前回の連載では、「平均値の95%信頼区間」を算出する方法を紹介した。この結果に十分な信頼性を得られなかった場合は、何らかの対策を考える必要がある。そこで今回は、サンプル調査の「標本数」と「信頼区間」の関係、ならびに「平均値の99%信頼区間」を求める方法を紹介していこう。
「標本数」と「平均値の95%信頼区間」の関係
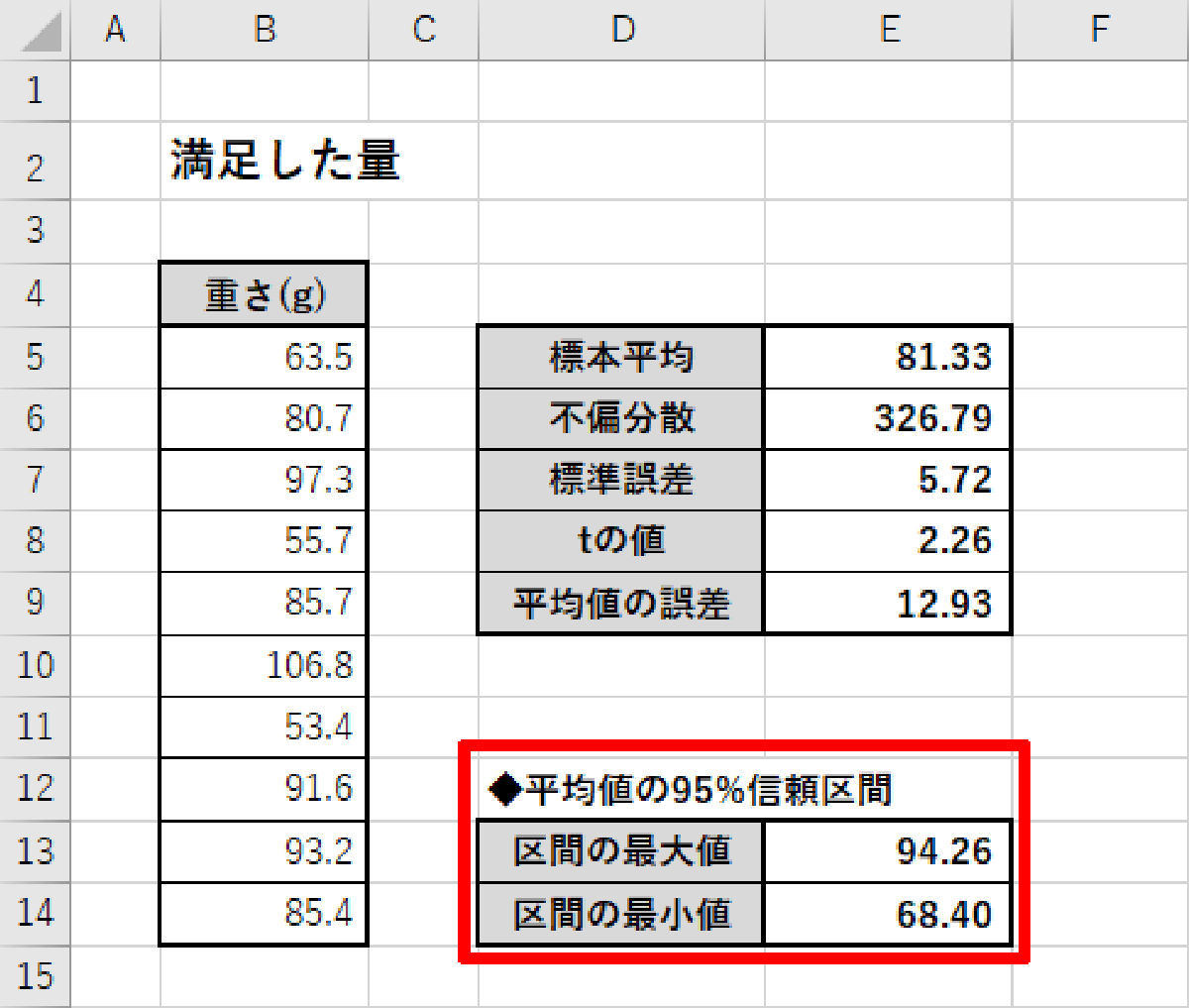
前回の連載で「平均値の95%信頼区間」を求める方法を紹介した。その結果は、68.40~94.26(g)という数値になり、±15%以上もの誤差があるということが判明した。これは、あまり確度の高い「標本平均」とはいえないだろう。
-
平均値の95%信頼区間(標本数10個の場合)

