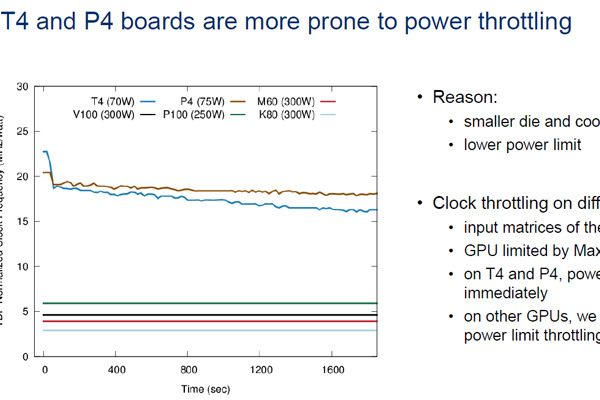
GTC 2019でDell/EMC、テキサス大オースチン校とテキサス大サンアントニオ校の研究者が「MLPerf」を使ってディープラーニングのハードウェアインフラの選び方を理解するという論文を発表した。
-

(このレポートの図は、別の出典を挙げていない場合は、GTC 2019におけるDELL/EMCのRamesh Radhakrishnan氏の発表資料のコピーである)

MLPerfベンチマークはマシンラーニングの学習の実行性能を測るベンチマークである。現在、V0.5というものが使われている。MLPerf V0.5では「イメージ分類」、「オブジェクト検出」、「翻訳」、「リコメンデーション」、「強化学習」の5つのドメインがあり、それぞれのドメインの問題に対するマシンラーニングのトレーニングの性能を測定する。
-

発表を行うDELL/EMCのRamesh Radhakrishnan氏 (筆者撮影)

なお、これまでに登録されたMLPerf v0.5の測定結果はMLPerfのWebサイトに公開されている。
-

MLPerf v0.5のResultsの画面のスクリーンプリント。GoogleとIntelとNVIDIAの登録結果(一部)が載っている。画面右側の数字が各ドメインの測定で得られたスコアである。結果が登録されていると言っても空欄のことも多く、すべての測定が行われているわけではない (出典:MLPerfのWebサイト)

MLPerfには5つのドメイン(Object検出は重量級と計量級があり、これを個別に数えて6ドメインという見方もある)があり、それぞれに使用するAIのモデル、使用するデータセットが決められている。そして、測定結果を評価するPerformance metricが定義されている。
例えばイメージ分類ドメインの場合は、使用するモデルはResnet-50で、データセットとしてはImageNetを使う。そして、性能メトリックとしては、Top-1の分類の精度と学習時間の両方を考慮する。
また、Object検出の場合は、SSD、あるいはMask RNNをモデルとして使い、入力はMicrosoft COCOを使う。そしてMetricとしてはmAPを使うことになっている。
-

MLPerfはImage分類、Object検出、翻訳、Recommendation、強化学習のドメインでの学習性能を測定するもので、使用するモデル、入力データセット、結果を評価するメトリックが決められている

DELL/EMCの論文であるので、評価に使ったシステムは次の図のようなDELL/EMCの製品である。
-

これらのDELL/EMCの製品を使って測定を行っている

次の図のDELLの製品のMLPerf性能を表す棒グラフで、棒グラフの上に書かれているスコアはPascal P100 GPUを基準とした性能である。4本の棒グラフは左から1CPU+2×V100-PCIe、2CPU+3×V100 PCIe、2CPU+4×V100 PCIe、2CPU+8×V100 PCIeという構成のシステムの性能である。
そして4本の棒グラフのグループは、左から、Resnet-50で、モデルとしてTensorflowを使った場合、その隣がResnet-50でmxnetを使った場合である。その次の2つがSSDとMask-RCNNでのオブジェクト検出、次の2つがNMTとTransformerを使った翻訳、右端がNCFを使ったRecommendationの性能のグラフである。
-

