
米Intelは米国時間の3月22日に予告した通り、4月6日にIce Lake-SPこと第3世代Xeon Scalable Processorを公式に発表した。この内容をまとめてお届けしたい。
-

Photo01:

今回発表されたのはIce Lake-SPであり、FPGAのAgilexやOptane SSD P5800X/Optane Persistent Memory 200シリーズ、Intel SSD D5-P5316、それとIntel Ethernet E810-2CQDA2などは既に発表済みの製品である(Photo02)。ということで、Ice Lake-SPを中心に説明したい。
-

Photo02: 強いて言えばEthernet E810はこれまであまり取り上げられてこなかった製品ではあるが、発売自体は今年第1四半期である。QSFP28でポートあたり100Gbpsに対応、I/FはPCIe 4.0となっている。

Photo03が今回の主要な特徴である。最大コア数は40に増加。またSunny Coveコアの採用でIPC(クロックあたりの性能)を20%向上させた。AVX 512周りも大分高速化したようで、これらを利用するアプリケーション(AIも含む)では更に高い性能向上が得られる、としている。
-

Photo03: 5年前のXeon E5に比べると2.65倍の性能向上とするが、少しわかりづらい比較か?

Photo04がもう少し詳細な情報となる。最大メモリ容量は6TB(Optane Persistent Memory利用時)、Memoryそのものは8chに増え、PCI Express Gen4をSocketあたり64レーン利用可能となっている。ちなみに今回のIce Lakeは1ないし2 Socket向けとなっており、4 Socket向け以上はCooper Lakeが担う事になっている(Photo05)。
-

Photo04: 実は現時点でark.intel.comのデータがバグってる感じで、Optane Persistent Memoryを使えない製品ですら最大メモリ容量が6TBになっているのだが、恐らくDRAMだけの場合はEPYCと同じく4TBと思われる。

-
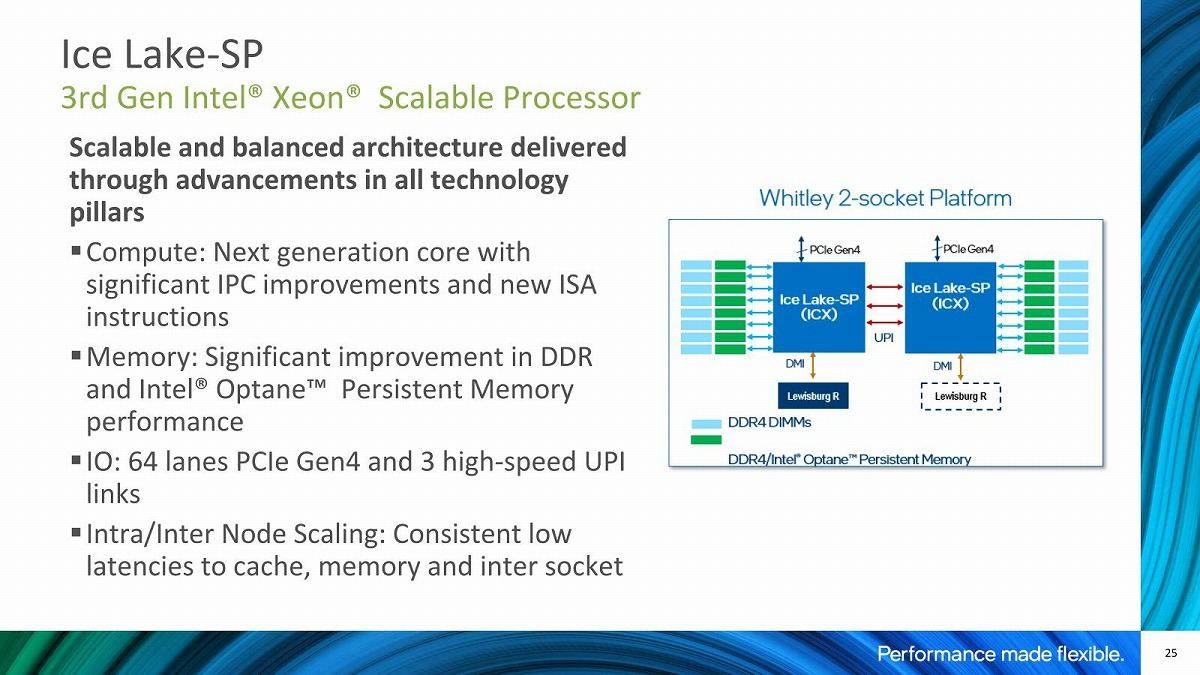
Photo05: Whitley Platformの概略。Persistent Memoryはメモリチャネルあたり1枚に制限される。

