



AMDはHot Chips 31において第2世代のZenプロセサである「Zen2」を発表した。Zen2はワークステーション向けには第3世代Ryzenに使われ、サーバ用には第2世代EPYCに使われている。
Zen2を発表したのはAMDのフェローでCPUアーキテクトであるDavid Suggs氏である。
-

Hot Chips 31でZen2プロセサを発表するAMDフェローのDavid Suggs氏

Zen2では、Zenからマイクロアーキテクチャが色々と変更されている。変更の第一は分岐予測がTAGEになったことである。学会では、Zenで使われているPerceptron予測の方が良い成績を上げているのであるが、AMDの検討では電力なども考慮するとTAGEの方が良い結果であったのであろうか。
その他の改良は、データバスの幅を広げたり、キャッシュメモリの容量を増やしたりというものである。この辺りはシミュレーションで性能の向上とトランジスタ数、あるいは消費電力の増加のトレードオフを行って、十分にバランスを検討しているはずである。それでも、個々の項目の性能改善効果は1~2%で、8つの項目を合わせて15%のIPC(Instruction Per Cycle)向上である。
-

Zen2プロセサのハイライト。主要な8項目のアーキテクチャ改善の合わせ技で、Zenに比べてIPCを15%改善 (出典:このレポートのすべての図は、Hot Chips 31におけるAMDのSuggs氏の発表スライドのコピーである)

次の図は、命令実行のエネルギー効率を示すもので、Zen2では、Zenと同じエネルギーで2倍の命令を実行できるようになっている。しかし、その改善の中で効果が大きいのは7nmテクノロジの採用で、これでエネルギー効率は1.47倍となっている。分岐予測の精度の改善やキャッシュのヒット率の改善や低電力設計法など設計の努力でハードウェアの動作を改善して消費エネルギーを減らしたことで1.17倍、命令の実行に必要なサイクル数が減ったことによるエネルギー効率の改善が1.15倍となっている。このIPCの改善による1.15倍は設計者が努力して実現したものであるので、Designによる改善と言っても良いのではないかと思う。
-

Zen2は、同じエネルギーで、Zenと比べて2倍の命令を実行できる。エネルギー効率改善の内訳は、7nmプロセスが1.47倍、低電力設計が1.17倍、IPCの改善によるものが1.15倍である

この他にHot Chips 31での発表では、Spectreセキュリティーホールの対策や、アーキテクチャ的な機能追加と実行エンジンのマイクロアーキテクチャについても述べられたが、かなり細かい内容であり割愛する。
Zen2プロセサのコアでの大きな変更はL1データキャッシュの読み出し幅が2倍になり、バンド幅がZenに比べて2倍に拡張されている点である。
Core0とCore1を鏡像対称に配置し、それを2段積みして中央の図のように4コアのユニットを作っている。そして、右下の小さい図のように、上下の4CPUユニットの間にCPUダイを接続するInfinity Fabricの物理インタフェースをもっている。AMDはこのチップをCCDと呼んでいる。
-

Zen2ではL1Dキャッシュの読み出し幅が2倍となり、L3キャッシュの容量も16MBとなった。CCDチップには8コアとInfinity Fabricのインタフェースを持つ