では、「標本平均」をより信頼性の高いものにするには、どうすればよいだろうか? このような場合に一つの対策法として考えられるのは「追加調査」を行うことだ。というのも、サンプルデータの個数(標本数)が十分でないと、「信頼性の低い数値」しか導き出せない傾向があるからだ。
たとえば、前回の調査とは別に、新たに20人の協力者を集って同様の調査を実施したとしよう。この場合、全部で30人分のサンプルデータを収集できたことになる。
-
20人分のデータを追加したサンプル調査

これらデータについて、あらためて「平均値の95%信頼区間」を算出してみよう。
あらためて「平均値の95%信頼区間」を算出
「平均値の95%信頼区間」を算出する方法は、前回の連載で解説した通りだ。復習も兼ねて、もういちど手順をおさらいしておこう。
まずは、標本平均を関数AVERAGE()で算出する。今回の例では、引数に「B5:D14」のセル範囲を指定すればよい。
-
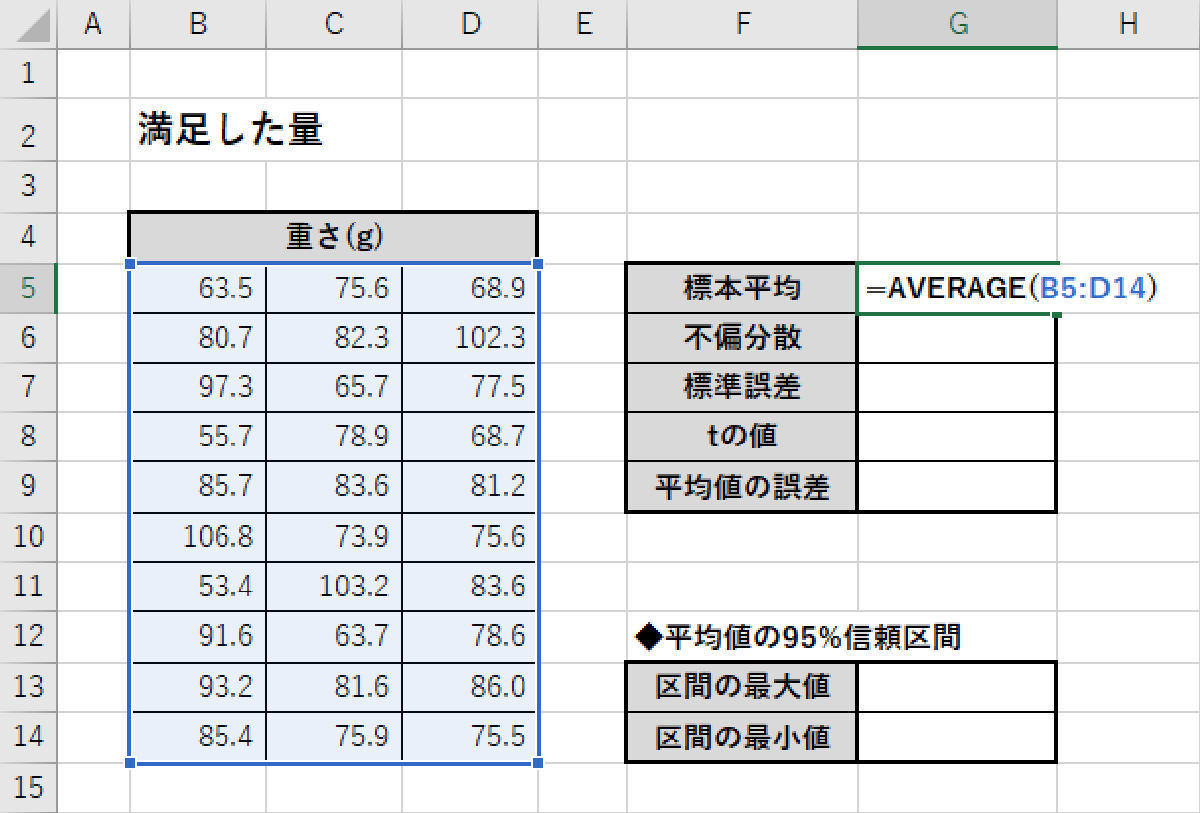
標本平均の算出

今回の例では、「標本平均」は79.85(g)という結果になった。これは前回の調査(81.33)よりも少しだけ小さい数値となる。
続いて、「不偏分散」などの数値も算出していこう。こちらは、関数VAR.S()の引数に「B5:D14」のセル範囲を指定すると求められる。
-
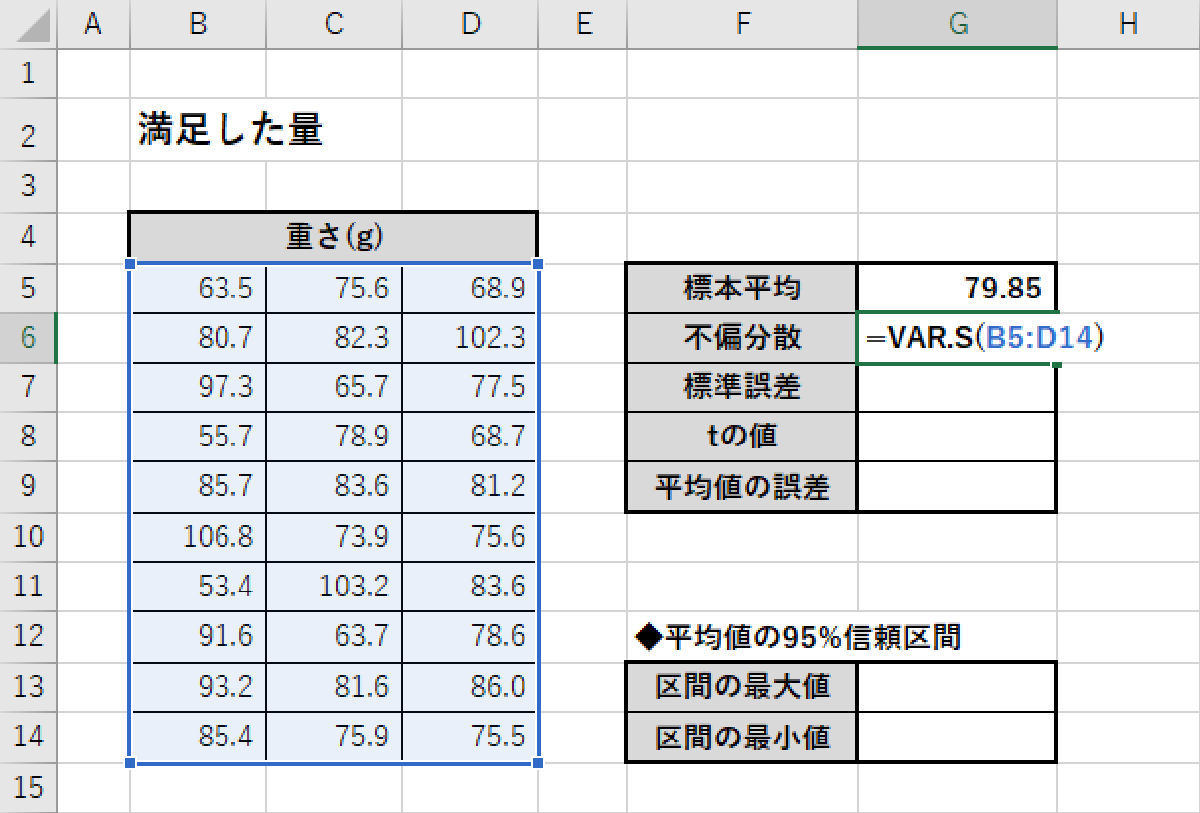
不偏分散の算出

次は「標準誤差」の算出だ。計算方法は前回と同じで(不偏分散/データの個数)の平方根となる。「データの個数」が30個に増えていることに注意しながら数式を入力していこう。
-
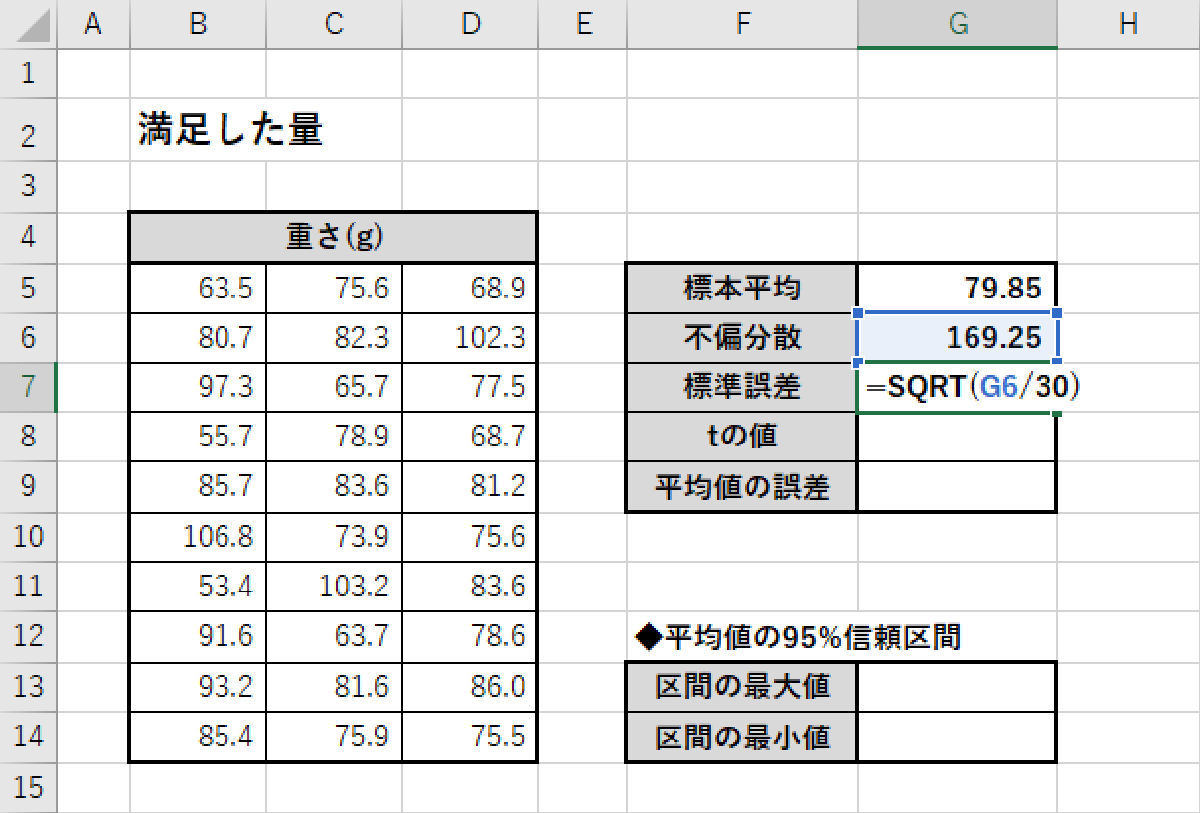
標準誤差の算出

