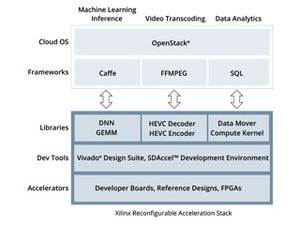
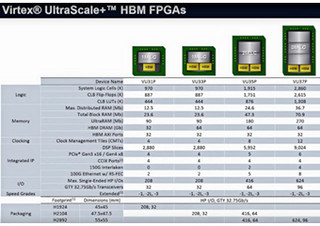
米Xilinxは3月13日(米国時間)、機械学習用アプリケーションを構築するために、新たに「reVISION」というソフトウェアスタックを提供することを発表した。これに先行して2月に記者説明会が開催されたので、これを元に御紹介したいと思う(Photo01)。

|
|
Photo01:主に説明を行われたSteve Glaser氏(SVP, Corporate Strategy & Marketing Group)。ちなみに技術関係の細かな説明を担当されたのはNick Ni氏(Sr. Product Manager, Embedded Vision & SDSoC)であった |
Xilinxは2016年11月に、クラウドコンピューティング向けの機械学習向けスイートとして「リコンフィギュレーション可能アクセラレーションスタック」を発表しているのは既報のとおり。これはクラウドコンピューティング向けということでも分かるとおり、クラウド側の処理に向けたソリューションである。縦軸に業種、横軸にロケーションをとってこれを示すと、Photo02で水色に塗られた部分が。このリコンフィギュレーション可能アクセラレーションスタック向けのターゲットである。逆に、エッジの部分に関してはこれまで"これ"といったソリューションをXilinxは提供してこなかった。

|
|
Photo02:エッジは要するに最終製品向けである。ここはコネクテッドデバイスとは言っても、そう太い回線があるわけではないので、あくまでも最終製品の中で処理をしないといけない(Alexaの様なソリューションはここでは使いにくい) |
ただ、そもそもエッジデバイスに関して言えばXilinxはすでに顧客にがっちり食い込んでいる(Photo03)。したがって、適切なソリューションさえ提供できれば、こうした顧客は既存のハードウェアを生かして機械学習の機能を簡単に組み込める余地があることになる。ということで、3月13日に発表されたのがこうしたエッジデバイス向けの機械学習用ソリューションとなるreVISIONである(Photo04)。

|

|
|
Photo03:例えばADAS向けの自動車用カメラ向けにはすでに85車種で採用されているとする |
Photo04:reVISIONは、ある意味「リコンフィギュレーション可能アクセラレーションスタック」と対を成す存在である |
reVISIONは名前の通り、まずは画像をベースにした機械学習向けのフレームワークである。ではその画像向け機械学習でどんな用途に現在使われ、次世代にどんな用途が想定される/求められているか、というのがこちら(Photo05)。

|
|
Photo05:拡張現実とかHUDはあまり機械学習とは関係ないが |
例えば防犯カメラを例に取れば、今はカメラ映像をそのままホストに送り出すだけなのが、これからは特徴とか動きから問題がありそうなシーンを検出して送り出す、というニーズになりつつあるのはご存知の通り。こうした次世代のアプリケーションでは、機械学習による自律システムを構築することが求められている(Photo06)。ここでのXilinxのメリットはPhoto07の様になる。このうち、8bit以下の推論、についてちょっとだけ補足しておきたい。

|

|
|
Photo06:というよりも、自律システムが求められ、そのための方法論として機械学習が一番有力視されているというか、すでに実装を始めているというほうが正確かもしれない |
Photo07:再構成可能とか接続性に関してはこれまでも説明されてきたことで新しい話ではない |
機械学習の主流が「CNN(Convolutional Neural Network)」というのは知られているとおり。Convolutionは畳み込みの処理で、実際にはCNNでは畳み込み層と全結合層を幾重にも重ね合わせる形で構築されている。問題はこの際の精度である。この先、さらに研究が進んでゆくとひょっとすれば精度を上げたほうが有利、という話も出てくるかもしれないが、現時点ではデータの精度は8bitもあれば十分、という結論が出ている。そもそも入力が映像だったりするとRGBの24bitという話になるが、CNNではこれをまずJPEGなどと同じくYUV(輝度と色差)に分解し、このY(輝度)に対して演算することが多い。この場合入力値は8bitであり、また内部的に演算精度を上げるよりは、むしろ畳み込みや全結合の層数を増やしたほうが、最終的な精度が上がるという研究結果がほとんどである。こうなるとGPUなどでサポートするFP64やFP32、FP16ですらオーバーキルであって、8bit Integer(INT 8)で精度的には十分賄える。モノによっては8bitでもまだ多く、8bit未満でも推論には十分、なんて話もあったりする。こうなってくると8bitの倍数での演算ユニットしか持っていない汎用CPUや、もっと粒度の高いGPUよりも、極端な話1bitの演算回路ですら構成できるFPGAの方が効率的にずっと有利、という話がある(もちろん実際はFPGA内部のDSPユニットの精度である程度粒度は大きくなるのだが)。というわけで、演算の精度を汎用CPUやGPUよりずっと下げて、その分演算器を多量に構成出来る点がFPGAのメリットと言っている訳だ。