Hot Chips 31においてNVIDIAは「Turing GPU」を発表した。TuringはRay Tracing(レイトレーシング)をリアルタイムに実行するハードウェアを備えたGPUであり、NVIDIAは2006年にCUDAを実行するGPUを出した以来の大きな飛躍であると位置付けている。
発表を行ったのは、NVIDIAのGPUアーキテクチャのシニアディレクタのJohn Burgess氏である。しかし、Turing GPUの発表スライドに注意していたら、同氏の写真を撮り忘れてしまった。
レイトレーシングのために開発されたTuring GPU
Turing GPUは通常の演算ではFP32で14TFlopsの浮動小数点演算と14TIPSの整数演算を行うことができる。この性能はVolta V100には及ばないが、NVIDIAのGPUの中ではかなり高い性能である。
また、「Tensor Core」と呼ぶディープラーニング計算用のFP16の行列の積和演算を高速で実行する機構を持っている。なお、この機構は機械学習の性能を引き上げるためVolta GPUから実装された機能である。そして、Turingでは「RT Core」と呼ぶレイトレーシングを加速する機構が追加された点が新しい。
これまでのGPUの描画は、いわば張りぼてで登場人物や車などを作り、張りぼての表面に色を塗ったり、模様を印刷した紙を貼ったりして画面を作っていたが、これでは滑らかな金属の表面に周囲の風景が写るというような表現はできない。
これに対して光源からの光が物体にあたり、反射したり回折したりを繰り返して、観測者の目に入るというプロセスを忠実に計算してやれば、風景の映り込みなどがある迫真度の高い画面が作れる。この手法をレイトレーシング(Ray Tracing)という。しかし、すべての光線の反射などを逐一計算して行くと、膨大な計算量になってしまう。CG映画では1画面を何時間もかけて計算することもできるが、ゲームではリアルタイムに画面を作らなければならない。
Turing GPUはレイトレース計算を加速するRT Coreと呼ぶハードウェアを付加することで、10Giga Ray/sという速度で光線(Ray)のモデル表面への入射点を計算する。
-

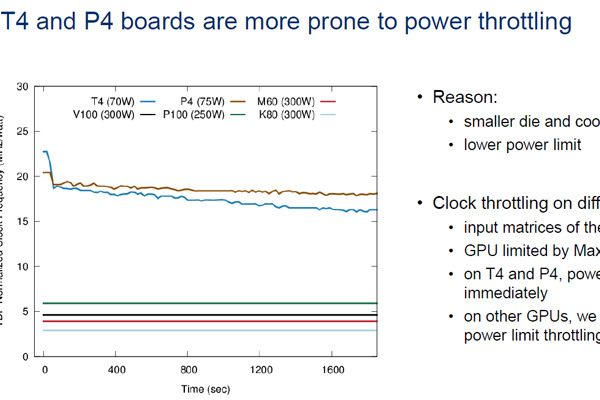
Turing GPUはSMと呼ぶグラフィックス用の演算機構とTensorコアというマシンラーニング向けの加速機構、RTコアというレイトレース向けの加速機構を搭載している (出典:このレポートのすべての図は、Hot Chips 31でのNVIDIAのJohn Burgess氏の発表スライドのコピーである)

SMのアーキテクチャ上の変更点
TuringのTU102チップはSM(Streaming Multiprocessor)を72個搭載し、演算器に相当するCUDAコアを4608個搭載している。この演算能力は科学技術用のVolta V100 GPUに迫る。ただし、Volta V100 GPUは科学技術計算用のFP64での計算をサポートしているが、TuringのCUDAコアはグラフィックス用であるので、FP32のサポートが中心である。FP64演算も互換性の観点から装備はされていると思われるが、その演算性能は低いと思われる。
そしてマシンラーニング用のTensorコアを576個搭載し、レイトレーシング用のRTコアを72基持っている。メモリは7GHzのGDDR6で、ビット幅は384bitでありピークメモリバンド幅は336GB/sである。大規模なスパコンにも使われるVolta V100はメモリのエラーを訂正するECC機能を持っているが、TuringではメモリのECCはサポートされていないと思われる。
-

今回発表されたTuring GPUチップはTU102という型番のもので、総トランジスタ数は186億となっている。SMを72基(CUDAコアの数は4608)とTensorコアを576基、RTコアを72基搭載する。メモリは7GHzクロックのGDDR6で、ビット幅は384ビットである

TuringのSMのアーキテクチャ上の大きな変更点は、FP32とINT32の両方の演算器が並列に動作できるようになった点である。従来は、どちらか一方しか動作できず、配列アクセスのインデックスの計算などでINT32演算器を使うと、並行してFP32演算器を動かすことはできなかったが、Turingではこれが可能になったので、演算器の利用効率が改善している。
-

TuringのSMでは、FP32とINT32が並列に演算を行えるようになった。L1 D$とテクスチャキャッシュ、シェアードメモリが一体化され、バンド幅が増えている。L1D$とシェアードメモリの区分は可変になっている

TuringのSMではL1 I$から毎クロックサイクル4ワープの命令を読み出し、それぞれのサブコアに供給する。これらの命令は異なるスレッドの命令であるので、実行順序やデータ依存性を気にする必要が無く実行することができる。そのため、Turingでは、Pascalと比べてスケジューラの数が2倍になり、命令発行ロジックも簡単にできているという。
NVIDIAのL1$とシェアードメモリの構造は毎世代変わっているが、TuringではL1 D$とシェアードメモリは、全体が96KBのメモリを64KB/32KB、あるいは32KB/64KBに分割して使用できるという作りになっている。
-

Pascalと比べて命令スケジューラの数が2倍となり、命令発行ロジックが簡単化された。L1$とテクスチャキャッシュ、シェアードメモリは一体化され、合計の容量が増え、アクセスも高速になっている

次の図は、Pascal(左)とTuring(右)のL1 D$とテクスチャキャッシュ、シェアードメモリの構造を比較するブロックダイヤグラムである。Turingでは、MIOと書かれたブロックが2個になっており、L1 D$のメモリバンド幅がPascalの2倍になっていることが分かる。その分、キャッシュアレイは薄くなっており、メモリのアクセスが高速になっている。
また、L1$の容量は最大2.7倍になっており、L2$の容量は2倍の6MBに増強されている。
-

PascalとTuringのL1$、テクスチャキャッシュ、シェアードメモリの構造を比較する図。左がPascal、右がTuringである。TuringではMIOが2重化されており、L1$のバンド幅が2倍になり、アクセス時間も短縮されている。L1$の容量は最大2.7倍、L2$の容量は2倍になっている

そして、TuringのSMはPascalと比較して、レジスタファイルの容量が倍増しており、ブランチユニットも改良されている。また、Tensorコアの搭載で、FP16でのディープラーニング演算の場合は16×8×8の演算を8クロックで演算できるようになった。これはPascalの8倍のスループットである。
-

TuringのSMは、Pascalと比べてレジスタファイルの容量が2倍、Tensorコアの搭載でディープラーニング計算の演算能力が改善され16×8×8テンソルを8クロックで処理できるようになった