4種のドメインのMLPerf性能。それぞれのドメインの結果の4本の棒グラフは、左から1CPU・2V100・3GPU、2CPU・3V100、2CPU・4V100、2CPU・8V100・GPUのシステムの性能

GPUの機能やシステムの設計がMLPerfのスコアに影響を与える。影響を与える項目をリストアップしたのが次の図である。
-

MLPerfスコアに影響を与える項目。GPUのアーキテクチャ、GPUのメモリ量、クロック速度、GPU間のインタコネクトなどが性能に影響を与える

ワークロードの特性の把握では、学習時間と精度の関係を把握する。Googleで測定したTensorflow v1.12では必要な精度を達成するには61エポックを必要とし、1エポック当たりの学習時間は4.42秒であった。一方、NVIDIAが測定したmxnet v1.3.0では、62エポックを必要とし、1エポック当たりの学習時間は4.01秒であった。
なお、XLA Just in Timeコンパイルを使わないと、破線のグラフのようになり学習時間が2倍程度に増えてしまう。
-

Resnet-50を使うImage分類のワークロード特性のグラフ。Mxnetでは62エポック、1エポック当たり4.01秒で学習ができた

必要な精度の確保という点では、翻訳ではBLUEスコア、RecommendationではHit Rate, Object 検出(軽量級)では%mAP、Object検出(重量級)ではQuality Targetを精度の指標としており、それぞれのグラフに描かれた水平の直線が、精度の目標値を表している。学習時間は問題によって1分以下のものから何時間も掛かるものもあるが、4GPUのNVLinkサーバを使えば1労働日以内で学習が完了している。
-

翻訳、リコメンデーション、object検出(軽量級)、Object検出(重量級)のワークロード。グラフの縦軸は精度で、水平の横線が目標とする精度

次の比較はPCIe版のV100 GPUとSMX2版のV100 GPUの性能に与える影響を調べている。左にこの2種類のGPUの諸元をリストしているが、単精度の浮動小数演算でみるとPCIe版は14TFlopsに対してsmx2版の方は15.7TFlopsとsmx2版約12%演算性能が高い。また、GPU間の通信は、インタコネクトにNVLinkを使うSMX2版は300GB/sのバンド幅を持つのに対して、PCIe版は32GB/sに留まる。
しかし、右側の棒グラフにみられるように、この違いの性能への影響は1-5%程度である。
-

V100 GPUのPCIe版とSMX2版の違い。性能差は1~5%であった

Tesla V100で新設された混合精度(16bitの半精度で乗算し、32bitの単精度で加算する)演算を行うTensorコアは非常に高い演算性能をもっており、これを使用することにより、テストしたベンチマークは1.5倍~3.3倍という大幅な性能アップとなった。
-

16bitの半精度で乗算し、32bitの単精度で加算する混合精度演算を高速で実行するTensorコアを使うことにより、学習性能が150%~330%向上した

次の図は、1~8GPUのスケーリングを示すもので、Resnet-50(TensorFlow)とSSDは80%以上のスケーリングが得られている。一方、SSDの使ったObject検出や、2GPU以上のRecommendationはGPU数を増やしても実行時間の短縮は小さい。
-

GPUスケーリング。Image分類では80%以上のスケーリングが得られるが、SSDやNCFではGPU数を増やしても性能の改善は小さい

NVLinkの効果であるが、次の図の青い棒グラフがNVLink有り、灰色の棒グラフがNVLink無しで、ひし形がNVLinkを使ったことによる性能改善を表している。この図にみられるようにNVLinkの使用によりTransformerでは25%、NCFでは16%の改善が得られているが、Image分類のMxnetとObject検出のRNNは7~8%のパーセントの改善である。また、Tensorflowを使うImage分類とSSDでは改善は0%であった。
全体的に通信の速度の学習性能への影響は、あまり大きくないようである。
-

