



6ワークロード データアプリケーション編【2】 NTTデータ
データ利活用を進める中で必要なさまざまなワークロードのうち、もっとも概念を理解しづらいのがデータアプリケーションだろう。しかし知れば知るほど、データアプリケーションこそデータ民主化の鍵となるワークロードであることに気づくはずだ。
今回はSnowflakeのエリートサービスパートナーであり、多様なプロダクトやソリューションを数多くの組織に導入してきたNTTデータでData&Intelligence事業部 データマネジメント統括部 ソリューション担当 課長代理として活躍するかたわら、Snowflakeのユーザーコミュニティでもコンテンツを発信し存在感を増す渋谷 亮太氏に、データアプリケーションがいかにしてデータドリブンを加速していくのか余すところなく解説いただこう。
解説者:株式会社NTTデータ Data&Intelligence事業部 データマネジメント統括部 ソリューション担当 課長代理 渋谷 亮太氏
Twitter:@ryotas_data
Snowflakeの6ワークロードのなかで、最もイメージしづらいのが「データアプリケーション」ではないでしょうか。他のワークロードと異なり、あまり一般的な言葉ではありません。だからこそ少し軽視される、もしくは避けて通られてしまうことも多いように感じますが、筆者はこのワークロードこそSnowflakeの最も大きな特徴であり、データドリブンな世界を目指す上での鍵になるのではないかと考えています。本記事では、データアプリケーションとは一体何で、どのような価値を持っているのか、筆者の考えを実例とともにお伝えします。
DXのために必要なのは「データ分析」だけではない
データ活用の取り組みというと、まずは社内データの収集やデータ分析を実施する、というステップから始まります。勘と経験がものを言う状態から、まずは社内にちらばったデータを収集・蓄積したうえで、それを分析・可視化することは、データドリブンな経営を目指す上で非常に重要なステップであり、それを行うだけでも様々な困難が待ち受けています。
しかし、言うまでもなく分析はそれだけでは観測の一手法でしかなく、どんな精密な機械学習モデルも、美しいダッシュボードも、それだけで社会や顧客に価値を届けることはありません。価値をもたらすのは、サービスや製品、つまり分析ではなく、その企業の本来的な業務です。
筆者もこれまで、様々なお客様にデータ分析基盤のご提供をさせていただいていますが、この3年ほどで明らかにお客様の求めるもののステップが進んできていると感じます。少し前はとにかくまずはデータを分析したい、という声をよく聞きましたが、最近は既にデータを集めて分析はできるようになってきて、PoCで結果も出てきている、だからこそその成果を業務に活かしたい、業務にデータを活用して変革を起こしたいという声が非常に大きくなってきていると感じています。つまり、データ分析の先として業務の変革、DXを起こそうという機運が高まっているのではないでしょうか。
-
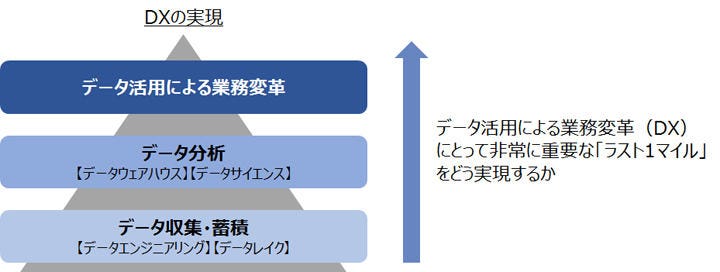
(図)データ活用によるDXの実現への道筋