7nmプロセスで作られるCCDは74mm2で、38億トランジスタを集積している。サーバ用のRomeではこのチップを8個使うのであるが個々のCCDは非常に小さく、安く作ることができる。
そして12nmプロセスで作られるIOダイは、サーバ用は416mm2で83.4億トランジスタを集積している。一方、Ryzen用のIOダイは125mm2で、20.9億トランジスタでできている。
サーバ用のRomeは416mm2のIOダイに8個のCCDを接続し、64CPUコアのパッケージを作る。ワークステーション用のMatisseは125mm2のIOダイに2個のCCDを付けて16コアのパッケージを作る。なお、RyzenではPCIe 4.0やSATA 6GbpsなどのIOはX570チップ経由のサポートとなる。
このような作り方ができるのは、AMDがInfinity Fabricというチップ間の高速接続テクノロジを持っているからである。そして、今回はIOダイでDRAM接続を纏めて行っているので、プロセサを多数のCCDチップに分散しても、すべてのCPUコアからのメモリアクセスレーテンシが同じになるというメリットも生まれている。
-
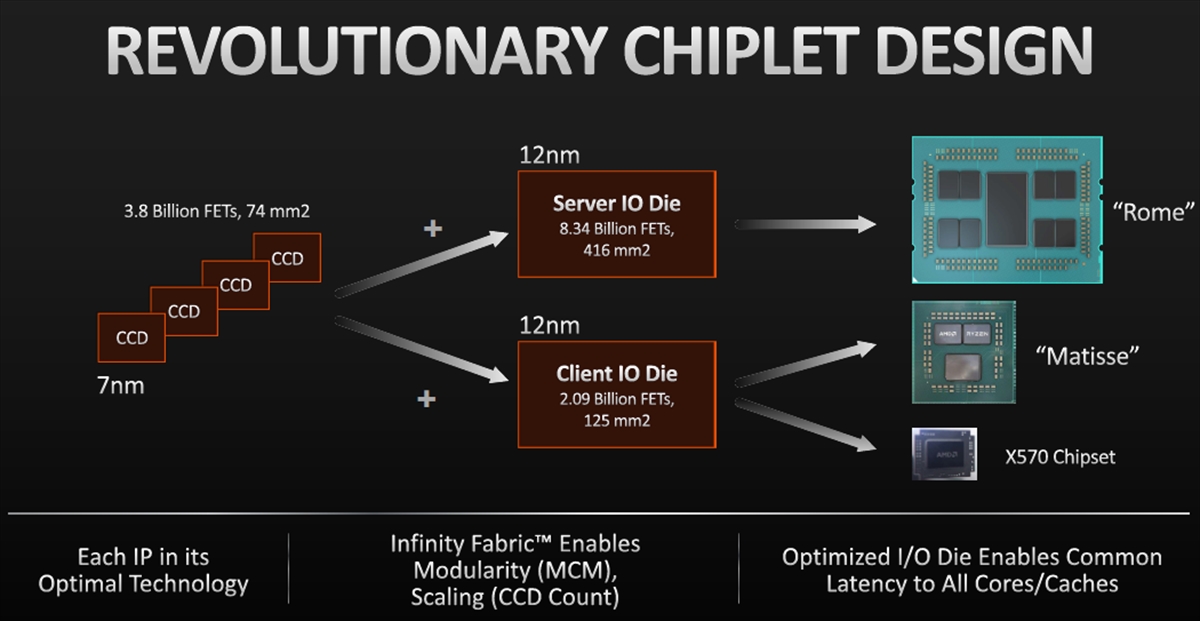
Zen2では74mm2の8コアチップとサーバ用IOダイ、クライアントIOダイの3種のチップの組み合わせで、各種のサーバ用MCM、クライアント用MCMを作る

サーバのRomeの場合、次の図の上下の各4個のCCDチップの間に挟まって描かれている部分がIOダイである。IOダイからはInfinity Fabricのインタフェースで8個のCCDチップを接続できる。それぞれのCCDに8個のZen2コアが搭載されているので、これで64コアのシステムが作れる。
Romeシステムは8チャネルのDDR4メモリを持っており、DDR4-3200 DIMMを使用した場合は204.8GB/sのメモリバンド幅となる。
さらに、中央のIO Controllerのところから8本のInfinity Fabricのリンクが出ており、 8台のRomeシステムに接続したシステムを作ることができる。その場合、64コア×9=576コアのシステムができることになるが、AMDがそこまでの動作を保証するかは別の話になるのかもしれない。
-

Romeサーバはサーバ用IOダイを中心に8個のCCDを接続する。これで64コアのCPUを持つシステムができ、DDR4-3200を8チャネル接続することができる

次の図の左側の図は2個のRomeをInfinity Fabricで接続した図で、2ソケットで128コア、ソケット当たり256MBのL3キャッシュのシステムができる。右側の図は、IntelのXeon/Platinum/Gold/Silver/Bronze CPUを使う2ソケットシステムとEPYCの2ソケットシステムのSPEC CPU 2017の性能を比較した図である。
Intel Xeonの場合は、Platinum CPUを使ってもSPEC CPUは381であるが、EPYCの2ソケットシステムでは、32コアのシステムでもSPEC CPU 2017は431とXeon Platinumの性能を超え、64コアのシステムでは749とXeon Platinumの2倍を超える性能が得られる。
-

EPYCの場合RomeのInfinity Fabricのポートを接続するだけで2ソケットのシステムが作れる。右の図は、各種のグレードのXeonとEPYCの2ソケットシステムのSPEC CPU 2017の性能比較である。EPYCの方が2倍以上性能が高い

まとめであるが、Zen2はZenと比較してIPCが15%向上しており、一定エネルギーで実行できる命令数は最大2倍に改善されている。8コアの小型CPUチップを組み合わせることにより、用途に応じて性能/電力/コストを最適化できる。また、クライアント向け、サーバ向けのCPUを容易に早期に作ることができる。
その結果生まれたのが、第3世代RyzenのMatisseと第2世代EPYCのRomeである。
-

Zen2ではIPCを15%向上し、命令実行のエネルギー効率を2倍に改善した。小さいCPUチップレットとIOダイの組み合わせで、用途別に適したCPUを効率的に商品化した。これがクライアント向けのMatisseとサーバ向けのRomeである















