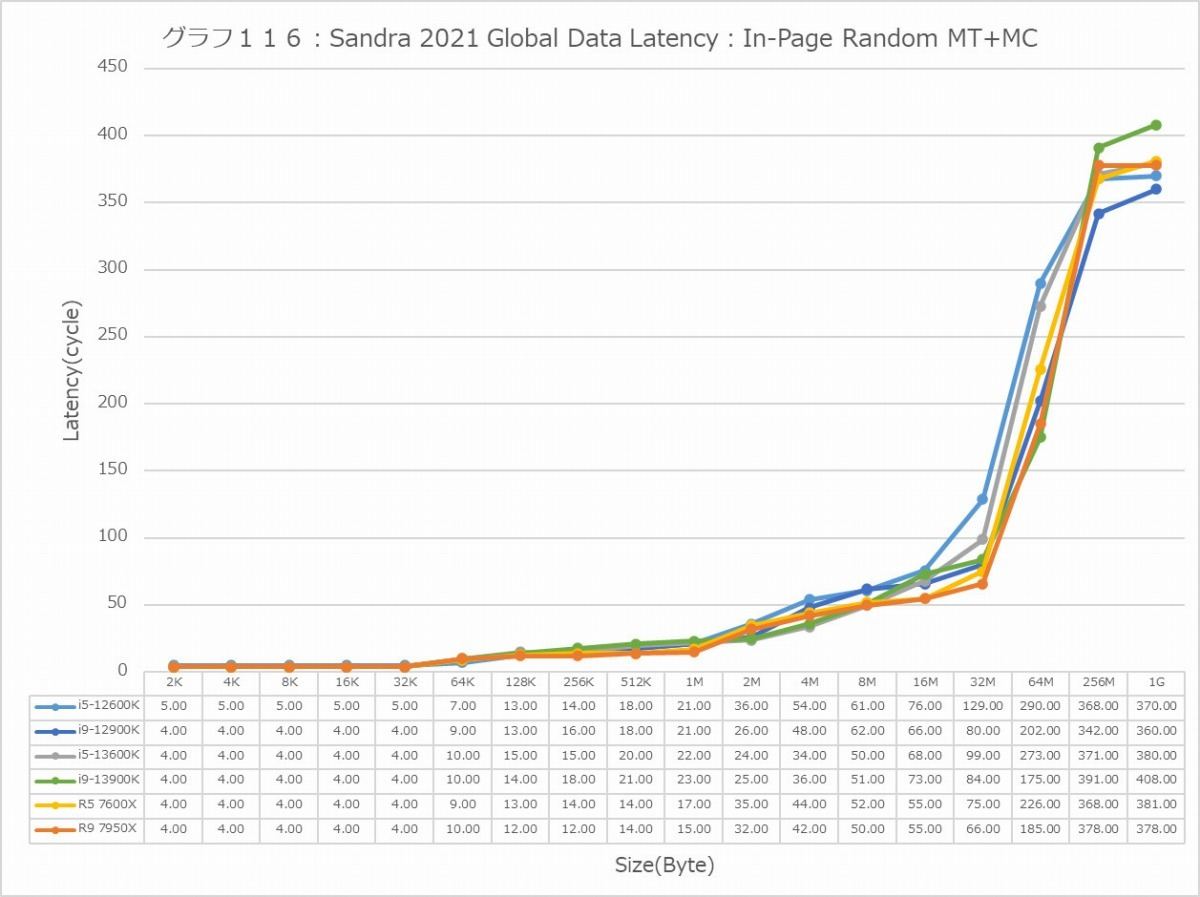
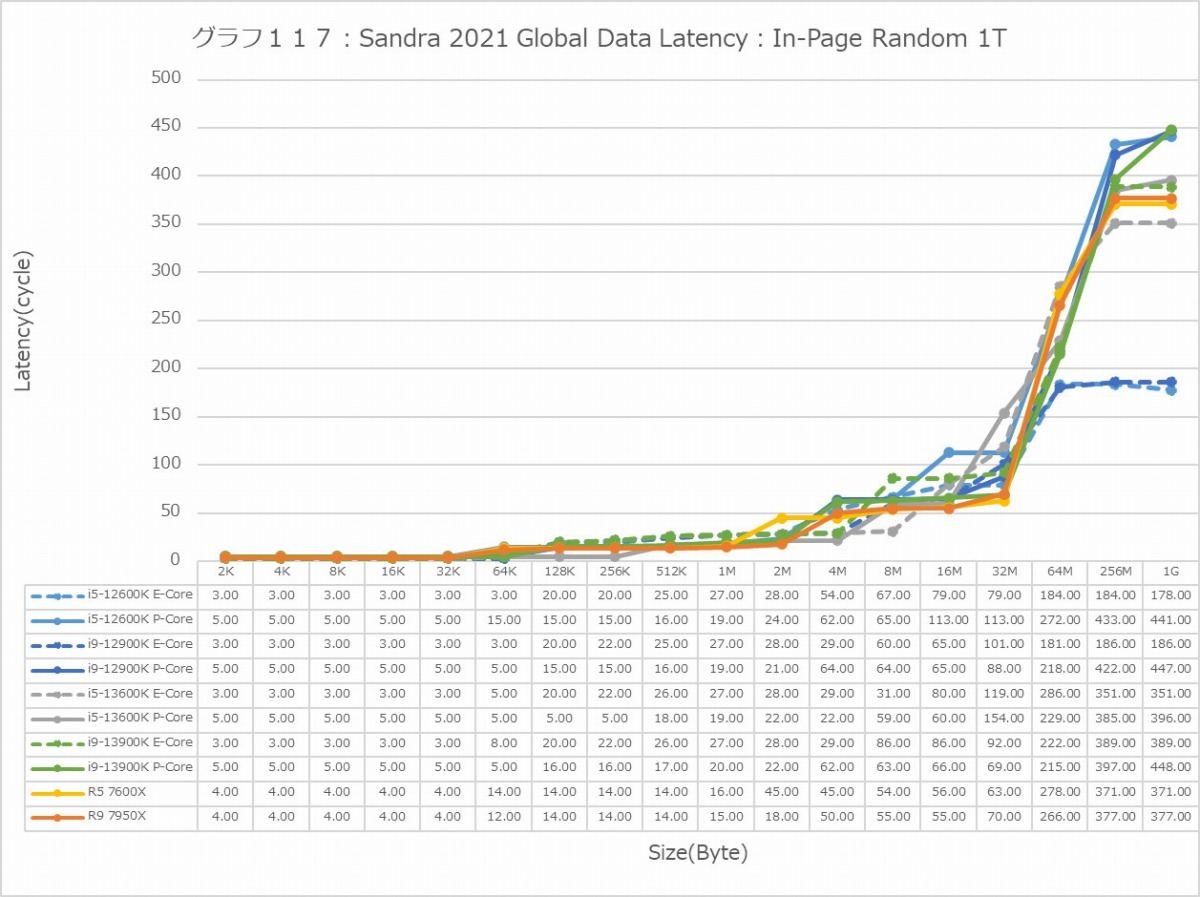
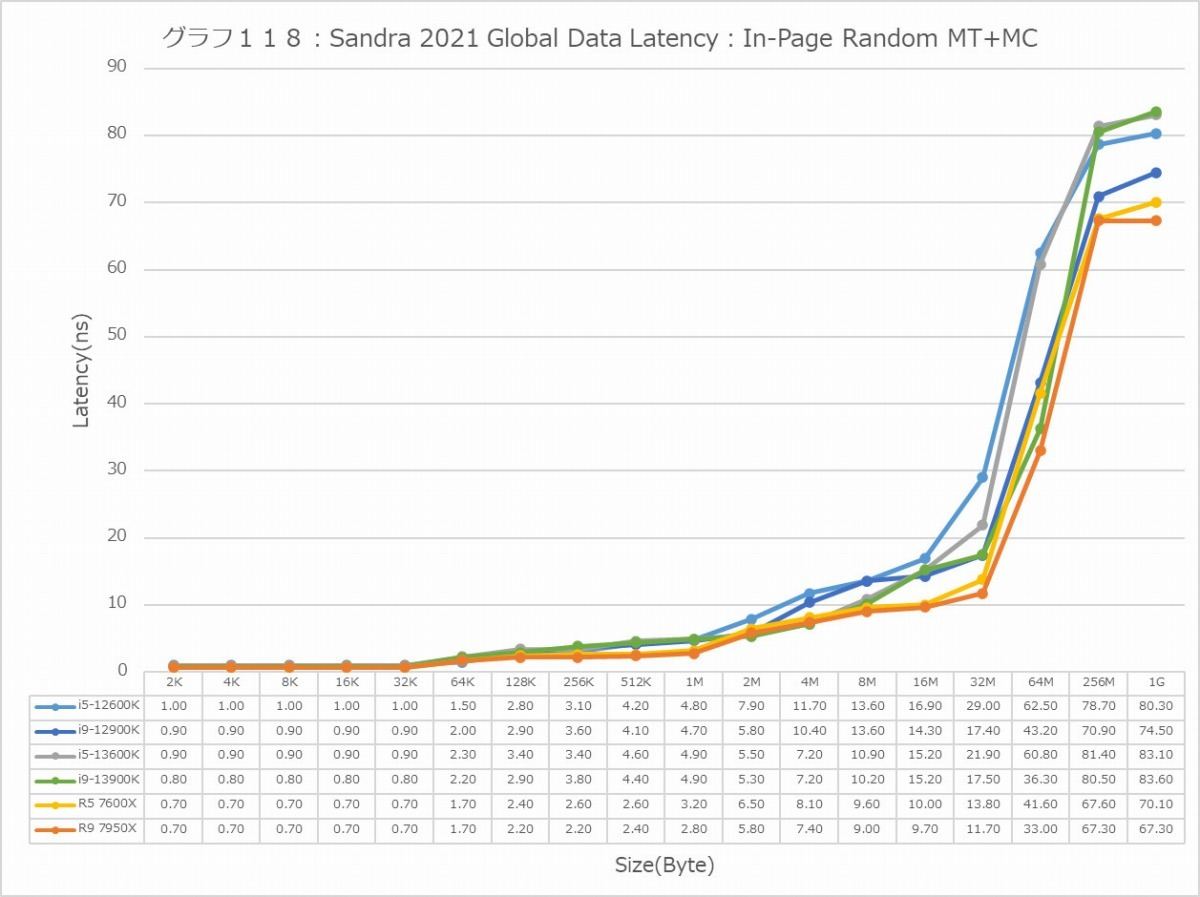
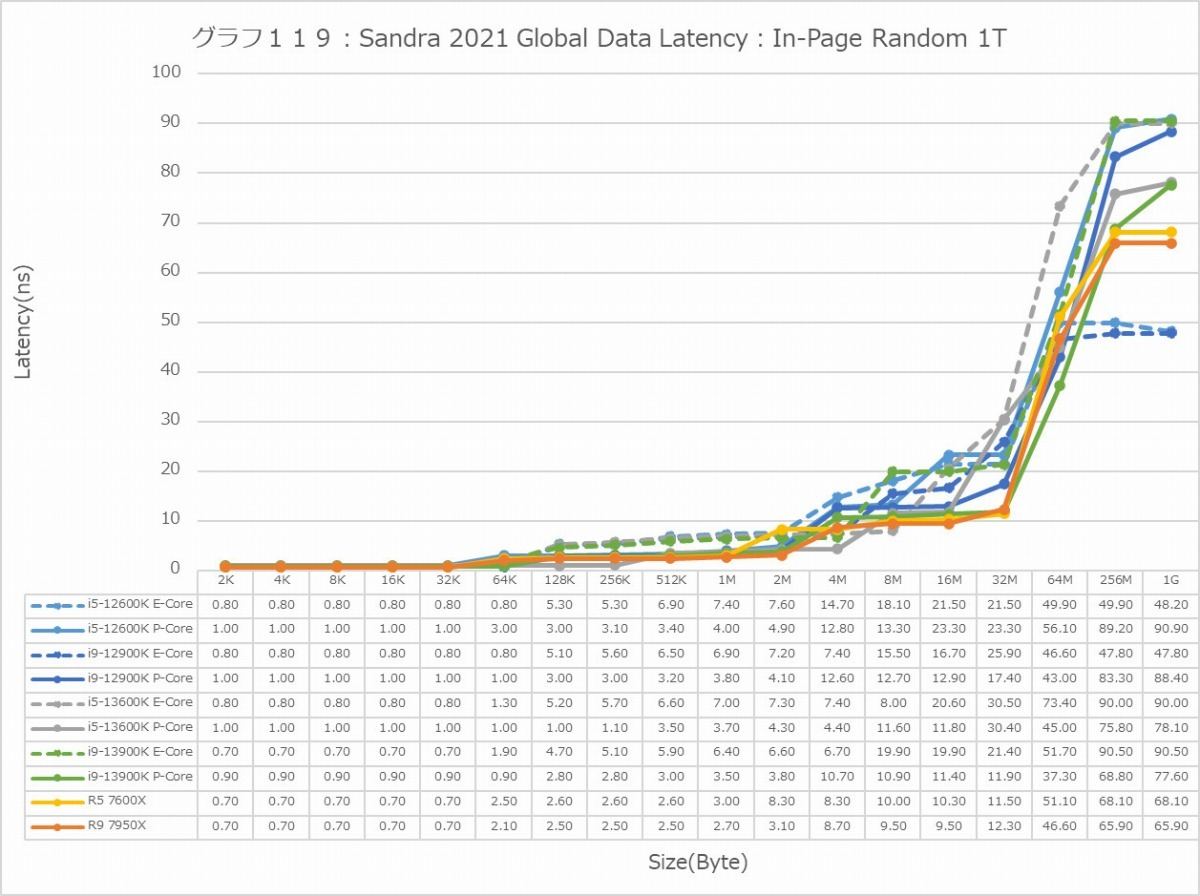
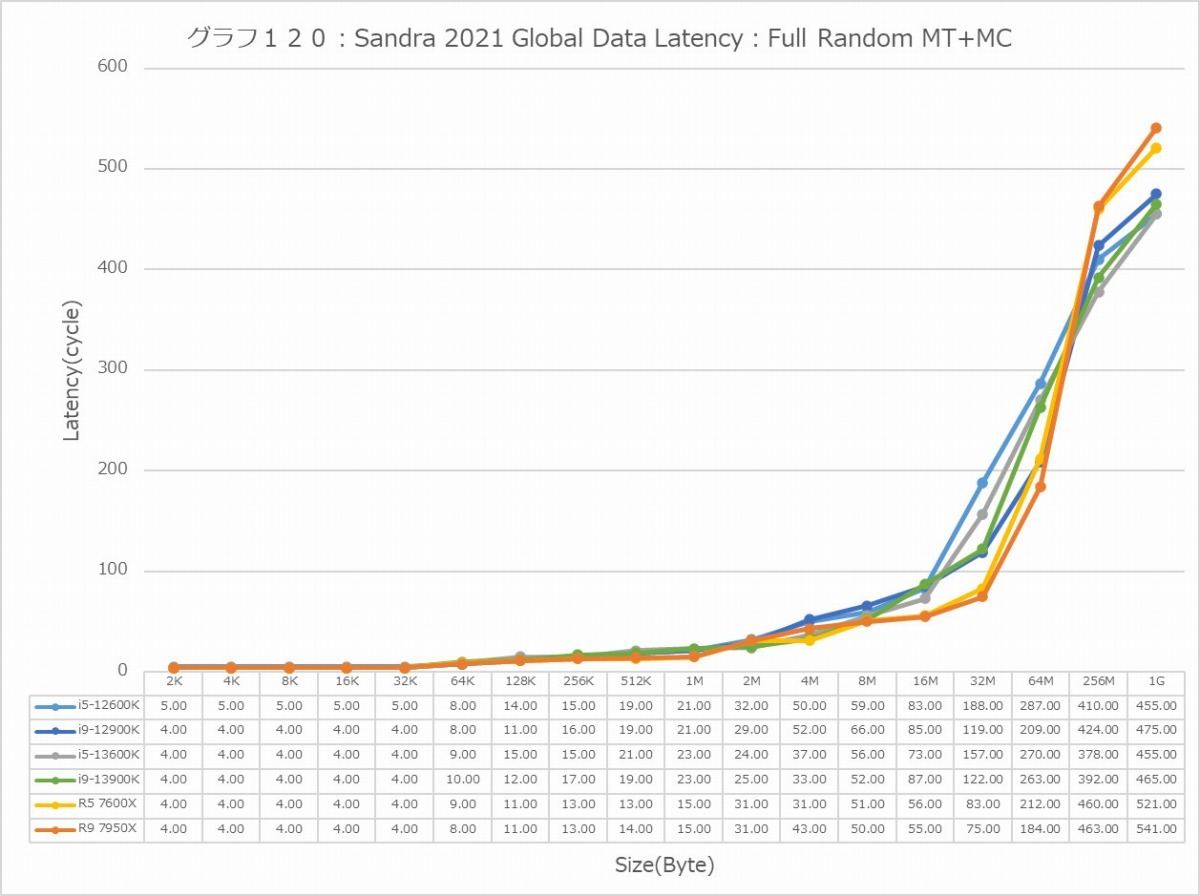
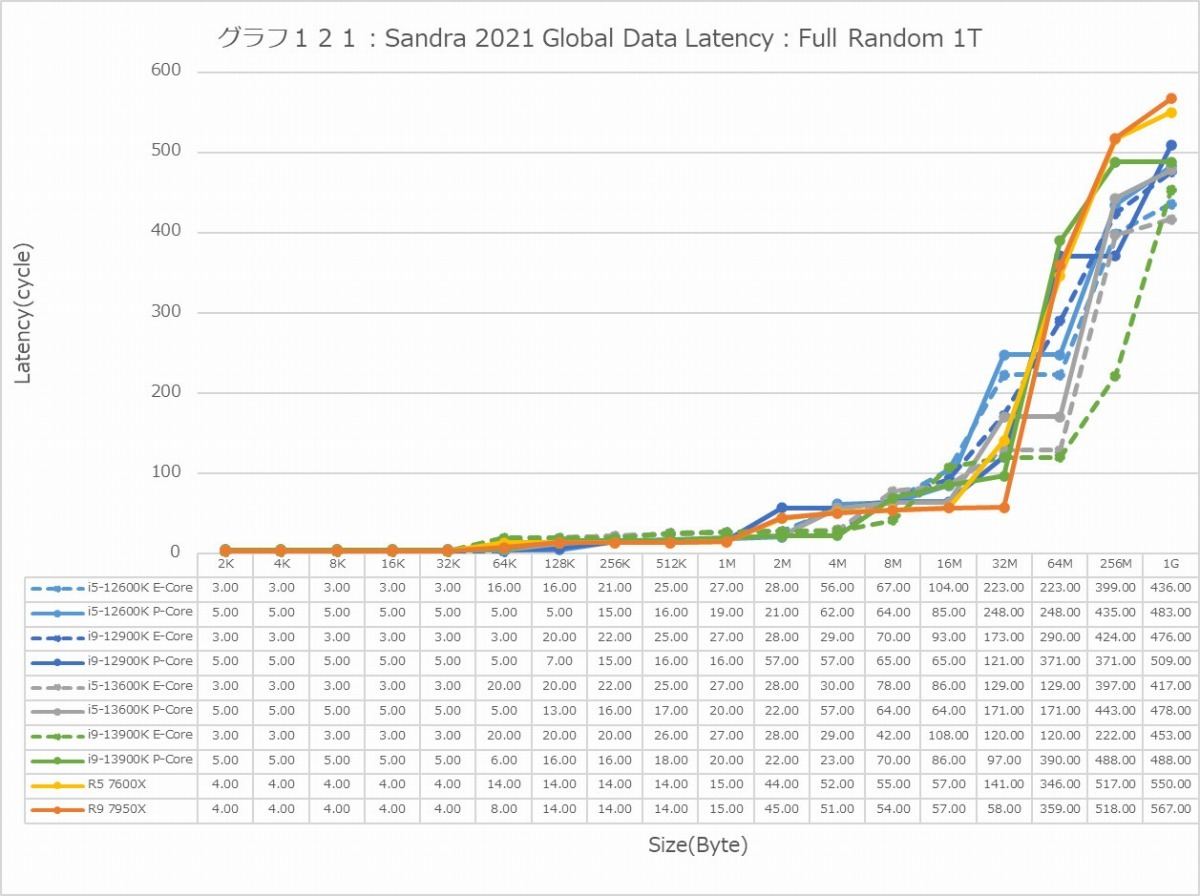