コアそのもので言えば、AVX-512そのものはSkylake-SPの世代から実装されている訳だが、少しづつ機能が強化されており、それもあって例えば暗号化周りで言えば1.5~5.7倍の高速化が可能になった、とされる(Photo06)。またメモリ周りの帯域強化&Latency削減も実現した(Photo07)としている。DDR4-2933×6→DDR4-3200×8でメモリ帯域そのものが1.5倍近く増えたうえ、LLCも1.25MB/coreから1.5MB/coreに強化されていることに加え、恐らくLLCへの帯域そのものも増えているのではないかと思う。またUPI Linkも6.4GT/sec→9.6GT/secときて、Ice Lake-SPでは11.2GT/secに向上したそうだ。更に割込発生→アプリケーション起動までのLatencyが下がった事も挙げられている(Photo08)。
-
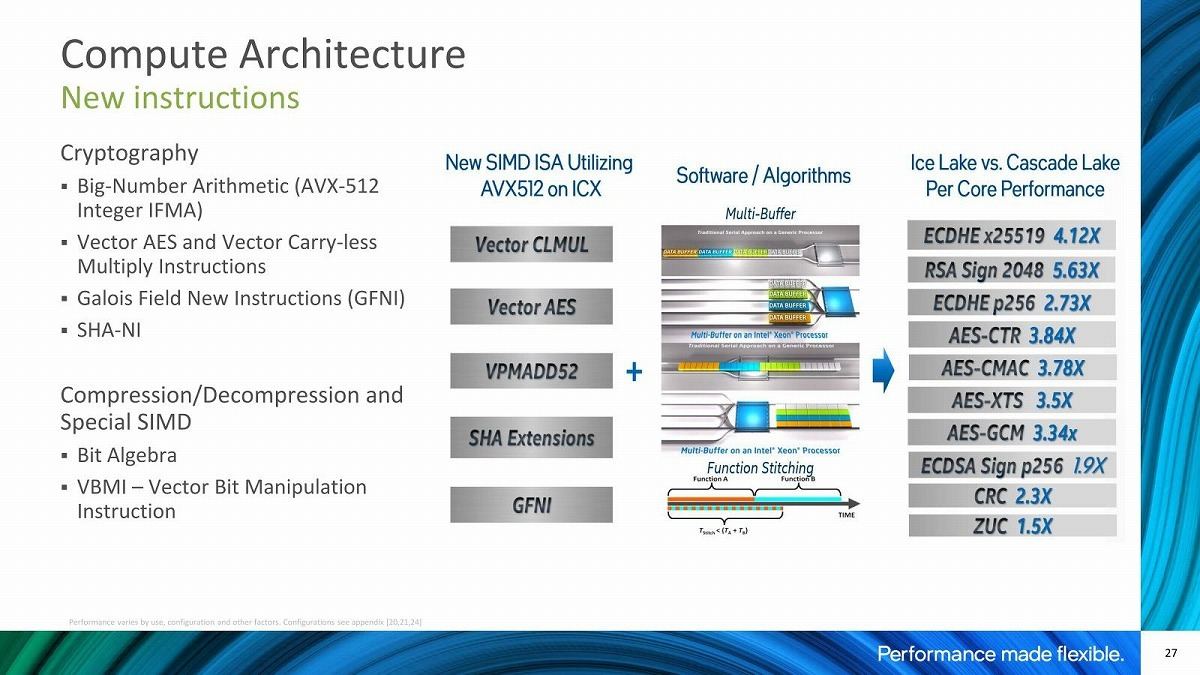
Photo06: これらの拡張命令そのものはMobile向けのIce LakeとかDesktop向けのRocket Lakeと同じである。