データを使って価値を届ける「データアプリケーション」
それでは、単なる分析を超えて、データを活用して顧客や社内に価値を届けるためにはどうすれば良いのでしょうか。
一つのやり方として考えられるのが、社員が日常的に利用する業務システムにデータ活用を組み込み、自然と業務のなかでデータを活用する、ということです。これまでの業務システムはどちらかというとデータを生み出す存在、つまりデータの源泉で、データの源泉を上流としたら、データウェアハウス(DWH)などのいわゆる情報系/分析系システムはデータの利用、つまり下流にあたることが一般的でした。しかし、データを分析して終わりではなく真に業務に活用していくためには、上流と下流の区別をなくし、データ活用を中心に業務を行えるようなシステムが作られて行く必要があります。これがData-intensive(データ主導型)なシステム、「データアプリケーション」であり、これこそがDXの鍵ではないかと筆者は考えています。
たとえば、何らかの保険商品を売るということを考えてみます。従来の手法では、カタログを元にした説明で営業を行い、契約結果をシステムに投入し、その結果を使って専門家が保険料率等の高度な計算をするという流れになります。これがデータアプリケーションを使った業務では、保険対象の人や物についての様々な情報を元にした分析結果を用いて、より最適な商品を提示することができ、さらに進めば個々の顧客に保険料率等が最適化された商品の営業を行うことができるようになってきます。このような循環で業務が行われることこそがデータドリブンであり、この循環を作ることができるのが、データアプリケーションと言えます。
-
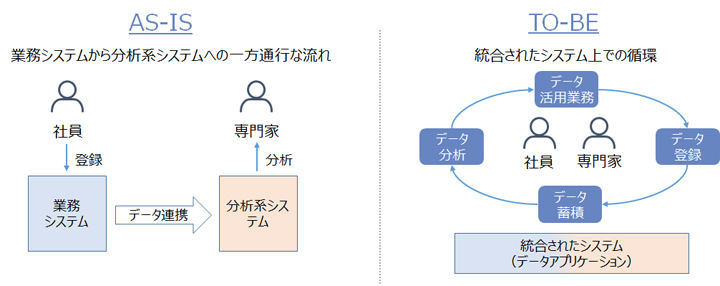
(図)データアプリケーションによって作られるデータドリブンの循環

データアプリケーションは何が難しいのか
データアプリケーションが理想的であるとしても、読者の皆様もご存知の通り、業務システム(上流)と分析系システム(下流)の統合は非常に困難が多いです。
分析系システムがこれまで対象としてきたのが、少人数が試行錯誤のなかで精度を高めていく作業である一方、業務システムは全社員が日常業務のなかで即時に参照・登録するような利用が主です。使うデータは確かに同じかもしれませんが、その使い方には大きな違いがあります。その両方に同時に対応し、しかも互いに悪影響を出さないことは技術的に大きなハードルがあります。もちろん、信頼性や性能の問題もあります。
分析系システムに比べて業務系システムの利用者数は圧倒的に多く、その業務においては即時に利用できる必要があります。分析が1日止まることに比べ、全社業務が1日止まることの直接的な影響の大きさは計り知れません。そのためシステムに求められる信頼性は非常に高いものとなり、必然的に運用コストが高くなります。
また、利用者数の違いや用途の違いは求められる性能にも大きく関連します。分析系システムと業務システムではスループットやレスポンスと言った性能要件が大きく異なり、その両立は非常に難しいものです。
このような問題意識から、これまで分析系システムを直接的に業務で利用することは行われて来ておらず、データを用いた業務があっても、固定的なレポートや分離されたデータベースなどを作成して対応してきました。
Snowflakeでデータアプリケーションは実現可能か
Snowflakeは、前述の3つの問題をすべて解決し、業務システムと分析系システムを統合できる可能性を秘めたソリューションと言えます。まず、Snowflakeの大きな特徴の一つである、マルチクラスタ・シェアードデータ構成によるコンピューティングリソースの分離が大きく寄与します。
Snowflakeは利用用途ごとに独立した仮想ウェアハウスというコンピューティングクラスタを立ち上げることが可能です。複数立ち上げた仮想ウェアハウスが全く同じデータに対し、完全な一貫性を持って同時に参照・更新することができます。これはまさに、データは同じで利用用途や利用ユーザが異なるというデータアプリケーション最大の問題が解決できるということです。
その上で、信頼性については、Snowflakeはノード障害が発生してもダウンタイムがなく、アベイラビリティゾーン(AZ)障害時も業務継続可能なアーキテクチャとなっています。さらにデータベース複製(レプリケーション)の設定さえすれば、クラウドやリージョンを超えたディザスタリカバリ(DR)が可能と、非常に高い業務継続性も持っています。ユーザによる仮想ウェアハウスのスケールアップ・ダウン等の作業はもちろん、バージョンアップ等のメンテナンス時もダウンタイムが全くないので、24時間365日利用し続けることができます。これらは全く複雑な操作や運用負荷なく動作する、Snowflakeに標準的に備わっている非機能特性です。
また性能については、Snowflakeは大量データを処理するということはもちろん得意です。一方、正直に言って、リクエスト数が多くレスポンスが重視されるような業務のワークロードはそこまで得意ではありません。しかし、ニアリアルタイムでIoTデータを取り込むためのSnowpipe(※1)や、半構造化データをネイティブに解釈する機能、さらにはオートスケールや優秀なキャッシュ機能によって、一定の範囲の業務用途において非常に良い性能を出すことが可能です。現段階では、業務システムのうちの一部の領域をSnowflakeに寄せる、ということが最も現実的と言えるでしょう。ただし、検索最適化サービス(※2)など、レスポンス性能を向上させるための機能が追加されてきており、筆者は今後この方面での機能強化を大いに期待しています。
(※1)Snowpipe:継続的に細切れに到着するデータを効率よくニアリアルタイムでロードするための機能。
(※2)検索最適化サービス:Search Optimization Service。大量のデータからピンポイントで少数のデータを取得するようなワークロードが高速化される。インデックスのようなもの。
-