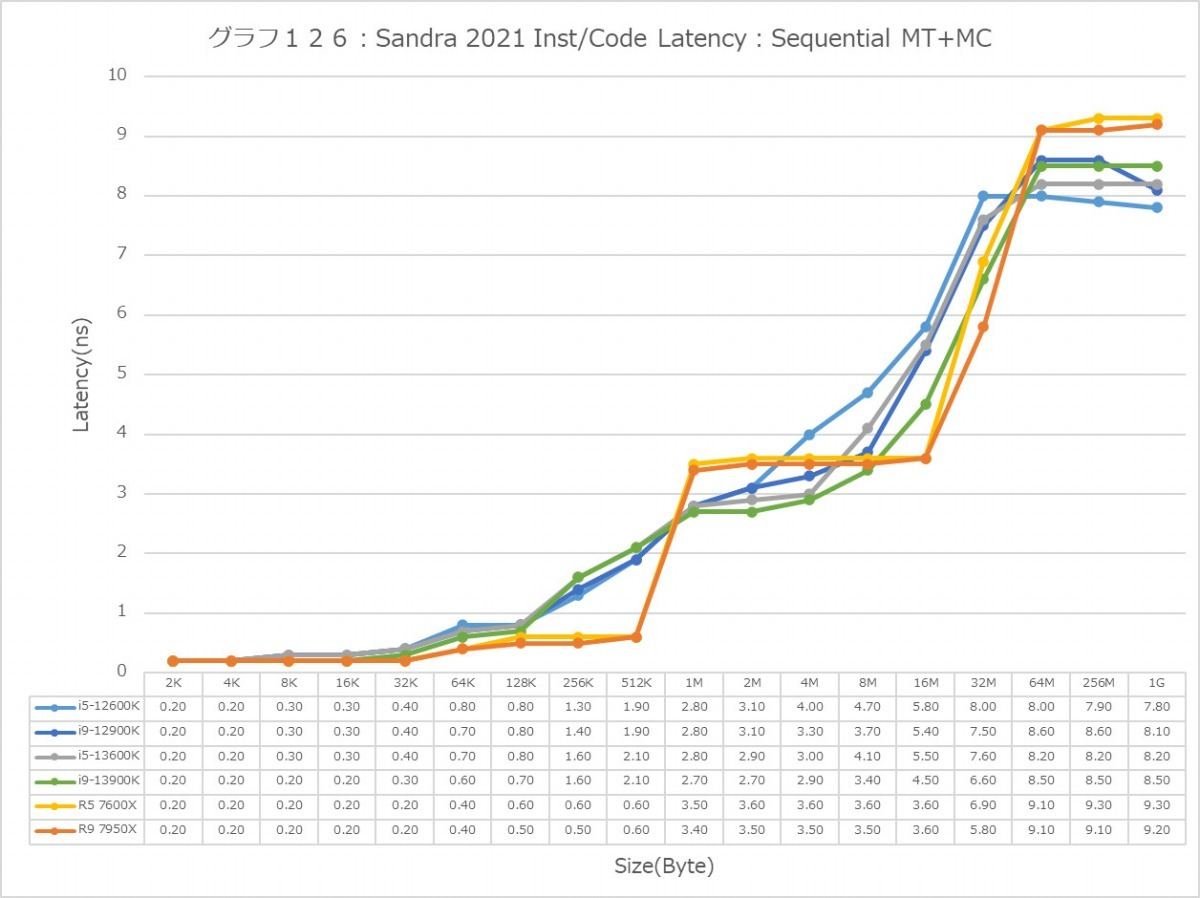
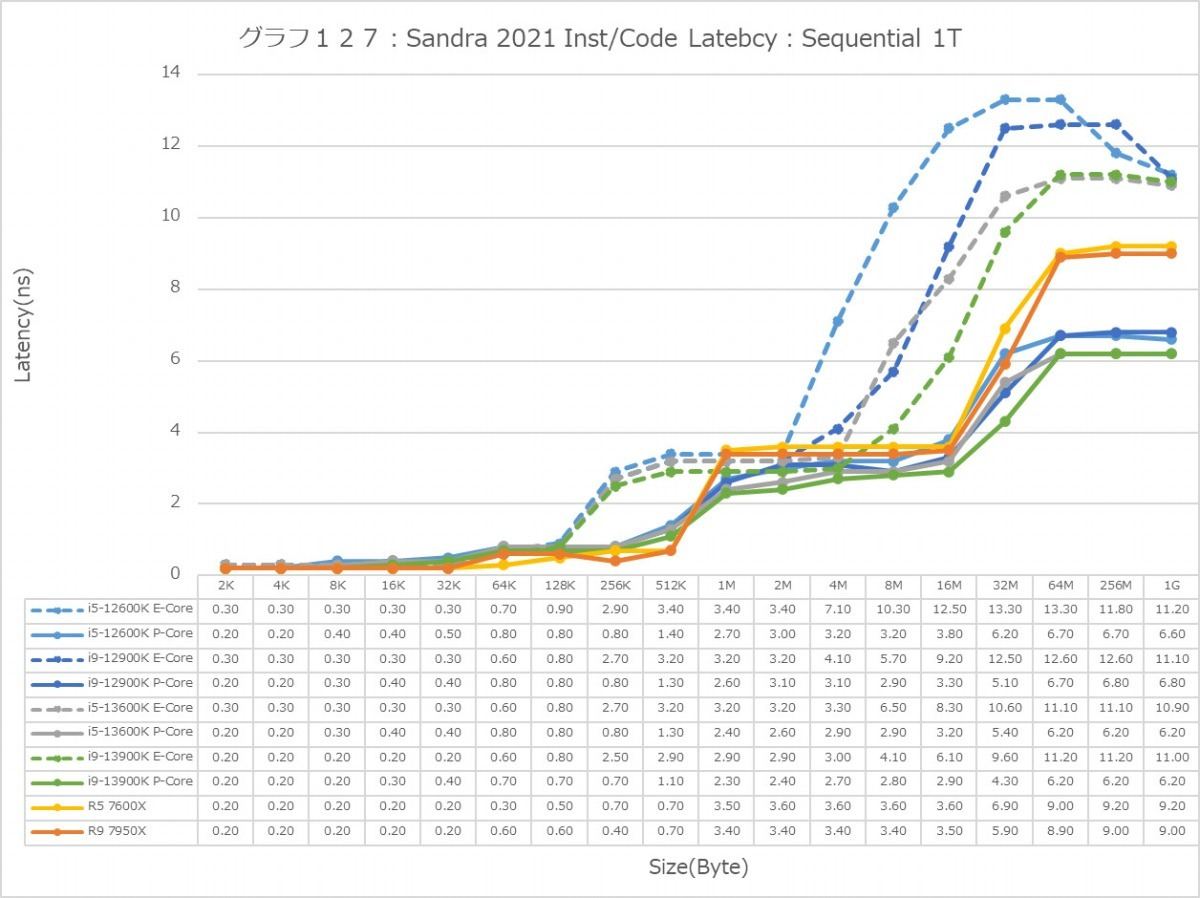
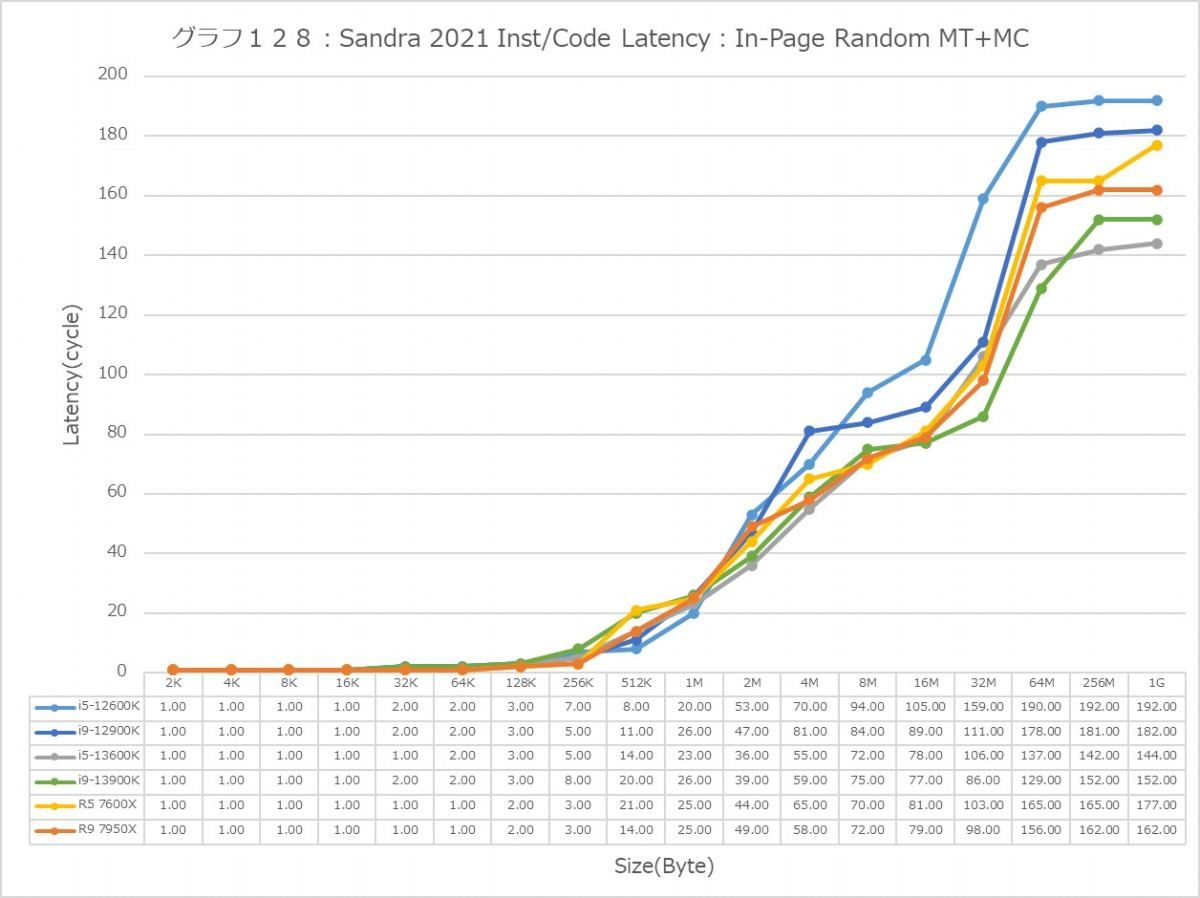
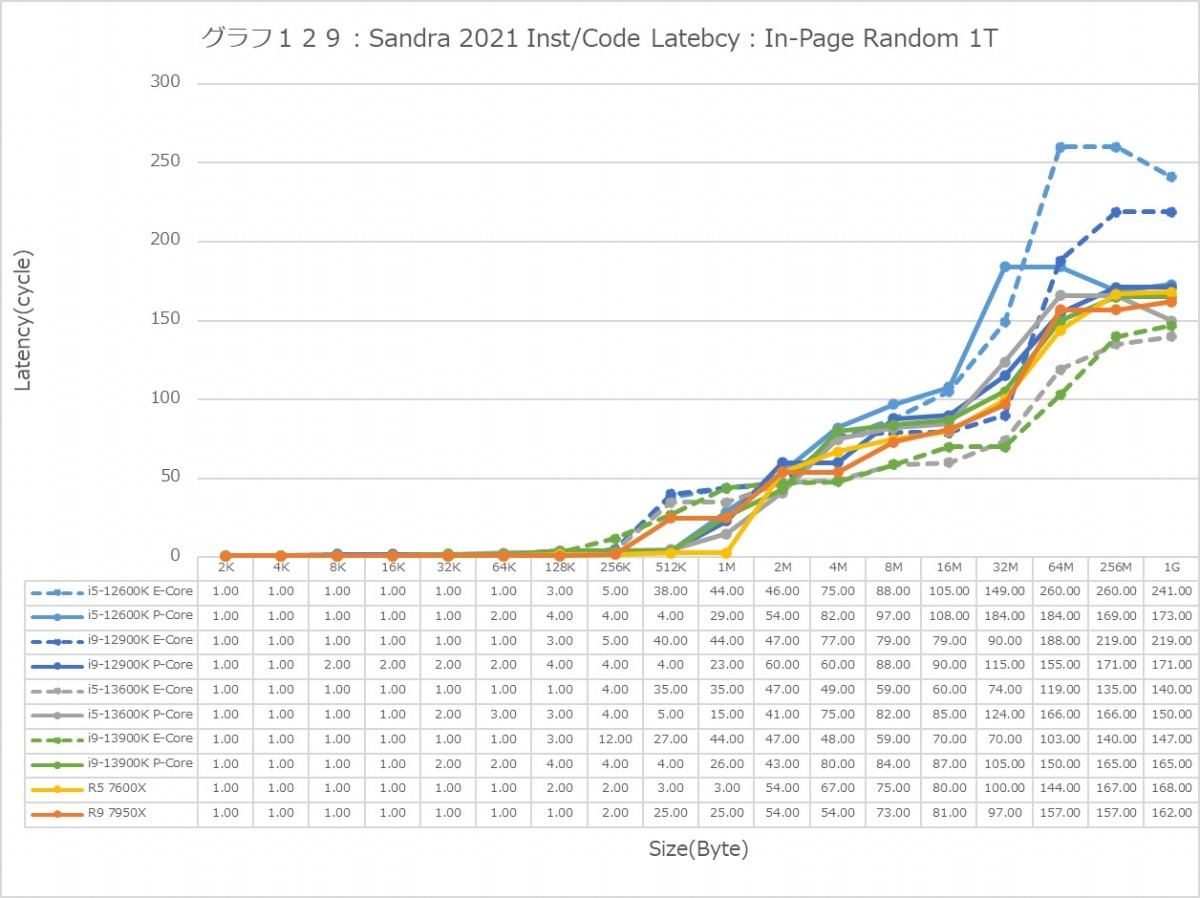
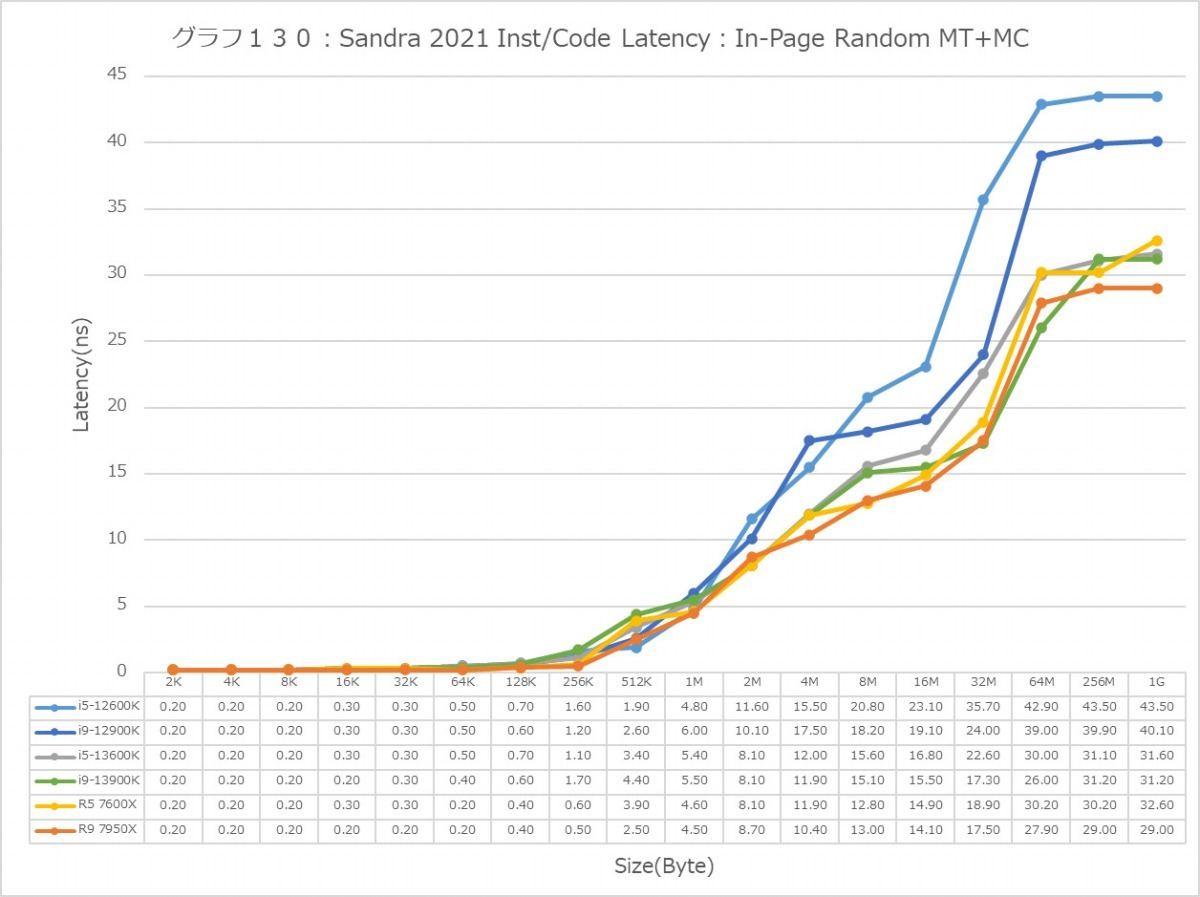
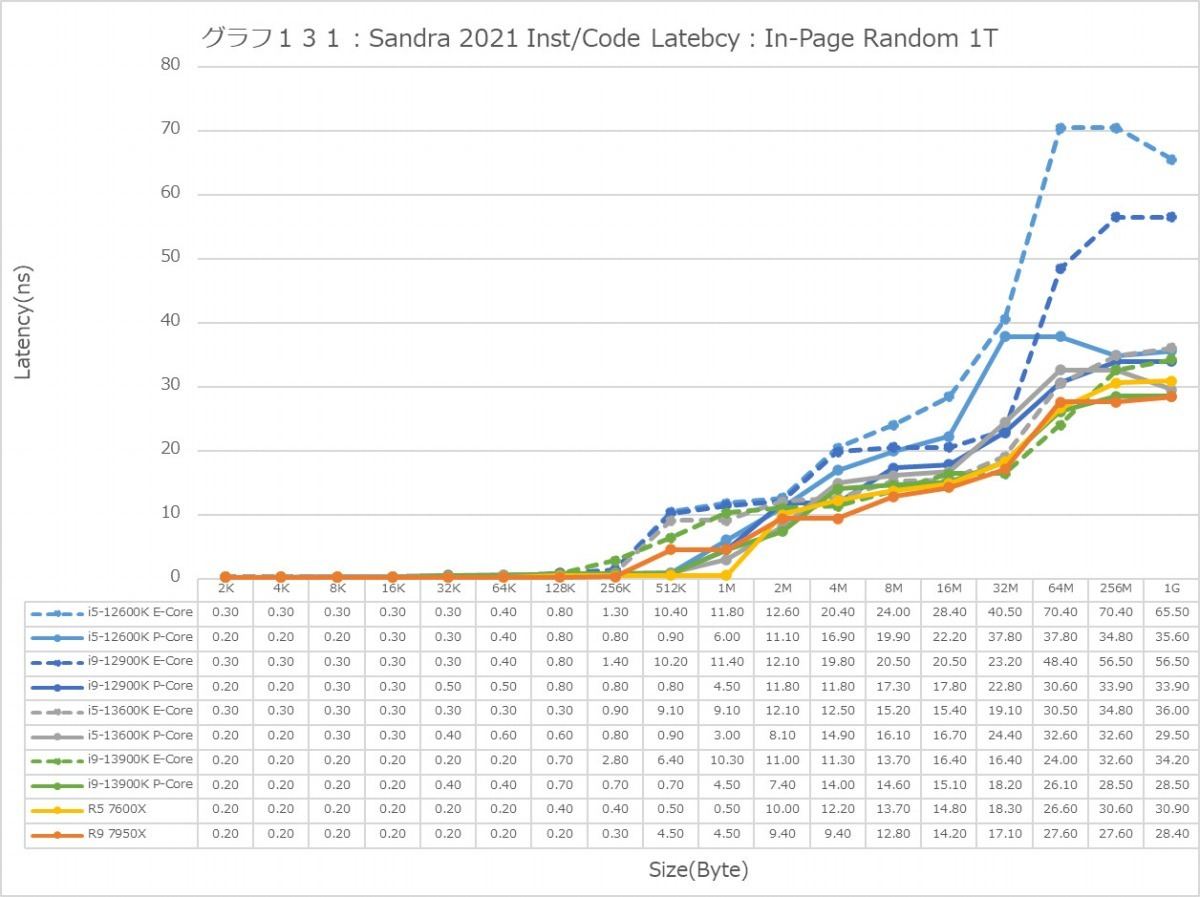