-
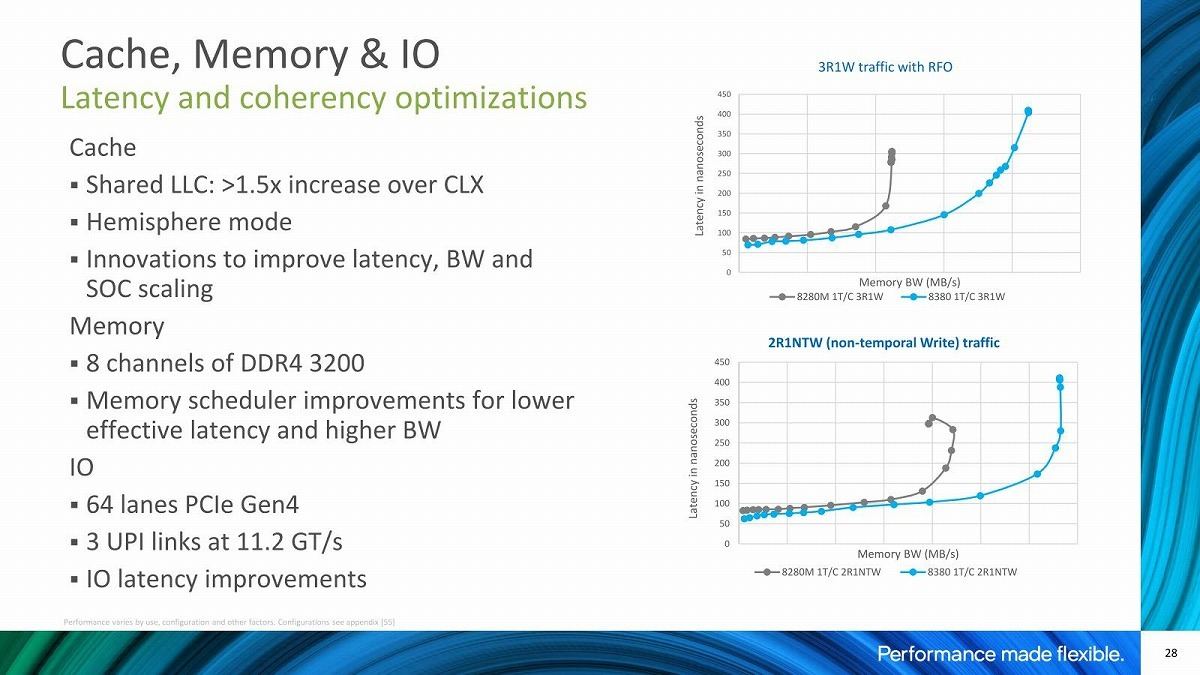
Photo07: Hemisphere modeは中止になってしまったKnights Landingで実装されていた、コアとLLCの間のアクセスの方法。Knights LandingではCPUコアとL2キャッシュの間のアクセスにAll to All、Quadrant/Hemisphere、SNC(Sub-NUMA Clusteing)の3種類のモードを持っていたが、このうちHemisphere modeがIce Lake-SPで実装されたらしい。

