企業やデータセンターで運用されるシステムは、コンピューティング(データ処理能力) 、ネットワーク(情報網)、 ストレージ (データ保全) の3つの大きな要素で成り立っています。特に、ストレージについては、アクセス・スピードや容量の基本要素に加え、拡張性、堅牢性、永続性、災害対策などが問われ、初期投資、運用コストに直接影響するため、活発な議論がなされます。
本連載では、近年導入が進んでいるオブジェクト・ストレージについて、データの種類と扱い方、それを支える要素技術、適用分野を解説しながら掘り下げたいと思います。
Fast Data(ファスト・データ)とBig Data(ビッグ・データ)
データは、アクセス・スピードと容量の観点から、1つ目の性質としてFast DataとBig Dataに分類することができます。しかし、時間の経過や使用目的に応じて性質を変えていくことも数多く見られ、ある時はスピードが求められますが、時間が経ち、データ処理が進むと、まとまったデータとして蓄積、再利用、分析のしやすさが求められるなど、1種類のデータでも両方の性質を持つことがほとんどです。
話題のニュースがネット上で流れることを例に挙げると、 最初はアクセスが集中するので、かなりのスピードで閲覧できることが求められ、徐々にニュース性が薄れると、検索される頻度も下がってきます。しかし、たまの検索でもそれなりのスピードで読み出せる環境を保つ必要があります。

このデータアクセス要求度合いでストレージ階層が形成され、下表のように表されます。 上層はアクセス速度重視、下層に下がるほどストレージ容量単価、拡張性が重要視されることになります。バックアップはデータ長期保存・緊急時の回復が目的ですので、二度と読まれないことも多く、常にオン・ラインである必要もない場合も多く見られます。ストレージ・システムとしては、階層に関わらず共通する要求項目もあり、各階層で用いられるシステム構成のやり方により、それぞれが特徴づけられます。次に、それらを解き明かして行きましょう。
-
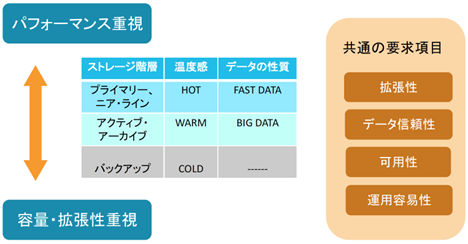
ストレージ階層別の要求