(図)データアプリケーションを実現するための課題とSnowflakeにおける対応

事例:Snowflakeで実現するデータアプリケーションの世界
ここまで、データアプリケーションという概念に対する筆者の考えとSnowflakeでなぜそれが実現できるのかという親和性を説明してきました。一つの事例として、NTTデータが提供する、「iQuattro®」というデジタルサプライチェーンマネジメントシステム(デジタルSCM)を中心としたビジネスコラボレーションプラットフォームをご紹介します。実は、このサービスのバックエンドには、すでにSnowflakeが稼働を始めています。
製品の生産から販売までの全てのプロセスを管理して、最適化を行うサプライチェーンマネジメント(SCM)の考え方やそのシステムは古くから存在しますが、不確実性の増す現代のグローバル環境のなかでは、柔軟性を高め、かつ付加価値を創造していくことのできる新しいSCMが求められてきています。分散化された関係企業やIoTデバイスから、一元的にデータを収集・管理するのはもちろんのこと、そのデータを活用して様々なコラボレーション業務を行っていくのがiQuattro®の提供するデジタルSCMの姿です。デジタルSCMが実現すれば、複雑なサプライチェーン上のあらゆるデータが繋がり、そのデータを用いて最速の意思決定を行っていくことが可能となります。
-
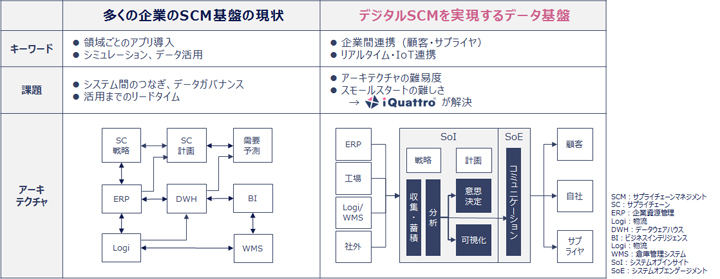
(図)デジタルサプライチェーンマネジメントの目指すアーキテクチャ

iQuattro®がこのデジタルSCMの世界観を実現するうえで、データ蓄積に用いていた従来のDWHやデータレイク製品では、どうしてもリアルタイム性や拡張性がネックとなってしまい、「最速の意思決定」に到達できず、コラボレーションにも支障が出てしまう部分がありました。現在ではSnowflakeが導入され、そのコンピューティングリソースの分離性、高い信頼性、リアルタイム連携の性能が存分に発揮され、デジタルSCMが目指すリアルタイムかつ企業を超えた連携が可能となってきています。
データドリブンへの道
iQuattro®がバックエンドにSnowflakeを使ってデジタルサプライチェーンの領域で新たな価値を提供しているように、Snowflakeを使ったデータアプリケーションはこれから様々な業種・業界で利用されるようになってくると筆者は考えています。どんな業務であっても、DXを達成するためにはデータの取得から活用の循環を高速にまわしていくことは必要不可欠だと考えているからです。
Snowflakeが分析用のDWHやデータレイクという領域を超え、データ登録から活用まで、統合された一つのデータアプリケーションとなったときこそ、誰もが自らの業務をデータに基づいて行うことができる、本当のデータドリブンの世界がやってくるのではないでしょうか。
※本記事はSnowflake、株式会社NTTデータから提供を受けております。
[PR]提供:Snowflake