-
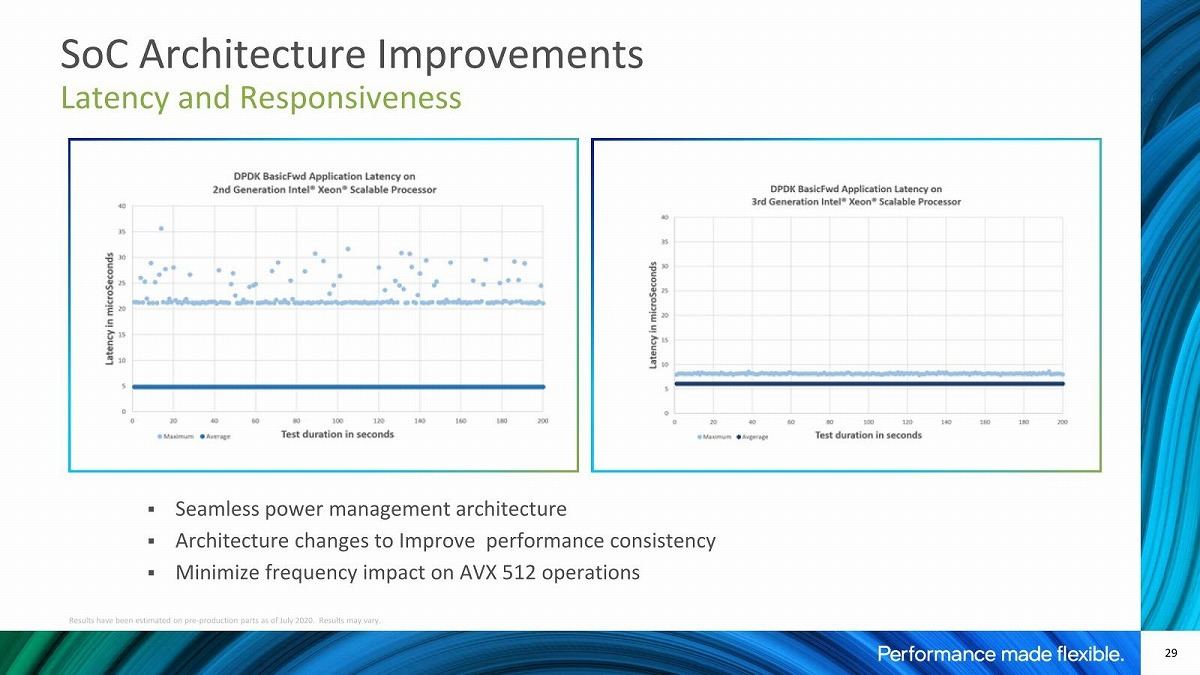
Photo08: Average Latency(濃い青)は大差ないが、Maximum Latency(薄い水色)は大きな差がある。それだけ安定してInterruptが伝達されるようになった、という話である。まぁこれはコアというよりは、外部の割込コントローラ周りの話であるが。

さて実際の性能であるが、まず第2世代Xeon Scalable(や、それ以前)との比較がこちら(Photo09)。内蔵されているアクセラレータを有効/無効化した際の性能改善率がPhoto10、Cascade Lake世代とのアプリケーションの性能比較がPhoto11、後で説明するOptane MemoryやSSDなどとの組み合わせての性能比がこちら(Photo12)となる。Photo13はNetwork Switchなどを対象としたWorkloadで、Ice Lake-SPの新機能/新命令がどんな具合に効果的か、をCascade Lake-SP比で示したものである。Photo14はHPC Application、Photo15は主にInferenceの性能を、それぞれCascade Lake-SPと比較する形で示している。
-