「tの値」を求めるときも、「データの個数」が30個に増えていることに注意しなければならない。今回の例における「自由度」は30-1=29となる。一方、「危険率」の数値は信頼区間の確率95%なので、0.05のまま変わらない。よって、「=T.INV.2T(0.05,29)」と入力すると、「tの値」を求めることができる。
-
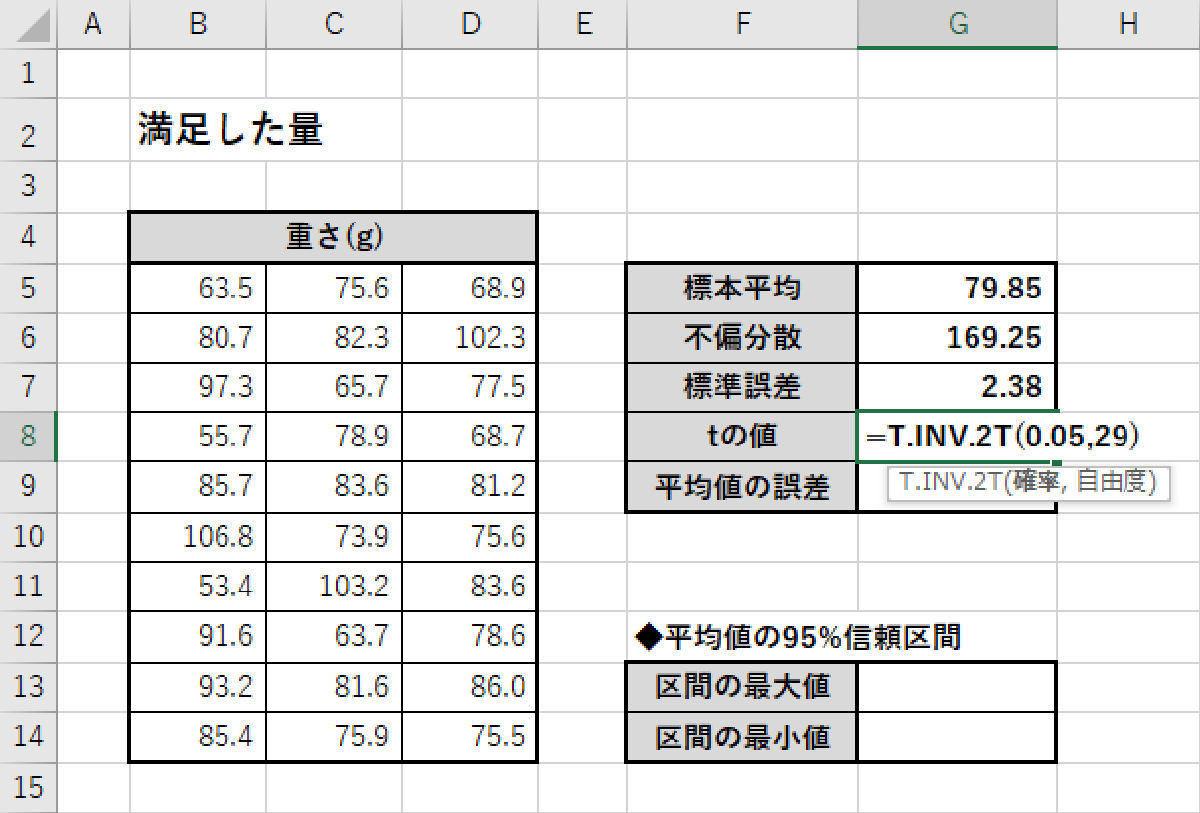
関数T.INV.2T()で「tの値」を求める

続いては、「tの値」×「標準誤差」を計算して「平均値の誤差」を求める。
-
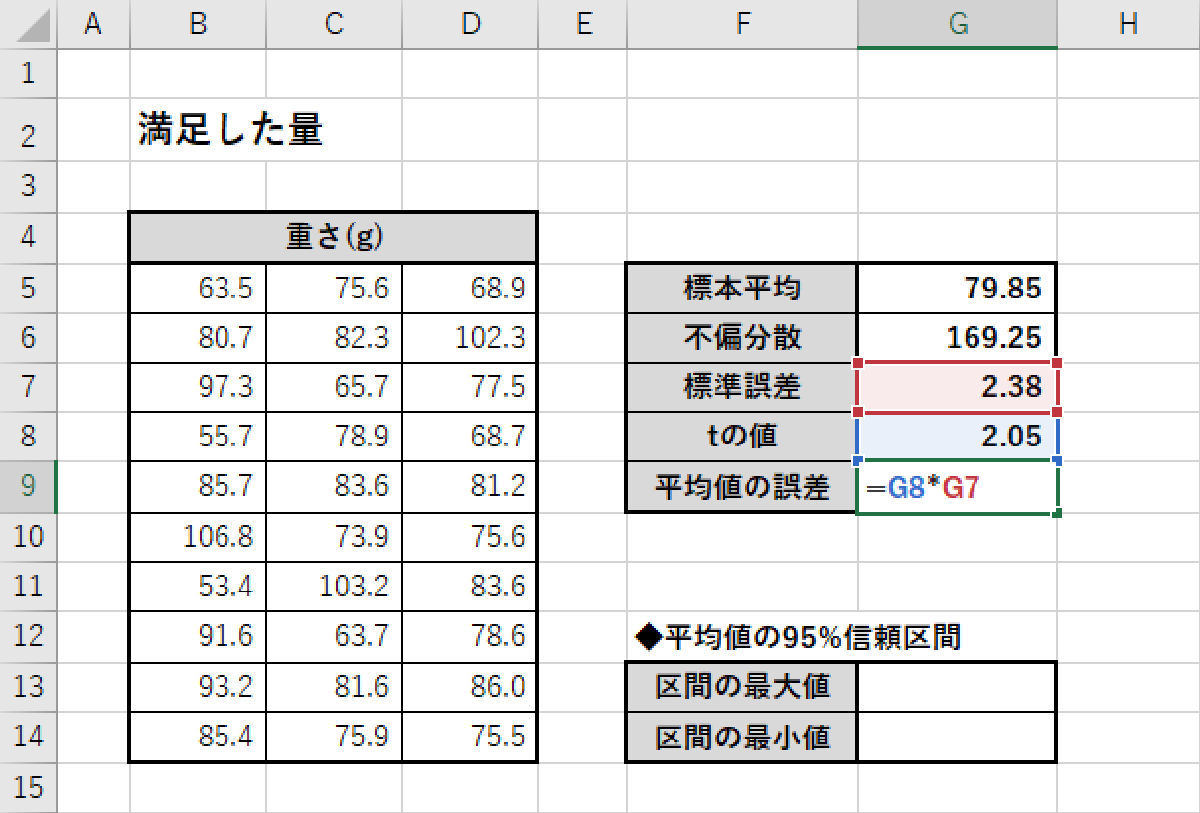
平均値の誤差の算出

この数値を「標本平均」にプラスマイナスすると、「平均値の95%信頼区間」を求めることができる。
-
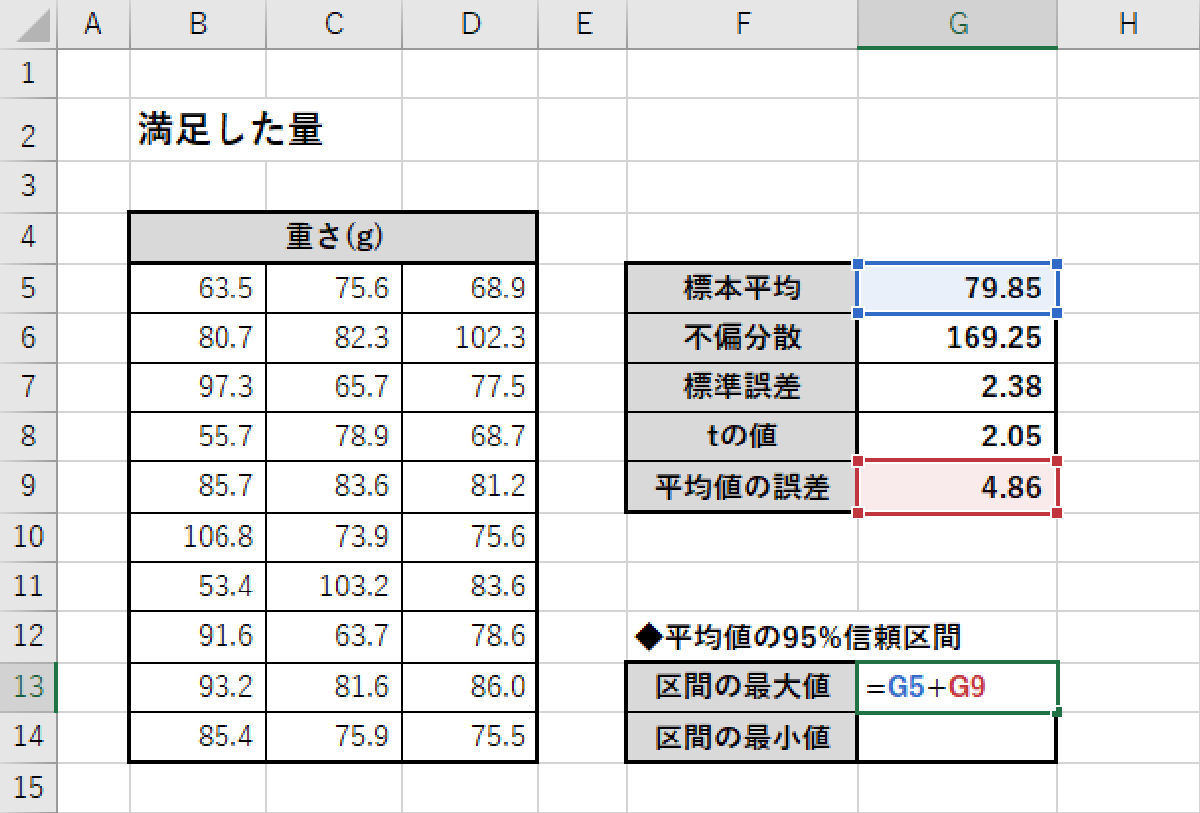
「信頼区間の最大値」の算出

-