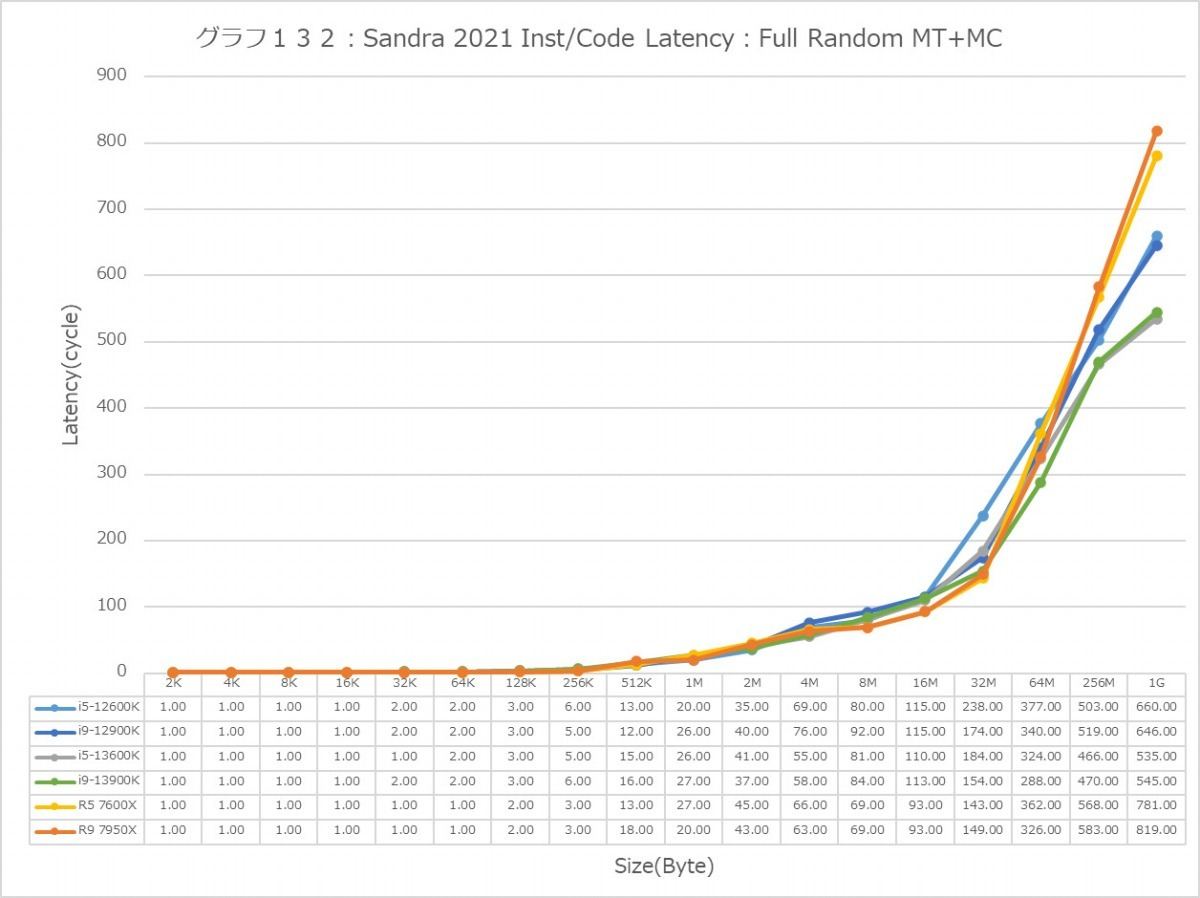
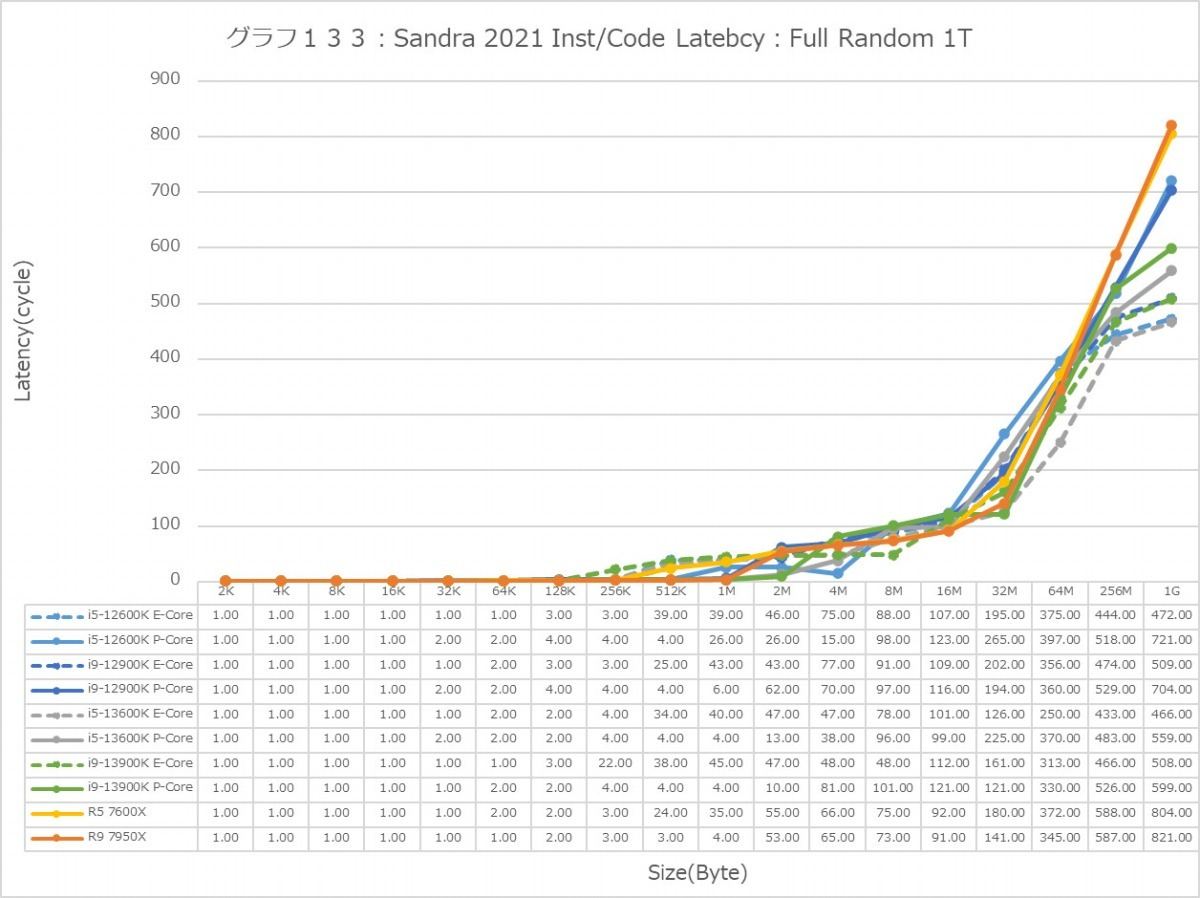
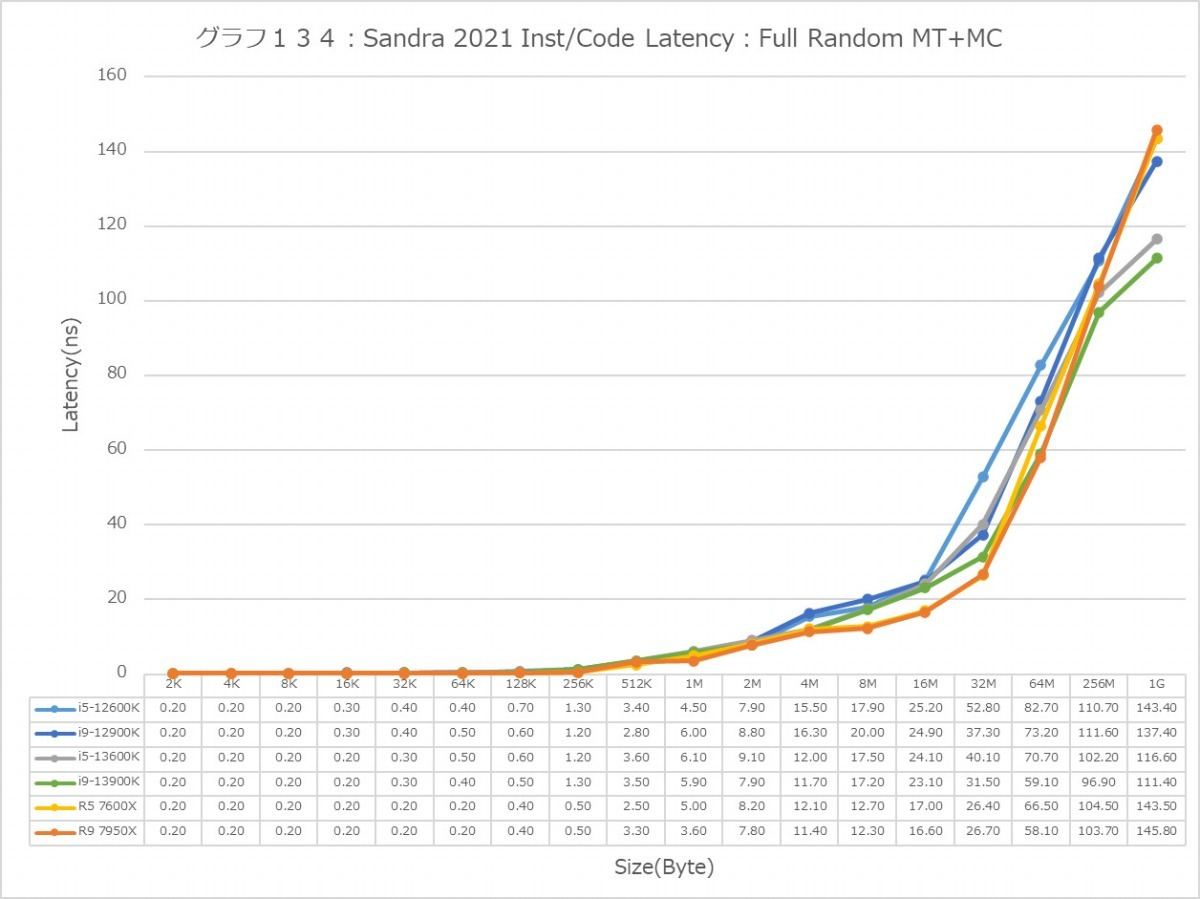
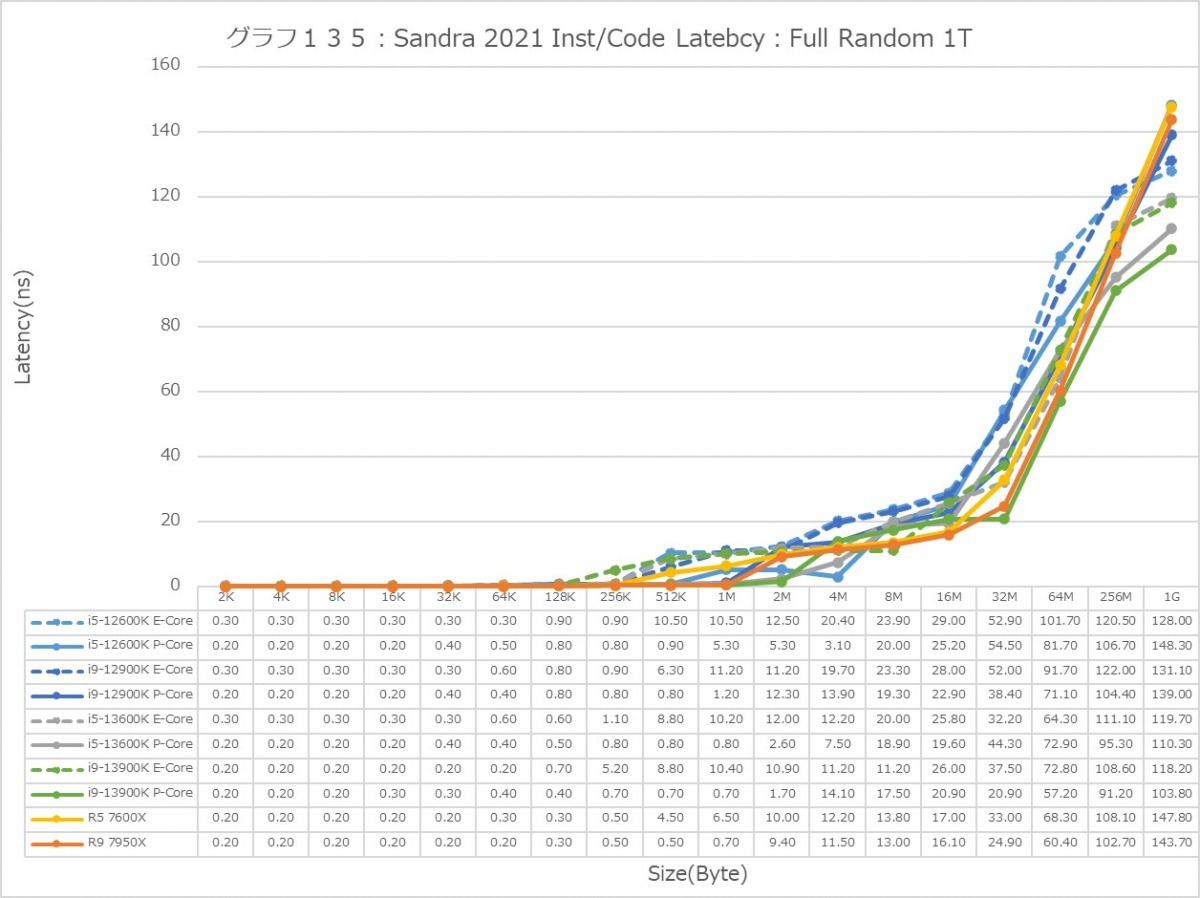
最後にCache/MemoryのAccess Latency(グラフ112~135)である。グラフ112~123がGlobal Data、つまりData L1側で124~134がInst/Code、つまりInst L1側となる。