Photo09: これはSPECrate 2017とStream、それとLINPACKなのでアプリケーション性能とはまた異なるが、一つの目安にはなるかと思う。

-

Photo10: Crypto Accelerationのみ、Acceleratorを搭載していないCascade Lakeとの比較となっている。

-
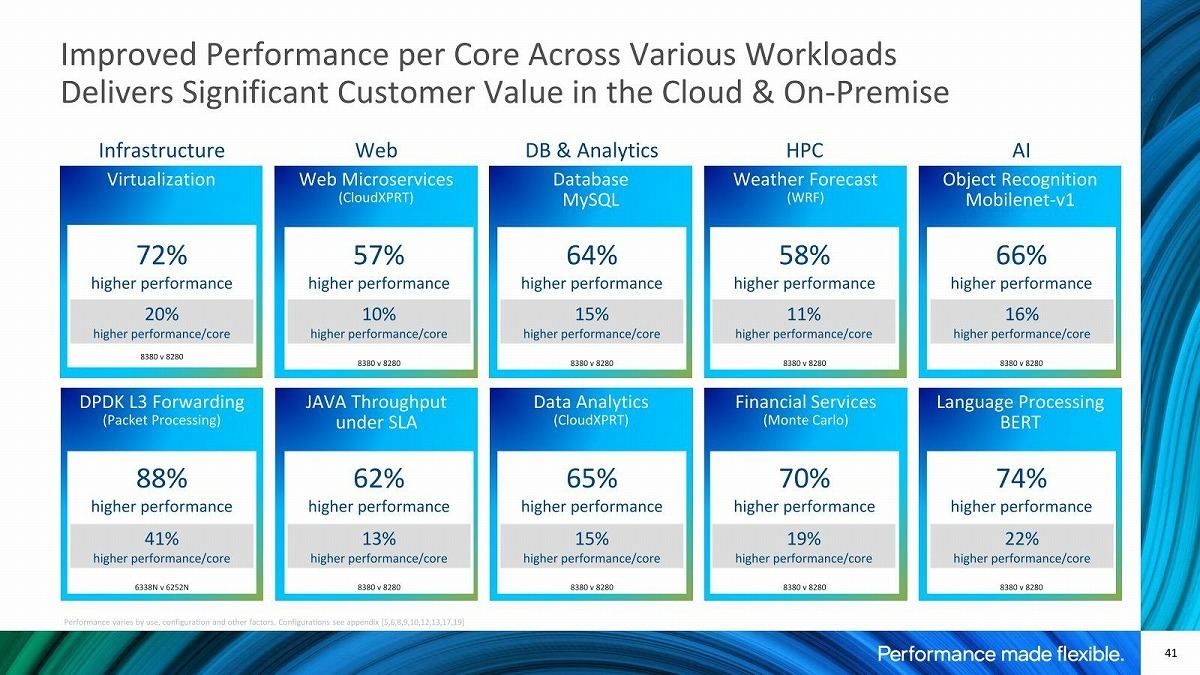
Photo11: トータルとしての性能比、及び1コアあたりの性能比の両方が示されており、コアそのものは(たまに41%のDPDK L3 Forwardingなども混じるが)基本20%以内である。DPDK L3 Forwardingの場合、NICとPCIe Gen4で接続できることが大きい模様だ。

-

Photo12: 主にストレージ向けソリューションの場合の性能をまとめたもの。それはいいのだけど、200GbEはあまり一般的では無い気もする。

-

Photo13: Virtual Broadband Network GatewayはDDIO(Data Direct I/O:Sandy Bridge時代から搭載されているI/Oの高速化手法)だけで、ここでは特に機能差がないので、IPCの比である20%アップ、という事だろうか?

-
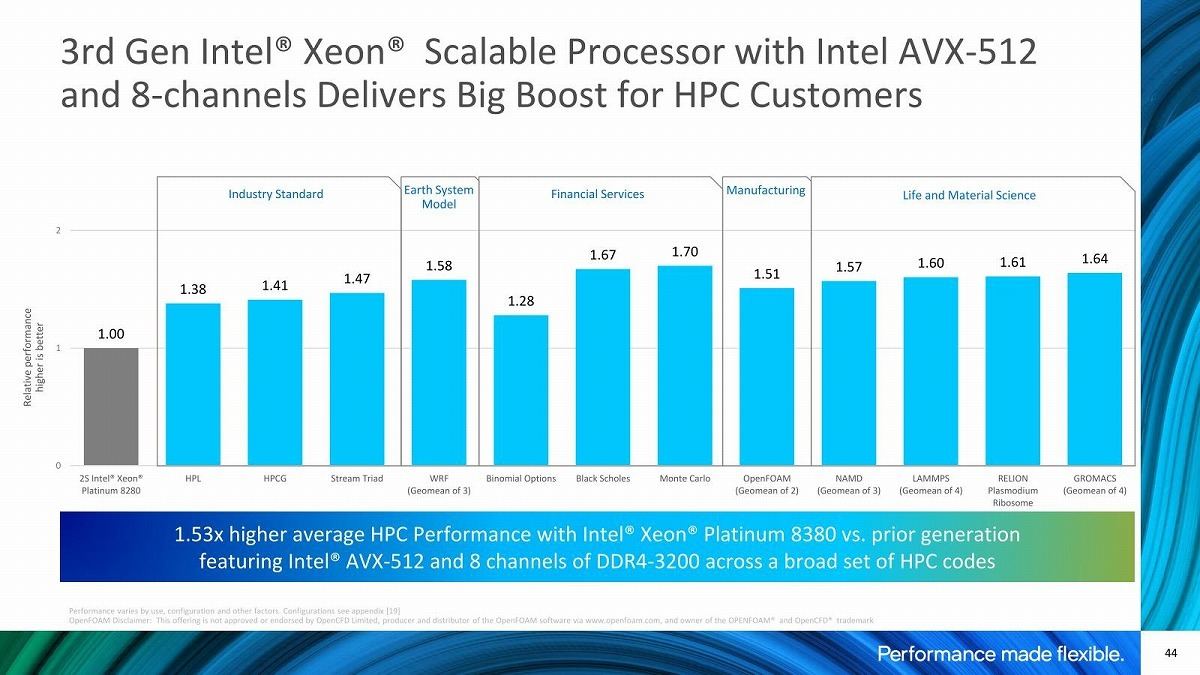
Photo14: Cascade Lake-SPと比較して、平均で1.53倍の性能改善があるとする。