NVLinkの有無での性能差は、翻訳のTransformerのケースが25%、RecommendationのNCFのケースが16%で、その他は10%以下の性能差

次の図は、NVLinkのバンド幅の使用量を示すものでNCFが一番多く、Transformer、RNN GNMTとResnet-50のMxnet版がそれに次いで通信量が多い。前の図をみると、これらのケースでは性能影響が大きいことが分かる。
-

NVLinkの使用バンド幅。通信が多いものは性能影響も多い

次の図はNVLinkとPCIeのトポロジがどう性能に効くかを示すものである。図の上側に示す5種のトポロジでの性能を棒グラフで表している。左端のトポロジは4個のGPUはNVLinkで完全接続し、CPUとはPCIeでつなぐというNVIDIAのDGX-1で使われているトポロジである。その右のトポロジでは、GPU同士の接続は同じであるが、GPUとCPUの接続はPCIeスイッチでまとめて左側のCPUだけに接続している。この構成では右側のCPUとGPUとの通信はUPI(あるいはQPI)を経由して左のCPUに伝えられ、そこからPCIeスイッチを経由してGPUに行くというパスになる。右側の3つのトポロジではGPU間の接続がPCIeであったり、CPUを経由したりしており、NVLink接続に比べてバンド幅が小さい。
次の図に各アプリケーションの実行時間を示すが、右側の構成になるほど実行時間が長くなっている。
-

インタコネクトのトポロジの違いによる学習時間の違い。この5種のトポロジの中では、右に行くほど学習に長い時間がかかる

次の図はCPUの使用率のグラフであり、それぞれに3本の棒グラフがあるが、左から1GPU動作、8GPUでそれぞれのGPUが独立な学習ジョブを行った場合、8GPUで1つの学習ジョブを分担して行った場合を示している。2色に塗り上げられているのは、上側はsystem状態の実行時間、下側はuser状態の実行時間である。
-

MLPerfの実行におけるCPUの使用率2色になっている部分は、上側はSystem状態、下側はuser状態の使用率である

次の図はGPUの使用率のグラフである。左のオレンジの棒グラフはGPUごとに独立の学習を行った場合、右は8個のGPU全部で1つの学習を分担した場合を表す。それぞれの棒グラフが8つに区切られており、これはそれぞれのGPUの使用率を表すものと考えられる。
GPUが学習処理の主体であるので、GPUの使用率はCPUの使用率より高くなっている。8GPUに分散した学習と、各GPU独立の学習を行った場合、どちらのGPU使用率が高くなるかはケースにより異なっており、何が効くのかよく分からない。
-

8GPUで、各GPUが独立に学習を行った場合がオレンジ色のグラフ、全GPUで1つの学習を分担して処理した場合が緑色のグラフで表されている

結論であるが、MLPerfはGPUテクノロジのディープラーニングに与える影響を評価する価値あるツールである。MLPerfで実測性能をまったく同じ条件で比較できるようになり、フレームワークやライブラリの性能改善がドライブされるようになってきている。
CPUの利用率はベンチマークにより大幅に異なる。ディープラーニングのパイプラインによっては、CPUの仕事をGPUにオフロードした方が効率が良い場合もある。
消費電力、コスト、密度、柔軟性の点で、自分の学習ジョブに適したGPUプラットフォームを選ぶべきである。GPU同士の通信が多い場合はNVLinkを使うと最大40%程度性能を改善できる場合がある。しかし、PCIeテクノロジの進化により、この差は縮小する可能性もある。
-

MLPerfはGPUとGPUがディープラーニングに与えるインパクトを評価するには有用なツールである

筆者の感想であるが、この論文には多くの測定結果が含まれており、MLPerfのスコアは有意義な情報である。しかし、システムの選択にあたっては、自分の実行したい処理の特性を把握することが重要であり、そこから、どのようなMLPerf性能をもつシステムが必要かを判定していく必要がある。