6月にドイツで開催された「ISC 2019」のPost-K(ポスト京)の状況に関するセッションで、富士通がArmコアのA64FX CPUについて発表を行った。
-

A64FXメニ―コアCPUについてISC 2019にて発表する富士通の次世代テクニカルコンピューティング開発本部システム開発統括部長の清水俊幸氏

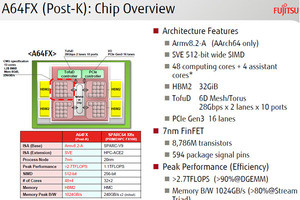
4つに区画で構成されるA64FX
A64FXプロセサの命令アーキテクチャはArmのv8.2命令セットとなっているので、Arm用のアプリケーションが、原則、そのまま動作する。一方、具体的に命令を実行するマイクロアーキテクチャの多くは富士通が独自に開発してきたOut-of-Orderのプロセサコアを使っている。
A64FX CPUは4つに区分されており、それぞれの区画に計算を担当する12個のComputeコアと1個の制御用のAssistantコアを持っている。したがって、全体では52コアあり、その内Computeコアは48個である。そして各コアは64KiBのL1データキャッシュを備えている。
L2キャッシュは8MiBで、全コアに共通となっている。そして、L2キャッシュから容量が8GiBでメモリバンド幅が256GB/sのHBM2メモリにつながっている。これが4つの区画それぞれに存在する。
L1データキャッシュのバンド幅は11TB/sでありB/F比は4、L2キャッシュはバンド幅が3.6TB/sでB/F比は1.3である。そして、HBM2メモリのバンド幅は1024GB/sでB/F比は0.37という設計である。
-

富岳のA64FX CPUのコアはOut-of-Order実行の高性能コアであり、それにHBM2を使う高バンド幅メモリがついている (出典:このレポートのすべての図は、富士通の清水氏の発表スライドを撮影したものである)

A64FXの特徴
A64FXプロセサの1つの特徴は、アラインされていないアドレスからの読み込みであっても、次のキャッシュラインを同時に読み込んでつなげて、その中からアクセスされたアドレスから128バイトの読み込みを行う機能を持っている点である。
キャッシュラインを跨るアクセスは2回のメモリアクセスを必要とする通常のプロセサと比べるとアラインされていないデータの読み込みを高速で行うことができる。
また、「Combined Gather」という機能を持っている。この機能は、間接アドレッシングであちこちからデータを集めてレジスタにロードする場合、128バイトのアラインされた領域に2つのデータが入っていれば、それらを纏めてレジスタに入れる機能で、条件を満たしていれば1つずつロードするのと比べて半分の時間で処理ができる。この機能はコデザインの過程でアプリケーションチームから提案されたものであるという。
-

ロードを高速化する非アラインデータの処理とCombined Load

A64FXプロセサは4命令を並列にデコードし、整数演算器と浮動小数点演算器を2組備えている。これらのユニットは処理するデータが無くてもかなりの電力を消費してしまうことが分かったという。このため、これらのユニットは動作を必要としないときには電源をオフするパワーノブを付けた。
また、HBM2メモリも10%刻みでバンド幅を増減して無駄な電力消費を抑えている。
-

命令デコーダ、整数演算器、浮動小数点演算器は動作状態に応じて電源を切って節電するパワーノブを設けた。また、HBM2メモリはバンド幅を10%刻みで調整して節電する

なお、このあたりの記述は昨年11月のSC18での清水氏の発表の方が詳しいので、興味のある方は参照していただきたい。
製造プロセスはTSMCの7nm FinFET
今回はチップの写真が初めて公開された。上辺を除く部分は4個の同じユニットが田の字状に並んでいる。そして、1つのユニットには13個の縦長のコアが並び、中央にL2キャッシュが置かれている。そして、上辺の部分がTofu-DのNICとPCI Expressのインタフェースである。左右の辺にある4個の張り出し部分がHBM2のメモリコントローラとバッファなどである。
製造プロセスはTSMCの7nm FinFETプロセスである。SerDesやHBM I/O、SRAMなどアナログ的な要素の多いIPはBroadcomのものを使っているようである。
チップの搭載トランジスタ数は878億6000万で、信号端子数は594となっている。
-

A64FXチップはTSMCの7nm FinFETプロセスで作られ、878億60000万トランジスタを集積している

次の図は、左からDGEMM、Stream Triadという2つのベンチマーク、そしてFluid Dynamics、Atmosphere、Seismicの実アプリケーションとマシンラーニングのFP32のConvolutionとINT8のConvolutionの性能を、富士通のFX100スパコンに使用されているSPARC64 XIfxプロセサと比較したものである。
例えばDGEMMではA64FXは2.5倍の性能になっており、その性能向上に効いているのは512bit SIMDとL1キャッシュのバンド幅であるという風に見る。また、地震のシミュレーションでは3.4倍の改善で、効いているのは512bit SIMDとL2キャッシュのバンド幅であると書かれている。
また、マシンラーニングの畳み込みをFP32でやった場合は2.5倍の性能であるがINT8で精度に問題がない場合は9.4倍と大きな性能改善が得られている。
なお、この図ではメモリバンド幅はStream Triadにしか効いていないという図になっており、これではお金をかけたHBM2が泣いてしまう。
-

各種のプログラムでのA64FXとSPARC64 XIfxプロセサとの性能比較。矢印で性能改善の主因を示している

次の図は新しい図で、富岳のA64FXプロセサを、Xeon 8168、NECのSX-Aurora、NVIDIAのV100と比較している。対象は流体シミュレーションの核の部分である姫野ベンチマークである。なお、Xeon 8168は24コアであるので、2ソケットとしてA64FXと同じ48コアにして比較している。
結果は、Xeon 8168 2ソケットが85GFlopsであるのに対して、A64FXは346GFlopsと4倍の性能である。また、SX-Auroraが286GFlops、V100が305GFlopsであり、A64FXはこれらにも勝るプロセサに仕上がっている。
-

姫野ベンチの実行性能の比較。Xeon 8168は2チップで48コアとし、それとA64FX、NECのSX-Aurora、NVIDIAのV100 GPUと性能を比較している。A64FXはXeonの4倍。SX-AuroraやV100を超える性能である

次の図は気象モデルのWRFでの性能比較である。ここでもIntelのXeon 8168は2ソケットで、富岳のA64FXは1CPUのケースとの性能比較である。縦軸は性能に比例するので、A64FX 1チップはXeon 8168 2チップより32%速い。さらに、コードを最適化すると56%速いという結果になっている。
-

IntelのXeon 8168とA64のWRFでの性能比較。Xeon 8168は24コアであるので2チップ、A64FXは1チップでの比較であるが、A64FXの方が32%速く、ソースコードを最適化すると56%速いという結果である

富岳のCPUは、富岳が日本一高い富士山であるように、最高の性能を発揮する。そして、Armアーキテクチャのエコシステムおよび拡大するアプリケーションにより、富士山のように広い裾野をカバーすることを目指して開発された。すでに富士通はA64FXプロセサの量産を開始しており、富岳スパコンだけでなくA64FXプロセサを使う一般製品の開発も進めるという。