-
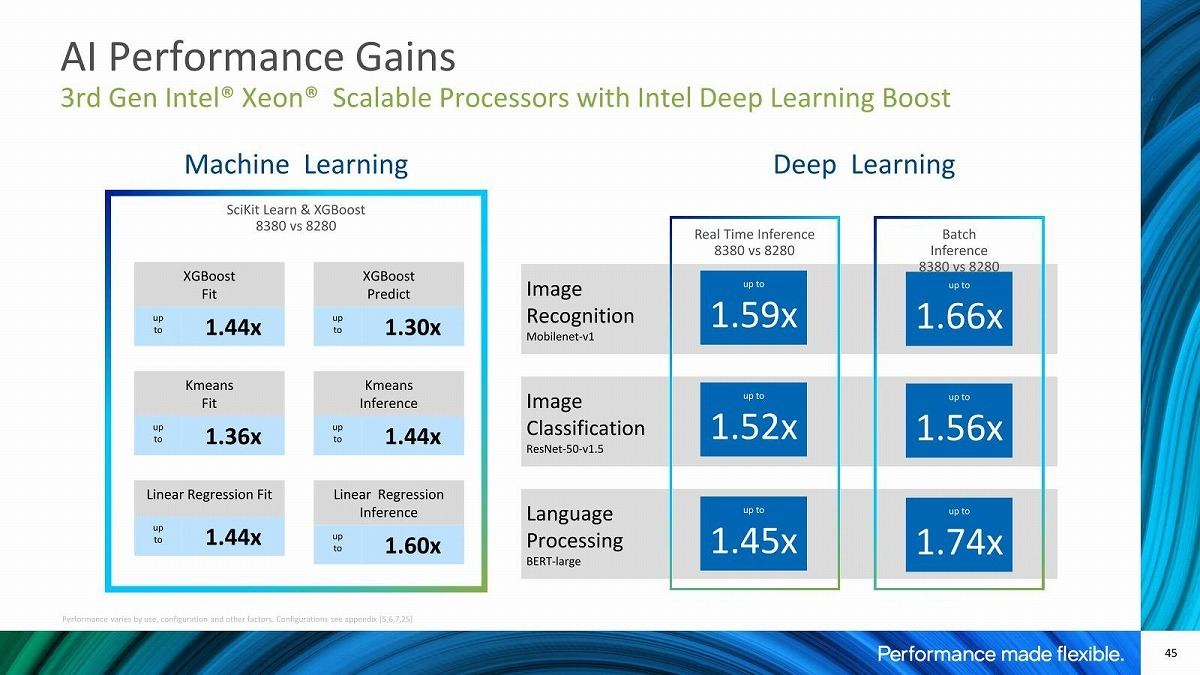
Photo15: 誤解のない様に言っておけば、Cascade Lake-SPの世代からDL Boostは利用可能になっており、その意味では違いが無い(AVX-512のVNNIはCascade Lake世代から搭載されており、これをDL Boostと称しているのはIce Lake-SPでも変わりがないとの事)。

これに続いてが第3世代EPYCとの比較である(Photo16,17)。アプリケーション性能は、HPC、クラウド、AIのどの分野でもIce Lake-SPが圧倒的に高速、というのがIntelの主張である(Photo18)。
-