L2以降は共通だがL1に関しては別のパスになるからこれを分離して測定している格好だ。ちなみにL1~L3に関してはCycle数で、Memory Accessはnsで比較するのが正しいため両方示している。アクセスパターンはSequential/In-Page Random/Full Randomの3パターンで、これをMT+MC及び1Tの場合で示している。結果、無駄にグラフが増える格好になっているのはご容赦いただきたい。
ということでまずはGlobal Data。とにかくSequentialだとZen 4コアのLatencyの低さは特筆ものである。ちょっと意外なのが、Core i9-13900KのL2アクセスが2cycleほど高速な事。ここは高速化されていない筈なので、どうしてこういう結果になったのか興味深い。ただ1Tのケースを見ると、P-Coreは5cycleでアクセス出来ているあたり、P-CoreとE-Coreを合わせた結果として従来は11cycleと判断されていただけ、という気もする。In-Page RandomになるとZen 4を含めてすべてが急速に悪化するのはまぁ当然なのだが、L2~L3で一番Latencyが少ないのがZen 4というあたりは、だいぶこの辺の最適化が進んだ気がする。ちょっと面白いのはグラフ117で、なぜかAlder LakeのE-Coreのみ、メモリアクセス時のLatencyが妙に少ない。Raptor LakeのE-Coreはそれなりに多くなっているから、これはAlder LakeとRaptor Lakeのメモリコントローラの問題か、もしくはRaptor LakeはE-CoreのClusterが4つあることの弊害かのどちらかが理由と考えられる。
-
グラフ120

