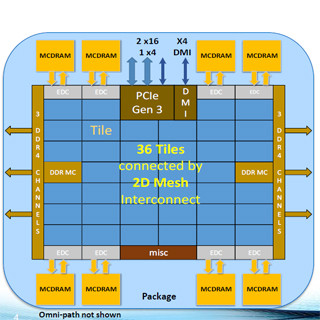
アルゴンヌ国立研究所のNekboneというアプリケーションでは、KNLでは0.38msで実行できたジョブが、E5-2699 v3デュアルコアの36コア、2.3GHzクロックのシステムでは1.22ms掛かり、KNLは4.6倍の性能である。

|
|
アルゴンヌ国立研究所のNeckBoneというアプリでは、36コアのE5-2699 v3 2ソケットと比べてKNLは4.6倍の性能である |
そして、SPECrate2006ベンチマークでは、64(?)コアのXeon Phi 7250は、整数では839、浮動小数点演算では849をマークしている。Xeon E5-2699 v4(22コア、2.2GHzクロクのスコアは877と551であり、整数では若干劣るものの、浮動小数点では、50%あまり上回っている。 しかし、これは3倍程度の68コアのSPECrateの結果であり、1コアではSPECintではXeon E5-2699の1/3程度の性能と思われる。なお、次の図の左側では34Tile と書かれているが、右側の表では7250はKNL 64Cと書かれており食い違っているが、34タイル68コアが正しい。

|
|
68コアのSPECベンチマークの結果とXeonとの比較。整数ではE5-2699 v4に若干劣るが、浮動小数点ベンチマークでは50%あまり高い性能である |
次の図は、横軸に要求メモリバンド幅、縦軸にロード命令のレーテンシを取ったグラフで、MCDRAMをアクセスしている時は、レーテンシはおおむねフラットで、490GB/sでも230ns程度に収まっている。一方、DDR4をアクセスしている時は、80GB/s位からレーテンシが急増している。これはメモリのバンド幅いっぱいのアクセスが来て、渋滞が発生している状況である。なお、赤の線にtraffic to MC-DRAMと書いてあるのは間違いである。

|
|
FlatモードでMC-DRAM部をアクセスした時のレーテンシ(青線)とDDR4部をアクセスした時のレーテンシ(赤線) |
次の図は各種のプログラムについて、データセットのサイズを変えてキャッシュのヒット率をプロットしたもので、労作である。MCDRAMは16GB全体をキャッシュに使うCacheモードで動かしている。
データセットのサイズが16GB以下の場合は、1つだけ80%程度のヒット率のプログラムがあるが、大部分は90%以上のヒット率が得られている。
つまり、大部分のケースでは、MCDRAMのキャッシュが効く。しかし、前のグラフを見て分かるように、MCDRAMのアクセスタイムは、トラフィックが少ない場合はDDR4より遅いので、キャッシュヒットしたからと言って、メモリアクセスが速くなる訳ではない。アクセスが頻繁で80GB/sより大きなバンド幅を必要とするデータのアクセスがキャッシュヒットすればアクセスレーテンシの短縮効果が出るのであるが、このようなケースがどの程度あるのであろうか。

|
|
MCDRAMをキャッシュとして使うCacheモードでのキャッシュのヒット率。横軸はワークロードのデータセットサイズ |
次の図は、MCDRAMをFlatモードで使った場合(実線)とCacheモードで使った場合(破線)の性能比較である。メッシュはデフォルトのQuadrantモードになっている。左のグラフの緑の線のminiGhostは16GB以下の問題サイズではFlatモードの方が性能が高いが、それ以上の問題サイズになるとCacheモードの方が性能が高くなっている。一方、青線のminiFEは、どちらでも大差のない性能である。
右のグラフでは、灰色の線のSNAPではFlatモードの方が性能が高いが、AMGとUMTではCacheモードの方が性能が高い。
ということで、どちらのモードが良いかはアプリケーションの性質に依存しており、やって見なければ分からないということであるようである。

|
|
合計5種のアプリについて、問題サイズを変えて、Flatモード(実線)とCacheモード(破線)の性能を測定している。一概にどちらのモードが良いとは言えない |
次の図はSNC-4モードとQuadrantモードの比較で、 Quadrantモードの値を1.0として、8種のアプリの性能を比較している。6種のアプリではSNC-4モードの方が性能が高いが、逆に性能が低いアプリも2種存在する。

|
|
Quadrantモードの性能を1.0と正規化した8種のアプリの性能。6種のアプリではSNC-4モードの方が性能が高いが、SNAPとMiniDFTアプリでは性能が低い |
KNLのプログラミングに関する本が出版された。チーフアーキテクトのAvinash Sodani氏を含めた3人が著者である。Intelの人が、IXPUGの会場にたくさん持ってきていて、発表者に対して質問した人に1冊ずつくれていたので、筆者も手を挙げて質問して貰ってきた。632ページという厚い本で、まだ、拾い読みをした程度であるが、KNLの構造から、チューニングまで書かれており、KNLのプログラムを書く人には役に立ちそうである。

|
|
KNLの高性能プログラミングの本が出版された |
今後の方向性
今後の方向性であるが、次の図の右の2つのグラフは、コア数の推移とGFlopsの推移である。トランジスタの数は今後も増え続けると見られるので、コア数とFlopsの向上は続く。また、現在は別チップになっているシステムコンポーネントを集積するという流れも強まる。
そこで問題になるのが電力で、電力効率の高い設計、高集積による電力の低減、より賢い電力管理、また、特定機能のハード化で電力を削減することが推し進められることになろう。

|
|
トランジスタ数は増え続けるので、コア数、Flopsの増加は続く。しかし、電力は大問題で、省電力設計がより重要になる |
将来のプロセサは、より並列度が高くなるので、ソフトウェアとしては、スレッド間のロードバランスの改善、データローカリティを考慮したプログラミング、スレッドあたりの使用メモリ容量の低減、グローバル通信の使用を最小化できる処理アルゴリズム、そして、並列化の機会をプログラマに教えてくれる開発ツールの改良が必要になるとのことである。

|
|
将来の並列度の増大に対して、ソフトウェアとして必要になるチャレンジ |
まとめであるが、KNLは、汎用のプログラミングができる高並列なCPUである。将来は、さらに並列度が増していく。このため、アプリケーションの並列化が必須である。ソフトウェアは寿命が長いので、将来のハードウェアの動向をにらんで、どのように並列化するかの選択は重要である。その点でKNLのCPU+汎用プログラミングという方向は、将来に向けて安定な基盤を提供していると述べて、基調講演を締めくくった。

|
|
ハードウェアの並列度は今後も上がって行く。このためアプリケーションの並列化は必須である。しかし、アプリの寿命は長いので、どのように並列化するかの選択は重要である。CPU+汎用プログラミングというKNLのアプローチは、将来に向けて安定な基盤を提供している |