Photo16: 脚注を見る限り、Milanの数字も実測値の模様。

-

Photo17: こちらはメモリアクセス周りの性能比較。

-
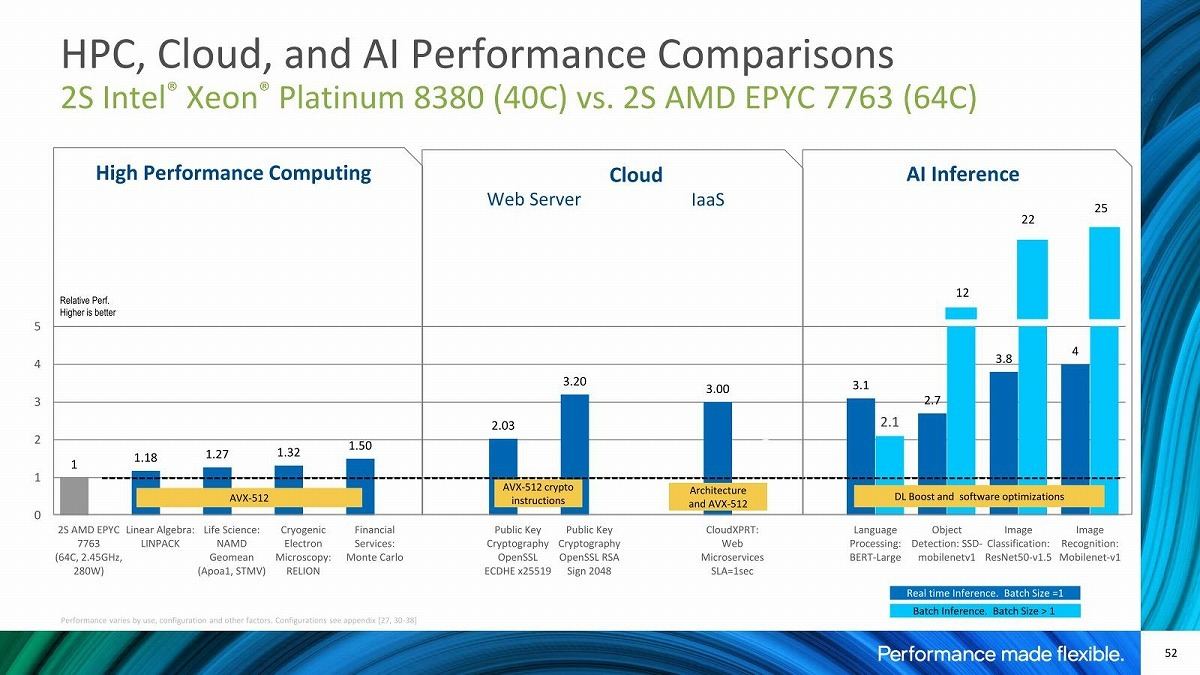
Photo18: まぁAVX-512を使う限りは当然である。逆にAMDはAVX-512を使わないベンチマークを公開している訳で、このあたりの判断が難しい。

