筑波大学は、FPGAを本格使用するスーパーコンピュータ(スパコン)「Cygnus」の運用を4月より開始した。
-

筑波大で運用を開始するFPGAを本格使用するCygnusスパコン (写真提供:筑波大計算科学研究センター)

現在では、IntelのXeonなどの汎用CPUとNVIDIAのGPUを組み合わせたスパコンが主流で、米国のSummit、Sierraスパコン、国内最大の産総研のABCIスパコンもこのタイプである。
筑波大はメーカーが開発したスパコンをそのまま購入するのではなく、自分のところの研究成果をとりいれたスパコンをメーカーと共同開発を行うという形のスパコン調達を行ってきた歴史を持っている。
正確に言えば、どこもメーカーの製品をそのまま購入しているわけではなく、いろいろと工夫して自分のところに合うスパコンを共同開発しているのであるが、筆者の印象では、筑波大はスパコンシステムの構成に自分のところの研究項目を付け加える比率が多いと思う。
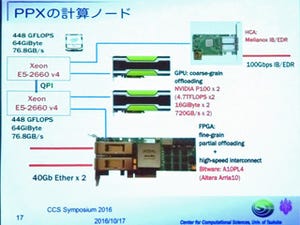
今回発表のCygnusは、一般的なCPUとGPUの組み合わせのDenebノードが46ノードとDenebにStratix10 FPGAを付け加えたAlbireoノード32ノードからなっている。つまり、FPGAのついたAlbireoノードが、このシステムの特徴である。
GPUは高い演算性能と高いメモリバンド幅をもっているが、苦手な処理もある。例えば、条件分岐があり、ひとまとめに実行されるスレッドの中に条件が成立するスレッドと不成立のスレッドがある場合は両方のケースを実行する必要があり、2倍計算時間が掛かってしまう。また、GPUはデータ通信機能を持っていないので、データ転送が出てくるとCPUに処理を依頼することになり、性能のロスが大きい。
これに対してFPGAは自律した通信機構を持ち、処理の実行をクロックレベルで最適化できる。したがって、GPUとFPGAを相補的に用いることで、両者の特徴を生かした効率的な処理が実現できる。

なお、筑波大は、前世代のHA-PACS/TCAスパコンでもFPGAを使って計算ノード間を低レーテンシ、高バンド幅で接続するPEACH2という機構を実装していた。
AlbireoノードのFPGAは、IntelのStratix10 GX2800で、LEが2753Kgate、BRAMはM20Kが合計229Mbit、MLABが15Mbitである。これに外部メモリとして32GiBのDRAMが付いている。そして4つの100Gbpsのチャネルがあり、隣接ノードのFPGA同士が2次元トーラスの形で繋がっている。
なお、Denebノードは、AlbireoノードからFPGAを除いた形になっている。
-

AlbireoノードはGPUと並列にFPGAが付いている。そして、各FPGAからは4本の100GbpsのFPGA間直結リンクが出ている

AlbireoノードのFPGAは、次の図に示すように、2次元トーラス接続となっている。一方、Xeon CPUからHCAを経由してInfiniBandのHDR100/200ネットワークに接続されており、このネットワークはAlbireoノードとDenebノードで違いはない。
-

CygnusはFPGA同士を接続する2次元トーラスネットワークと全ノードをInfiniBandで接続するネットワークという2種類のネットワークを持っている

Cygnusの性能・諸元を次の表に示す。倍精度浮動小数点演算の性能は、Xeon CPU、V100 GPU、FPGAを全部合わせて2.4PFlopsであるが、ディープラーニングなどでは混合精度の演算を使うことにより、もっと高い演算性能として使うことができる。
CPUとGPUの部分はOpenACCやCUDAでプログラミングし、FPGAの部分はOpenCLやVerilog HDLでプログラムすることになる。
-

CPUはXeon Gold、GPUはPCIe接続のV100、FPGAはSratix10で、倍精度浮動小数点数の演算性能はシステム全体で2.4PFlops

FPGAの直接通信をサポートするため、OpenCLにwrite_channel_intelとread_channel_intel機能を使用したモジュールを開発し、これらを呼び出すことにより、FPGA間で通信ができるようにした。次の図の右側のグラフの青い線がOpenCLの通信関数の性能であるが、オレンジの線のInfiniBandを経由する通信に比べて小さいデータサイズの場合でもバンド幅が大きく、最大バンド幅も大きい。
-

FPGA間のデータ伝送を行う関数を利用したOpenCL記述例とFPGA直結接続とInfiniBand接続の性能比較

OpenCLでGPUとFPGAの間のデータ転送を行う関数も作成した。その性能を次の図に示す。一番バンド幅が大きいのがFPGA→GPUのDMA転送の場合、その次がGPU→FPGAのDMA転送のグラフである。そして、一番立ち上がるの遅いのがCPUを使って転送した場合である。また、DMA転送の場合はGPU→FPGA転送のレーテンシは1.44μs、FPGA→GPU転送のレーテンシは0.6μsであるが、CPUを使うと17μsと20μsと1桁以上長い時間が掛かる。
-

GPUとFMA間のデータ転送性能。DMAでの転送はCPUを使う転送に比べてレーテンシが1桁以上短い

アプリケーションの例であるが、宇宙の初期天体生成シミュレーションでは、点光源からの影響のシミュレーション(ARGOT法)と空間的に分布した光源からの影響をシミュレーション(ART法)する必要があるが、前者はGPUで計算し、後者はFPGAで計算するのが効率が良い。
-

宇宙の初期天体の生成シミュレーションでは、点光源からの輻射の影響と広がった光源からの輻射の影響をシミュレートする必要がある。前者の計算にはGPUが適しており、後者の計算にはFPGAが適している

次のグラフは拡散光の計算の性能を比較したものであるが、FPGAで計算させた場合は1000Mメッシュ/s以上の性能が得られているが、CPUで計算させると28コアを使っても、せいぜい200Mメッシュ/sと5倍以上の性能の違いがある。P100 GPUを使って計算させると、メッシュサイズが小さい場合はCPUと同程度の性能で、メッシュサイズが大きくなると性能は上がるが、128×128×128の場合でもFPGAとGPUは同程度の性能である。ということで大きいメッシュサイズでも小さいメッシュサイズでも高い性能を示すFPGAが最も優れている。
-

FPGAで拡散光源の計算をすると小さいメッシュサイズから大きいメッシュサイズまで1000Mメッシュ/sを超える性能が得られる。しかし、GPUではメッシュサイズが大きい場合はFPGAと同程度の性能が得られるが、メッシュサイズが小さいと性能が低くなってしまう

CygnusはGPUとFPGAという2種類のアクセラレータを積極的に使うスパコンである。倍精度の浮動小数点数演算性能は2.4PFlopsであるが、FPGAを使って様々な精度の演算ができる。したがって、GPUとFPGAの相補的な利用により、高い演算性能と効率的な並列処理を実現できる。
OpenCLでFPGAを利用できる環境を作成しており、計算宇宙物理、気象、生命科学、AIなどの幅広いアプリケーションに対応していく予定であるという。
-

CygnusはGPUとFPGAのアクセラレータを持つスパコンであり、両者を相補的に利用することで高い演算性能と効率的な並列処理が実現できる。今後、計算宇宙物理、気象、生命科学、AIなどの幅広いアプリケーションに対応していく予定

FPGAとGPUの双方のアクセラレータを持つスパコンは世界で見てもほとんどなく、筑波大のCygnusでどのようなアプリケーションが効率的に動作するようになるのか、今後、このような両方のアクセラレータを装備するスパコンが増えていくのか興味深い。