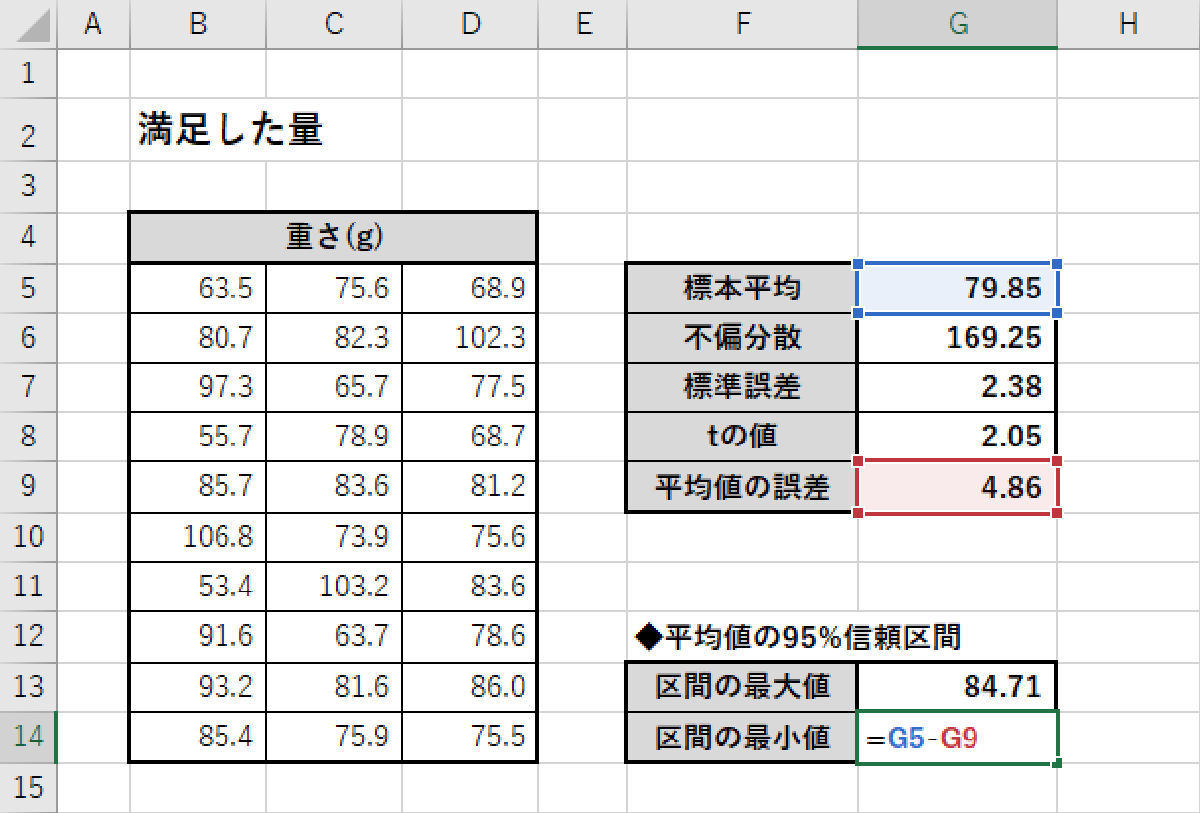
「信頼区間の最小値」の算出

今回の例では、「平均値の95%信頼区間」は75.00~84.71(g)という結果になった。前回の例よりも「範囲の狭い数値」になっていることを確認できるだろう。
-
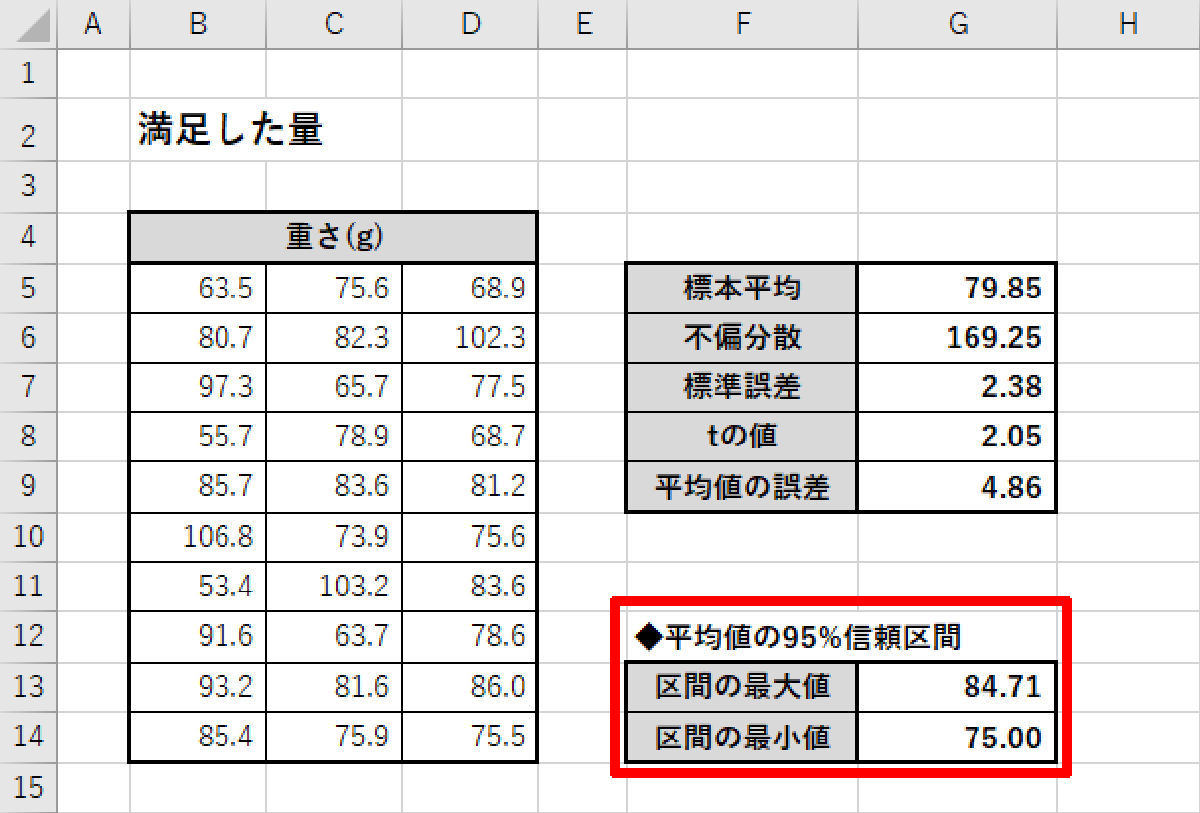
平均値の95%信頼区間(標本数30個の場合)

念のため、前回(10人分)と今回(30人分)のサンプル調査について結果をまとめておくと、以下のようになる。
前回のサンプル調査(10人分)
【標本平均】81.33g 【95%信頼区間】68.40~94.26g (標本平均±15.9%)
今回のサンプル調査(30人分)
【標本平均】79.85g 【95%信頼区間】75.00~84.71g (標本平均±6.1%)