ちなみに現時点でark.intel.comに登録されている製品は全36SKUである(表1)。
-
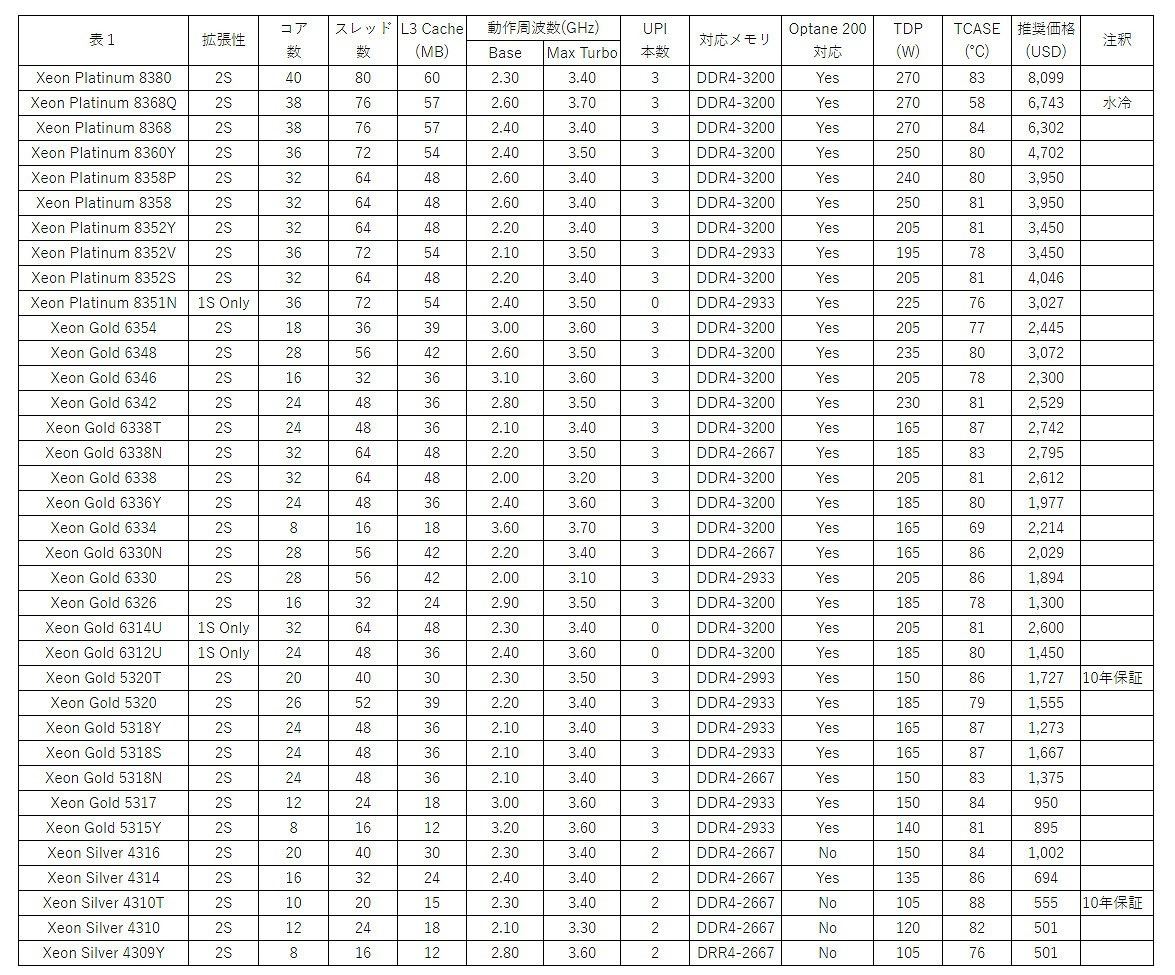
■表1

- 最大メモリ容量6TB
- メモリチャネル8ch、ECC対応
- PCI Express Gen4対応、64レーン(4×16)
は全てのモデルで共通となっている。上でも少し触れたが、Xeon Silverの中にはOptane Persistent Memory 200シリーズに対応しないSKUがあり、にも関わらず最大6TBというのは多分間違っていると思うのだが、まぁそれは措いておくとして、殆どが2 Socket対応(1 Socketは3つのみ)となっている。
注目すべきはやはりBase Frequencyが殆ど上げられないでいる事だろうか。一部の例外(例えば8コアのXeon Gold 6334)を除くとBase Frequencyは2GHzそこそこである。またハイエンドの40コア製品のTDPは270Wに達しており、それもあってか水冷専用モデル(Xeon Platinum 8368Q)なども用意されていたりする。このあたり、次の世代(Sapphire Rapids)ではProcessが10nm Enhanced SuperFinになって大分改善されるかもしれないが、10nm世代のIce Lake-SPではやはり動作周波数は低めに抑えられている。AVX-512を性能改善のメインにせざるを得ない、というのは多分このあたりから来ているのだろう。
余談だがそのIce Lake-SPのウェハも公開された(Photo19)。この写真から推定すると、ダイサイズは凡そ19.7mm×32.1mmで632.3平方mmという計算になる。28コアでこれなのだから、ハイエンドの40コア製品はかなり大きなダイになると想像される。これはそのまま価格に影響しているだろう。
-
Photo19: これは28コアのものと思われる。









