3Dイメージ再構成によるCT画像生成の高速処理

CTスキャンデータの3D再構成の論文を発表するHarvard Medical School/Boston Children HospitalのXiao Wang氏
最後に発表されたのは、「Massively Parallel 3D Image Reconstruction」という論文である。第1著者はHarvard Medical School、第2著者はMicrosoftの所属となっているが、研究はPurdue大時代のもので、他の著者も多くはPurdue大の人であり、最終著者になっているSamuel Midkiff氏はPurdue大の教授である。
通常のCTスキャンのイメージは、次の図の左側のようなノイズの多い画像となるが、Model Based Iterative Reconstruction(MBIR)という方法を使うと右の図のような鮮明な画像が得られる。それに加えて、必要なX線の量は1/4で済み、患者の被ばく量を低減できる。
しかし、MBIRでは、3DモデルをCTスキャンして得られる画像と、患者のCTスキャンの画像の違いを最小化するよう3Dモデルの変形を繰り返すという処理を行うため、計算量が膨大という問題がある。
-

通常のCTスキャン画像(左)とMBIR処理で生成された画像(右)。MBIRは,1/4のX線量できれいな画像が得られるが、計算処理が膨大という問題がある

この問題に対して、VoxelをまとめたSuper-Voxelという考え方を導入し、SIMD演算が有効に働くようにした。また、Single-Node-Algorithm(SV)を使ってコアあたり18倍に性能を向上させた。さらに、68コアのKnights Landing(KNL)を使いMulti-Node Massive Parallel Algorithm(NU-PSV)で、これまでの最高性能のシングルノードに比べて83.1倍の性能を実現した。その結果、1024ノードのKNLシステムで9776倍の性能を実現し、従来、1日以上かかっていたMBIR計算を25秒以下に短縮した。
-

Super-Voxelという考え方でSIMD処理を利用できるようにした。また、Single-Node Algorithm、Multi-Node Massive Parallel AlgorithmでSuper-Voxelを並列処理して性能を高めている

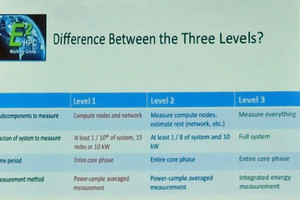
この論文では3レベルの並列性を利用している。第1の並列化はSIMD並列化で同じSuper-Voxelに入っている複数のVoxelを一括処理して性能を向上させている。
第2の並列化はマルチコア・シェアードメモリ並列化で、同じ領域に入っている複数のSuper-Voxelのアップデートを並列に実行して性能を向上させる。
第3の並列化はマルチノード並列化で、複数の異なる領域のアップデートをそれぞれのノードで並列に実行する。
-

SIMD並列化によるVoxelの並列処理、領域(Volume)内の複数のSuper-Voxelの並列メモリアクセス、マルチノードを使って複数の領域のアップデートを並列に処理するという3レベルの並列処理を使っている

過去20年、並列処理による性能向上は1.25×スライス数の向上に留まっていた。しかし、この論文のアルゴリズムにより、ノード当たりの性能が83.1倍になり、システム(1024ノードのKNL)の性能は9776倍になった。これにより、従来は1日以上かかっていたMBIR処理を25秒以下に短縮することができた。
-

過去20年間、MBIR処理の並列化による性能向上は小さかったが、3つの並列性を利用したことで、1024ノードのKNLを使うシステムの性能は9776倍に向上した。これにより、従来は1日以上かかっていた処理が25秒以下で終わるようになった

非線形地震波シミュレーションがGordon Bell賞を受賞
今年のGordon Bell賞は、2番目に発表された「Enabling Nonlinear Earthquake Simulation for 18-Hz and 8-Meter Scenarios」が受賞した。
-

Gordon Bell賞の表彰。賞状を持つ5名が著者であり、左端が発表を行ったHaohuan Fu教授である

18.9PFlopsと過去の非線形の地震シミュレーション(2016年Titanの1.6PFlops)を10倍以上上回る性能を達成しており、他の2つの候補論文よりも高いFlops性能を達成していることから妥当な受賞である。
TOP500の1位のスパコンを使うチームがGordon Bell賞を取るというケースは従来から多く、昨年に続いて中国が太湖之光スパコンでGordon Bell賞を取るのに不思議はない。しかし、TOP500の国別の総Flops数、ランクインしたシステム数で中国が米国を上回り、このGordon Bell賞の受賞を加えて、中国の優位が一段と強固になったという印象である。
来年のSCでは、米国のSummitがTOP500の1位になり、状況が大きく変わるのであろうか?