新たに20人分のデータを追加したことで、「標本平均」にプラスマイナスする範囲が約10%ほど小さくなっていることが確認できる。つまり、それだけ信頼性の高い「標本平均」になったといえる。
このように、サンプル調査では「十分な数のデータ(標本数)を集めること」が重要な条件となる。「平均値の95%信頼区間」を算出してみた結果、信頼性の低い数値しか得られなかった場合は、再調査を実施して標本数を増やしてみる必要がある。
ただし、標本数を増やしたからといって、必ずしも「平均値の95%信頼区間」が狭まるとは限らない。状況によっては、「大差がない」もしくは「さらに範囲が広がってしまった」というケースもあるだろう。とはいえ、たいていの場合は、より信頼性のある結果を得られると思われる。
平均値の99%信頼区間を算出するには?
念のため、「平均値の99%信頼区間」についても補足しておこう。信頼区間の確率を99%にした場合も基本的な計算手順は同じである。異なるのは「tの値」を求める部分だけだ。
99%信頼区間の場合、その「危険率」は1-0.99=0.01となる。よって、関数T.INV.2T()の第1引数を0.01に変更すると、「平均値の99%信頼区間」を求めることができる。
-
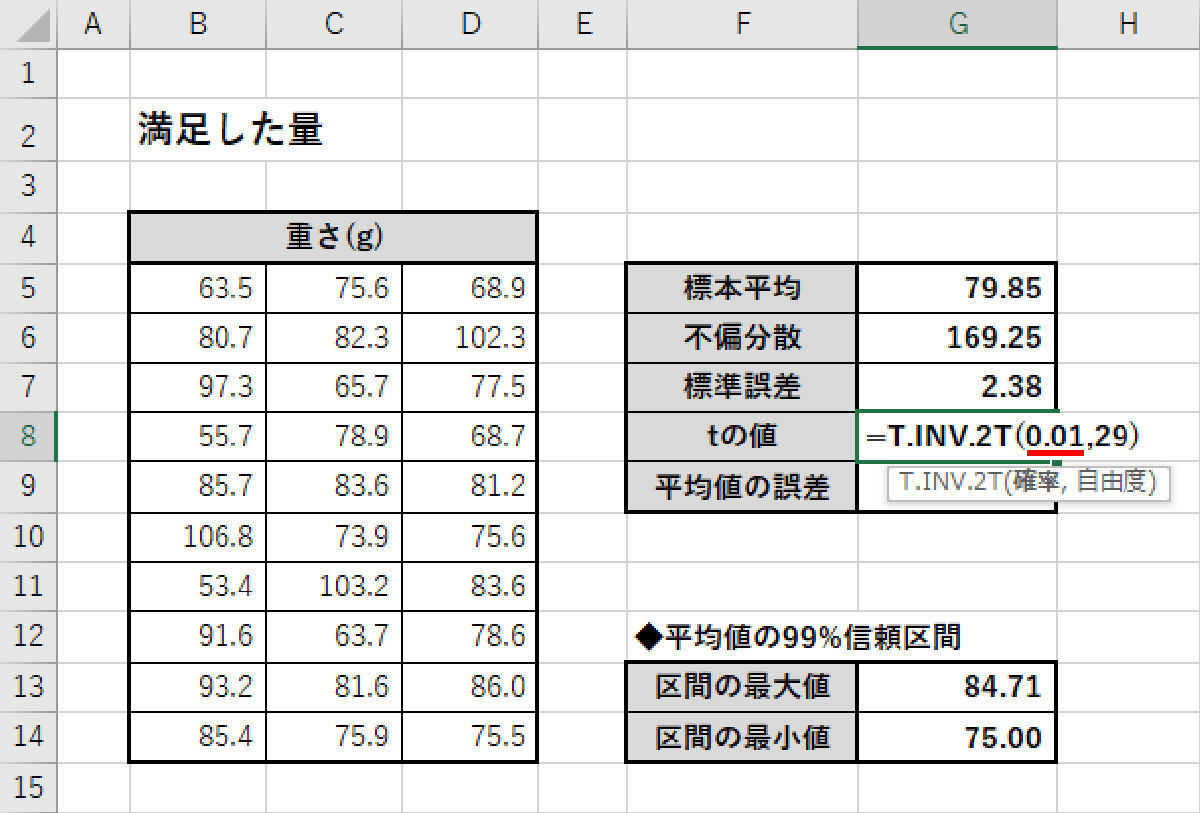
「tの値」の修正

今回の例では「tの値」が2.05から2.76に変化した。それに応じて、各数値も再計算され、以下の図のような結果を得ることができた。
-
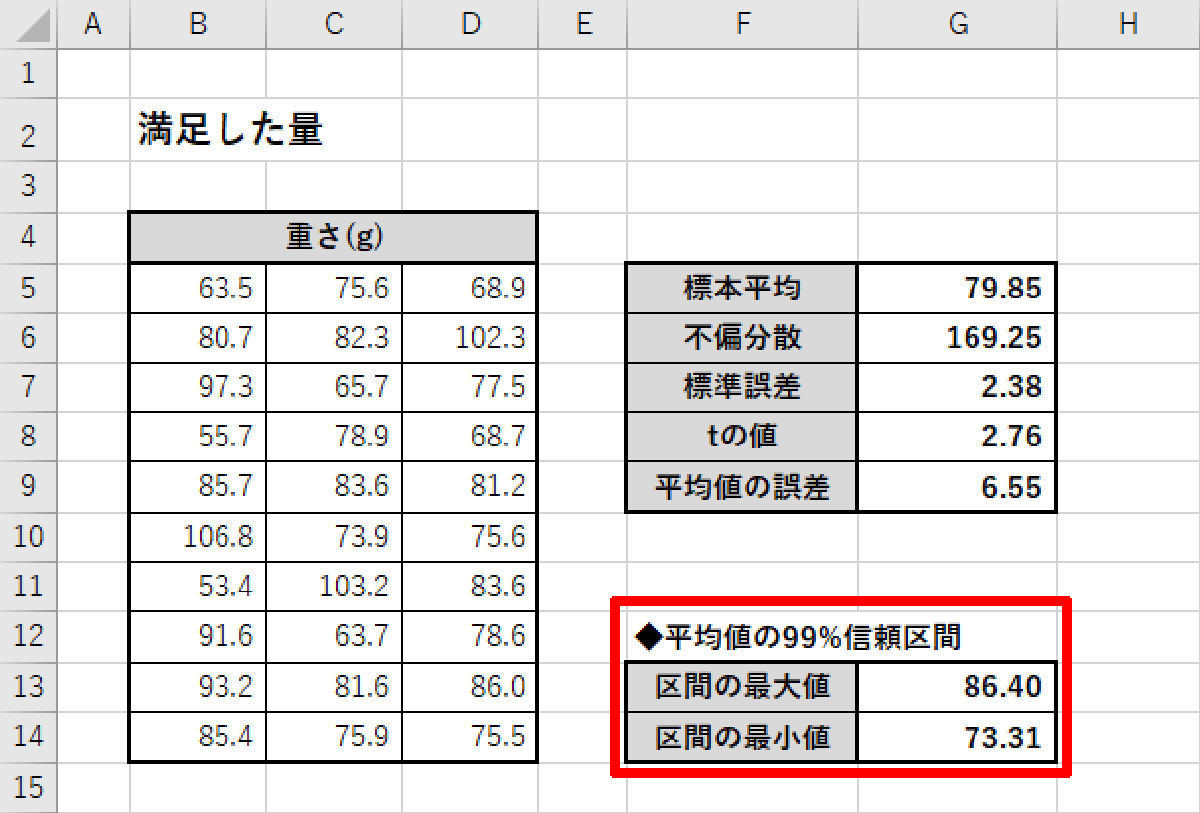
平均値の99%信頼区間

つまり、「平均値の99%信頼区間」は73.31~86.40(g)になる訳だ。前回のサンプル調査とあわせて比較すると、以下のようになる。
前回のサンプル調査(10人分)
【標本平均】81.33g 【95%信頼区間】68.40~94.26g (標本平均±15.9%)
今回のサンプル調査(30人分)
【標本平均】79.85g 【95%信頼区間】75.00~84.71g (標本平均±6.1%) 【99%信頼区間】73.31~86.40g (標本平均±8.2%)
より信頼性の高い「99%信頼区間」で検証しても、前回(10人分)の調査より信頼区間の範囲は狭くなっていることが確認できる。
このように「サンプルデータの個数」は、調査の信頼性に大きな影響を与えるものとなる。「平均値の信頼区間」を求めることで「サンプルの個数は十分か?」を検証できるともいえる。
せっかくExcelというツールを使うだから、単純に「平均値を算出するだけ」ではなく、その信頼性についても検証する習慣をつけておくと、より確度の高い調査結果を得られるだろう。