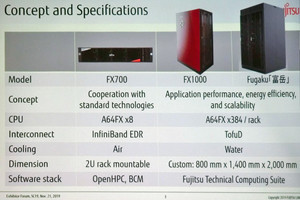
HPC(High Performance Computing)の分野では計算ノード間の通信を担うインタコネクトの重要性が増している。HPCの高性能化から、接続する計算ノードの数が増えてきており、それに伴い通信遅延の低減が重要になってきている。
-

SC19においてInfiniBandを使うIn Networkコンピューティングについて発表するMellanoxのGilad Shainer氏

スパコンインタコネクトの定番、MellanoxのInfiniBand
MellanoxのInfiniBandはスパコンのインタコネクトの定番となっており、Top500 1位のOak Ridge国立研究所のSummit、2位のLawrence Livermore国立研究所のSierra、3位の中国の無錫スパコンセンターの神威・太湖之光、5位のTexas Advanced Computing CenterのFrontera、8位の産総研のABCI、10位のLawrence Livermore国立研究所のLassenとTop10のスパコンの内の6システムで使われている。
-

世界のトップ上位10位のスパコンの内の6システムは、ノード間の接続にMellanoxのInfiniBandを使っている (出典:このレポートのすべての図は、SC19でのMellanoxのGilad Shainer氏の発表スライドを撮影したものである)

Top500最上位のスパコンでは100Gbit/sの伝送速度(4レーンでの伝送速度)のEDR規格のものが多く使用されているが、すでにその2倍の200Gbit/sの伝送速度のHDR規格のものが使われ始めている。TACCのFrontera、韓国気象庁の50PFlopsシステム、オーストラリア国立大学のGadiシステムなどがHDR InfiniBandを使い、より効率が高いと言われるDragonfly+トポロジのネットワークを使っている。
-

より新しいスパコンでは、EDRの2倍の伝送速度のHDRを使うものが出てきている。また、Fat Treeではなく、より優れているといわれるDragonfly+トポロジを使うシステムも出てきている

従来のCPUセントリックな処理方法では、インタコネクトはCPUやGPUなどの計算ノードを結び、データの伝送を行うだけの機能を担うものであった。しかし、データがネットワークを通過している途中に、並列的にネットワークで演算ができれば計算の処理性能が上がるし、ネットワークの性能もスケールし易くなる。
-

左の図のように、従来のネットワークはデータを伝送するだけでデータの演算処理は計算ノードで行われていた。これに対して右の図のようにネットワークの中にIPUというデータ処理エンジンを置き、データの伝送途中にデータの処理を行えば効率の良い処理ができる(少なくともその可能性がある)

例えば次の左側の図のようにすべての計算ノードのデータを左上のノードに集めて合計を計算する従来の方法では、30-40μs掛かってしまう。これを右の図のように、ネットワークの中のIPUを使って階層的に合計を求めるようにすれば3-4μsで合計を求めることができる。
-

左の図のように、各ノードから順にデータを読み出し、左上のノードで合計を求めるやり方では30-40μs掛かる。一方、右の図のように、IPUを置き、階層的に合計を求めていけば3-4μsで合計を求めることができる

集合通信を高速化する「SHARP」
また、MellanoxのInfiniBand製品は、次の図のようにネットワークの接続性のレベルからアプリケーションのレベルまで、すべてのレベルでHPCやAIフレームワークの性能を加速することができる機能を備えている。
接続性のレベルでは、ハイパーキューブ、ファットツリー、トーラス、Dragonflyなどの各種のネットワーク接続が可能である。そしてネットワークのレベルではRDMAやGPU Directでデータ転送の効率を上げ、Mellanoxの「SHARP」を使えばインネットワークの処理ができる。これらの機能によりHPCやAI処理の性能を上げられる。
-

MellanoxのInfiniBandはネットワークの接続形態からRDMAやGPU Directのような効率の高いデータ転送をサポートし、HPCやAI処理の性能を高めている

Mellanoxは、このように階層的に総和を求めるような処理をネットワークの中で実現するためのプロトコルとして「Scalable Hierarchical Aggregation and Reduction Protocol(SHARP)」を開発した。
-

SHARPはインネットワークで総和などの処理を実現するために開発された

SHARPではネットワークの中に総和などを求める木構造を作り、その中にIPUで処理する数多くのグループを作る。このようなグループは依存関係が無ければ並列に実行することができる。
このようにすることにより、バリア(全ノードの処理が終わるまで先に進まない)や総和や最大値を得るような集合通信の処理時間を大幅に短縮することができる。SHARPでの計算は、16/32/64bit精度の整数、あるいは浮動小数点数で行うことができる。
-

SHARPはネットワーク上に、木構造のグラフを作り、並列に計算ができるようにグループを作る。右の図のようにこの木構造のグラフにしたがって計算することにより、多数のIPUで並列に演算でき、バリアや総和などの処理の性能を大きく向上させられる