データの管理、 ディレクトリーとフラット構造
次に、データを出し入れする際に必要なデータ管理を行う2種類のファイル・システムについて紹介します。
1つ目は、Tree (木)構造とも言われ、ファイルやホルダーという概念でデータを格納し、枝分かれした状態をデレクトリで管理します。NAS(Network Attached Storage)やSAN(Storage Attached Network)がこれを利用しています。
これに対してデータにIDをつけて、大きなプールにフラットに溜めるだけの管理方法を持つものがオブジェクト・ストレージです。
ディレクトリを持つファイル・ストレージは、Linux(NFS)/Windows(SMB)環境からファイル出し入れし、共有化することができます。ネットワークからFC(iSCSI)を用い、ストレージを独立統合した SANはデータをBlock化し、大容量データベースの高速化に貢献します。しかし、独立したフォルダー間には壁があり、データを参照したり、移動するには、 木構造に沿ったデータの参照、移動の操作が求められます。NAS/SANは 高速化しやすいRAID(後述)と相性がいいためFast Data を扱うストレージとして利用されます。
オブジェクト・ストレージは、木構造を取らないデータの保管方式を用い、各データ(オブジェクト)は、 IDが与えられ、メタデータと共に 同じレベルで分散保存されます。 このメタデータは、カスタマイズして管理することにより、オブジェクトを開くことなく、コンテンツを特定することができるなどの役に立ちます。まさに検索、分類、分析をすることを前提に、データを大きなプールに溜めておくための手法です。Big Data解析のニーズが高まる中、データを孤立させるような フォルダを用いず、どのような属性のデータも均一に見渡せるようにする環境を提供します。
ストレージ・システムの高速化、冗長性、拡張性
Fast Dataを扱うストレージの構成は、SSD(Solid State Drive)または HDD(Hard Disk Drive)をRAID(Redundant Array of Independent Disks)化することで、冗長性を保ちつつ、必要なパフォーマンス・容量を確保します。高速化は、SSD/HDDをストライピングすることでデータ転送スピードが容易に上がリ、これが最大の特徴です。冗長性確保のためには、ミラーリングやパリディ・ドライブを複数用意することで故障時の可用性と再構築を可能にします。ただし、RAID構成を組んだストレージは、運用を継続しながら組み換え・拡張ができません。RAIDを組み直すと、データも入れ直しです。複数のRAIDを並列に用意して、そのロード・バランスに配慮しながら使うことになります。ここでも、各RAID間にはアクセスの壁ができることになります。SSD/HDDが壊れた場合も新しいデバイスと入れ替えて再構築(リビルド)できますが、その間、長時間のパフォーマンス劣化状態での運用は避けられません。
対するオブジェクト・ストレージは、イレイジャー・コーディング(Erasure Coding)と呼ばれるオブジェクト管理、分散配置、データ自動回復機能をもった技術が採用されています。2000年ごろから導入が始まり、インターネット、クラウドの普及とともにアクティブ・アーカイブ階層の主流となりつつあります。日本語に直訳すると、消失訂正符号と訳されるので、非常に違和感がありますが、これによりRAIDの終焉か?と言われるほど強力な冗長性、拡張性、データ堅牢性を享受できます。技術的な詳細は後述します。
イレイジャー・コーディングは、運用しながら増設するだけで、追加した容量分も一つのバケットと見なし、データ分散配置が自動的に始まります。同時に、強力なデータ自動回復機能も常時働くため、デバイスの故障時にもパフーマンスが低下することがありません。
また、面倒なRAIDリビルドも不要です。大量のログデータを集めながら、ある事象に関連する情報を分類、解析などを行う場合、容易に必要な容量を拡張しながら、継続運用できるイレイジャー・コーディング利用のオブジェクト・ストレージはインターネット、Big data時代に最適なストレージです。ただし、RAID 0でストライピングしたほどにはパフォーマンスが上がりませんし、小さなオブジェクト(数十キロバイトの小さいデータ)を扱うのも苦手です。数メガバイト以上のデータ、すなわち写真、動画となると、その威力を発揮します。そこがオブジェクトストレージがプライマリーでなく、アクティブ・アーカイブ分野に最適で、クラウド・サービス分野で普及が進む理由です。
ストレージ階層の要素をいくつか挙げてきましたが、それら特性を簡素化して前出の表に追加すると下記表のようになります。

非構造化データには オブジェクト・ストレージ
Fast Data/Big Data共に、データには、構造化データと非構造化データがあります。構造化データとは、表計算のように行と列の概念があるデータです。集計、比較、分析に適し、高速処理もしやすくなります。アンケートを取る場合に、選択肢を与えデータを定型化して集めるのも一例です。
一方、非構造化データとは、メール、SNS、写真、ビデオ、音声、Webサイトのログ/アーカイブなど、一般に生成される特定の構造を持たないデータです。スマホの普及、Big Dataの処理・分析、IoTによるニーズの高まりでデータ量が急増しているのは、この非構造化データの分野です。
また、非構造化データは、そのサイズが大きくなる傾向にもあります。写真、動画がまさにそうです。データの性質に応じたストレージを使い分けることが理想です。SNSなど、ネット上で提供されるサービスを運用するデータセンターでは、必然的に、非構造化データの処理としてオブジェクト・ストレージが増加することになります。
2017年12月に、ウエスタンデジタルが発表した米国ニューヨークの451 Researchによるオブジェクト・ストレージに関する調査結果では、数十ペタバイトを保有するクラウドサービス会社や一般企業では、非構造化データが半分以上を占め、年率 40?80%で成長、2年後にはオブジェクト・ストレージ導入率は90%に達するとしています。今後、普及が拡大する技術なのです。
著者プロフィール
山本慎一株式会社HGSTジャパン ジャパンセールスディレクター
データストレージ技術とソリューションを提供するグローバル企業ウエスタンデジタルにおいて、オブジェクト・ストレージを中心としたデータセンター・ソリューションのビジネス開発を主に日本で推進。
IBM、日立、 Western Digitalなど、30年以上にわたりストレージ業界に従事。コンシューマー製品からエンタープライズ・ソリューションまで、幅広い分野において製品開発、ビジネス開発、マーケテイングなどの経験を持つ。