-
グラフ121

-
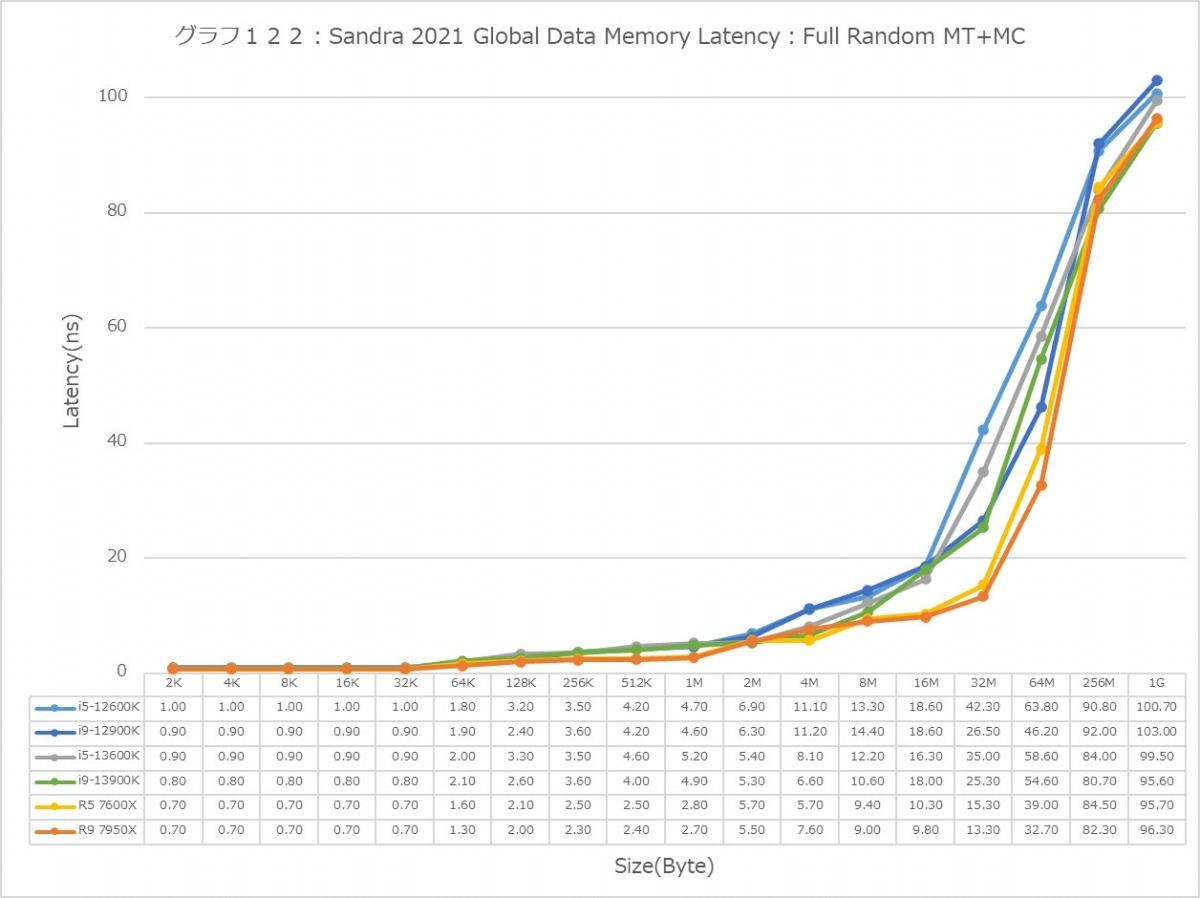
グラフ122

-
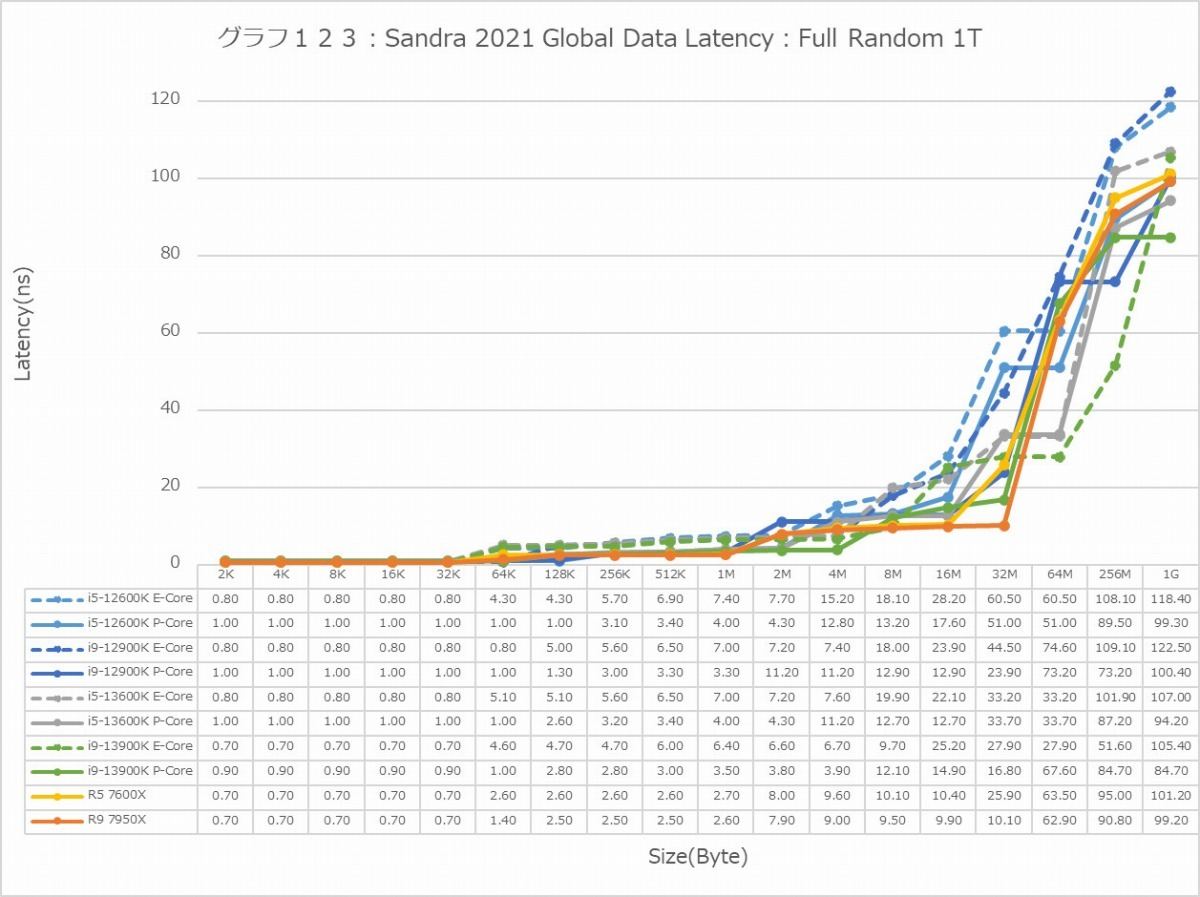
グラフ123

この傾向はFull Randomでも変わらない。L3までの範囲で、Zen 4は非常に良い成績を残しており、Alder LakeやRaptor Lakeを凌ぐ。1Tで見れば、L2→L3の遷移のところでややCore i9-13900KよりもLatencyが増えるシーンもあるが、L3までの範囲全体で見ればZen 4コアがAlder Lake/Raptor Lakeを凌ぐLatencyの低さを実現しているとしても良いだろう。
-
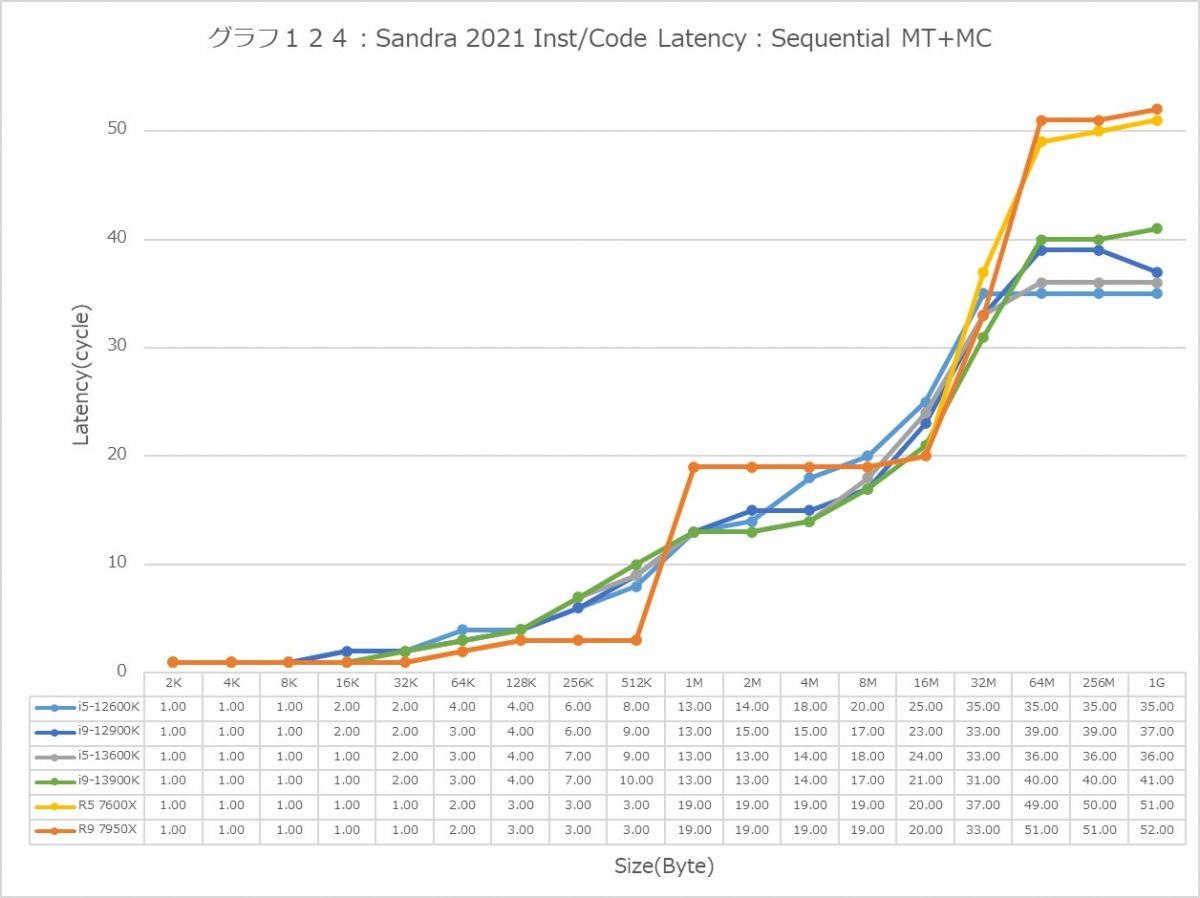
グラフ124

