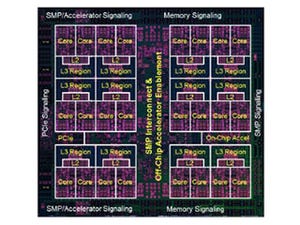
次の図はDPUチップのメモリ階層を示すもので、16PEのクラスタごとに8KBの命令メモリと16KBのデータメモリがあり、96個のレジスタがある。これは1PEあたりにすると、命令メモリは512B、データメモリは1KB、レジスタは12個である。
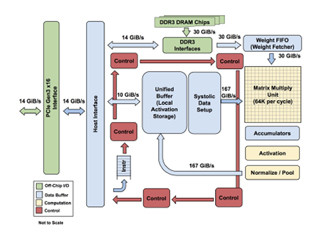
そして、メッシュネットワークのスイッチがあり、スイッチの制御を行う1.5KBの命令メモリが付いている。このスイッチからSonicsのAXI4 NOC(Network on Chip)に128bitのバスで繋がっている。AXI4 NOCから4つのHMC 3D積層DRAM、2ポートのDDR4 DRAMが接続され、さらに16レーンのPCIe3.0がでている。
また、AXIバスには、プログラムのロード、ランタイムの再構成、チェックポイントの作成などを行う小規模なホストプロセサと、そのセキュアな命令メモリが付いている。
なお、DPUは、GPUやGoogleのTPUとは異なり、大きなホストプロセサは必要とせず、推論や学習などの処理はDPUだけで実行することができるようになっているという。

|
|
DPUのメモリ階層。ローカルレジスタ、命令メモリ、データメモリがスイッチにつながり、スイッチからAXI4 NOCに接続されている。そして、AXI4の下には4個のHBM2、2ポートのDDR4 DRAM、16レーンのPCIe3.0が繋がる |
アリスメティックユニットは8ビット、16ビット、32ビットの整数演算ができ、一部の64ビット演算もできるようになっている。そして、8ビット演算は2演算を並列に実行できる。当然、ソフトウェアを使えば任意の精度の計算が行えるし、エミュレーションで浮動小数点演算も行える。浮動小数点演算結果の正規化のためにLeading Zero Countの機能をハードウェアで実装している。
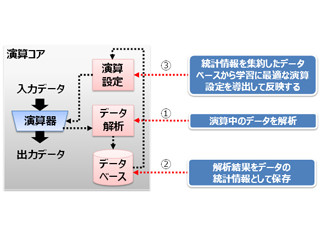
ニューラルネットなどをプログラムする場合は、個々のPEレベルでプログラムするのではなく、2Dメッシュに接続される積和演算、非線形の活性化関数などのエージェント群とその接続をWave Computingのツールフローでプログラムする。入力はLLVMを生成できる任意の言語で書くことができる。ほとんどすべてのプログラム言語はデータフローグラフにコンパイルでき、DPUのエージェントをプログラムするのに使えるという。
ツールは、タイミングクリティカルなパスを近くにまとめて配置する。一方、それほどクリティカルでないパスは配置の制約を緩める。このようなコンパイルを行うためには、コンパイラは、計算、通信とメモリアロケーションを把握してPEの位置、変数の格納方法、スイッチネットワークのスケジュールを決めることが必要になる。 Wave Computingのコンパイラは、グラフを効率よくハードウェアにマッピングし、並列に実行できる部分を最大化する。ここが一番難しい部分で、これが出来てしまえば、ランタイムは簡単であるという。
次の図の背景に描かれているのはデータフローグラフで、左の箱の中にはPE0-15の命令が縦に書かれている。この命令が1つのクラスタに含まれる16個のPEに供給される。
細かくて文字は読めないが、オレンジの命令は演算やメモリアクセス命令で、黄色の命令はPE間でデータを転送する命令で、白はNOP命令である。大雑把にいうと、1/6かそれ以下の命令スロットが演算、あるいはメモリアクセス命令である。ということは、この例では、実効の演算性能はピークの10%-15%程度と思われる。

|
|
背景に描かれたグラフがハードウェアにマップされ、各PEの命令が生成される。そして、各PEの命令メモリにロードされて実行される |
Wave Computingは、5年に渉ってマッピングツールを改良し、人間がやるより良い結果が得られるまで改良してきた。その結果、このツールは理想に近い95%の命令発行スロットを埋めることが出来るようになっているという。
面白いアプローチであるが、ディープラーニングチップは、NVIDIAやGoogleのような大手に加えて、Wave Computingを含めて何社ものスタートアップが開発を行っている激戦区でどこが勝ち残るのかは、まだ、分からない。