-
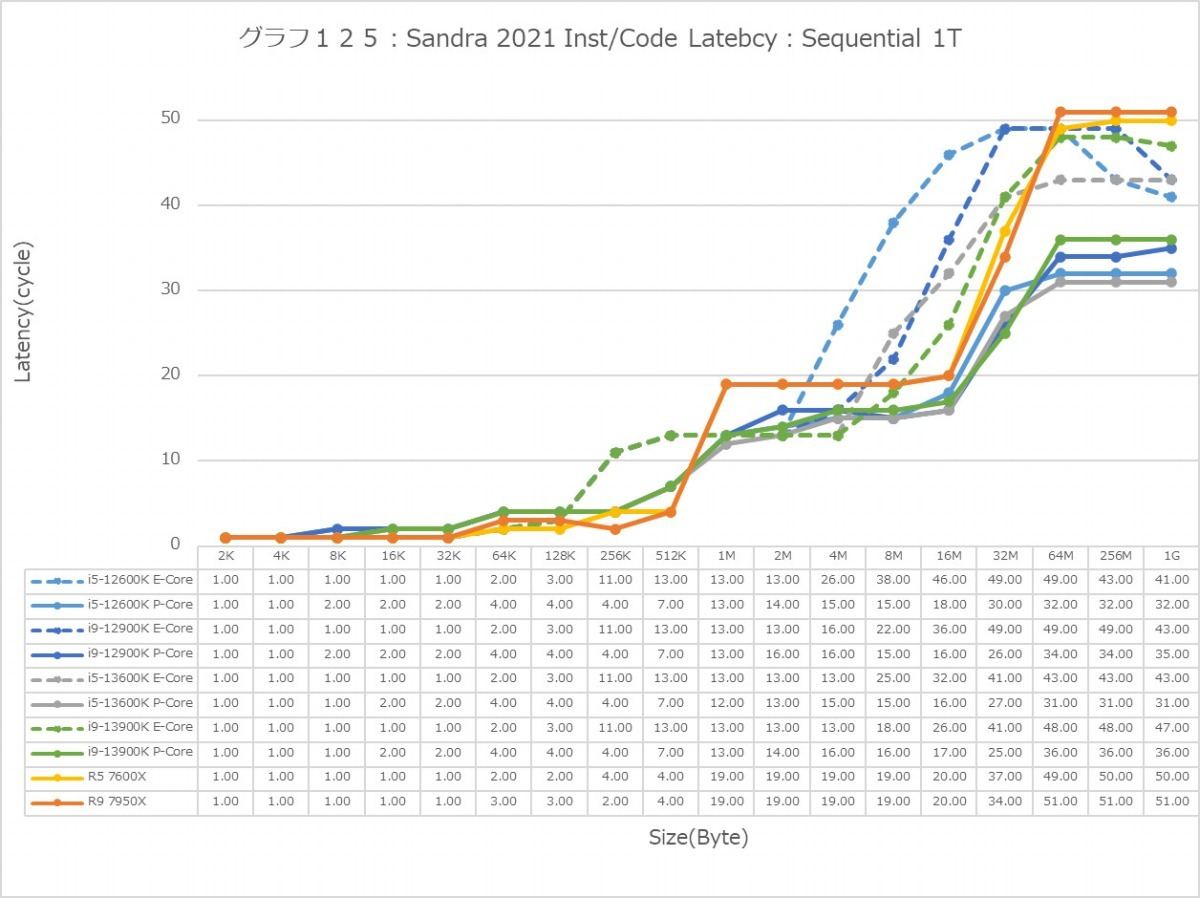
グラフ125

-
グラフ126

-
グラフ127

-
グラフ128

-
グラフ129

-
グラフ130

-
グラフ131

-
グラフ132

-
グラフ133

-
グラフ134

-
グラフ135

次にInst/Code。L0(MicroOp Cache)/L1の範囲は1cycleでアクセス可能なのはどのプロセッサ/コアも同じで、またアクセスパターンによる差もない。なので後はGlobal Dataと同じか? というとそうでもなく、例えばSequentialだとL3におけるZen 4コアのLatencyはMT+MC/1Tのどちらでも一番多くなっているなど、ちょっと違いがあることが判る。もっともこれが何か問題あるか? というと微妙なところ。L2で収まりきらず、L3から直接プログラムをロードするようなシーンが通常どの程度あるか? と考えるとちょっと想像が付かないからだ。またSequentialではZen 4のLatencyが多くなっているが、In-Page Random/Full Randomでは差が無くなりGlobal Dataの場合とさして差が無くなっているのも特徴的である。
あと1Tの場合で言えば、Golden CoveコアとTremontコアではL2領域のLatencyが全く異なるのも特徴的である。理由は明白で、TremontコアではCluster単位で共有L2が実装されているからで、Private L2を持つGolden CoveやZen 4よりLatencyが増えるのは避けられないためだろう。またTremontがL3の領域で早めにLatencyが増えるのは、やはりL3とコアの間にCluster(と共有L2)が挟まるためと思われる。エリアサイズや効率を取るか、性能を取るかのバーターの結果と考えるべきだろう。
-
グラフ136

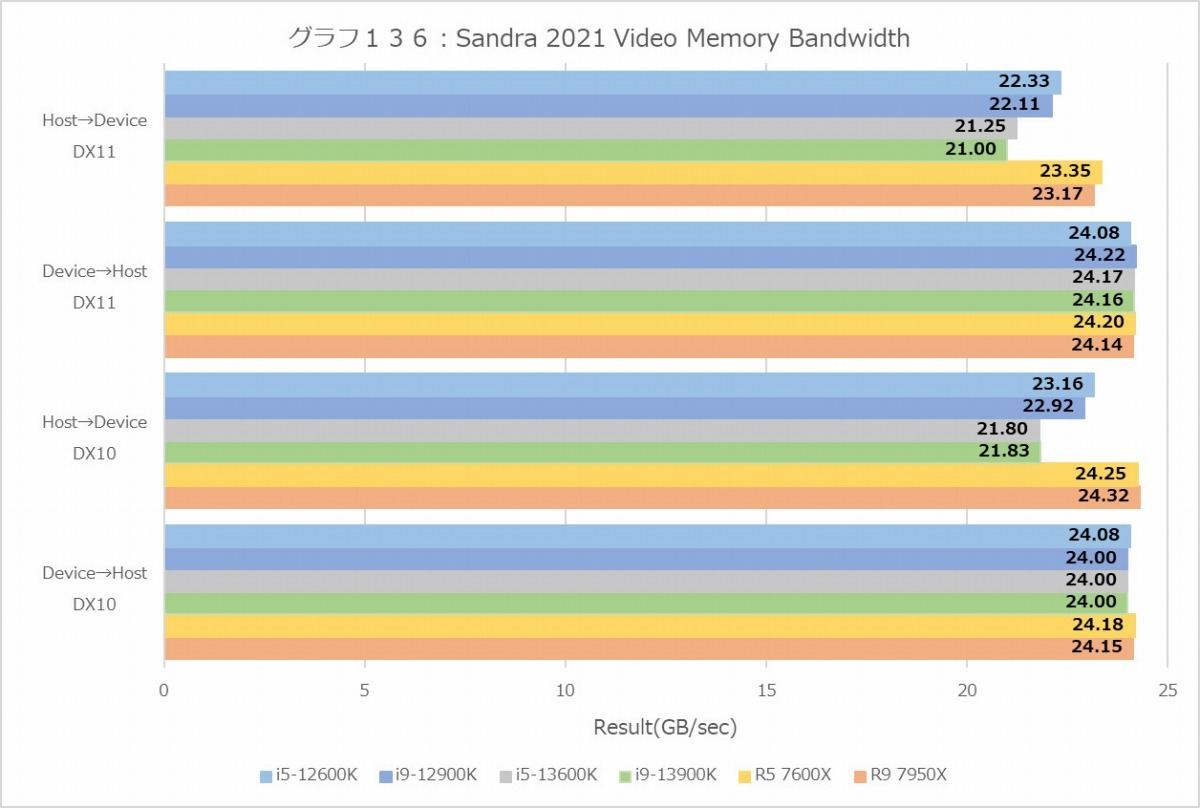
Sandraの最後はVideo Memory Bandwidth(グラフ136)であるが、これは要するにPCI Expressの帯域確認である。ちょっと意外だったのはHost→Deviceの転送でRaptor LakeがAlder Lakeよりも遅くなっている事である。このあたりに何か手が入っているとおも思えないのだが。結果として安定して高い帯域を維持しているZen 4(というか、X670)が最高速という結果になった。これまでAMDのChipsetではしばしば帯域がやや低めという事も多かったのだが、色々逆転している感じだ。








