


人物の姿勢推定(Human pose stimation)は、人の頭部の検出だけでなく、肩、肘、手、腰、膝、足を検出し、人がどのような姿勢を取っているかを推定する技術です。数年前まではDeformable part modelなどの技術が用いられていましたが、近年Deep Learningが用いられるようになり飛躍的に性能が向上しました。最も注目を集めたのが、カーネギーメロン大学のZhe CaoらによってCVPR2017で発表された「Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields」1)が実装されたライブラリであるOpenPoseです。すでにご存知の方も多いと思いますが、知っておくべき技術ですので本連載でも紹介したいと思います。
OpenPoseは、動画像を入力するだけで、画像内の複数人物のポーズをほぼリアルタイムで推定できます(動画)。高い推定精度と高速処理を両立しており、 COCO 2016 keypoints challengeで1位に輝き, MPII Multi-Person benchmarkにおいて効率、精度ともに良い成績を残しています。さらに2017年7月より顔と手の推定が使いされました。これらは、オープンソースで無料公開されています(無料は非商用目的に限る)。
-
Realtime Multi-Person 2D Human Pose Estimation using Part Affinity Fields, CVPR 2017 Oral
OpenPoseでできること
OpenPoseでは、図1に示す通り18個(または15個)もの人の関節位置(画像平面上での2次元座標)を求めることができます。
また前述の通り、顔、手の平の特徴点を求める機能が追加されています。顔については、目、鼻、口、眉毛、輪郭の70個の特徴点を求められます。手の平については、左右それぞれから21個(手首付け根、各指の関節4個)の特徴点が検出可能です。
-
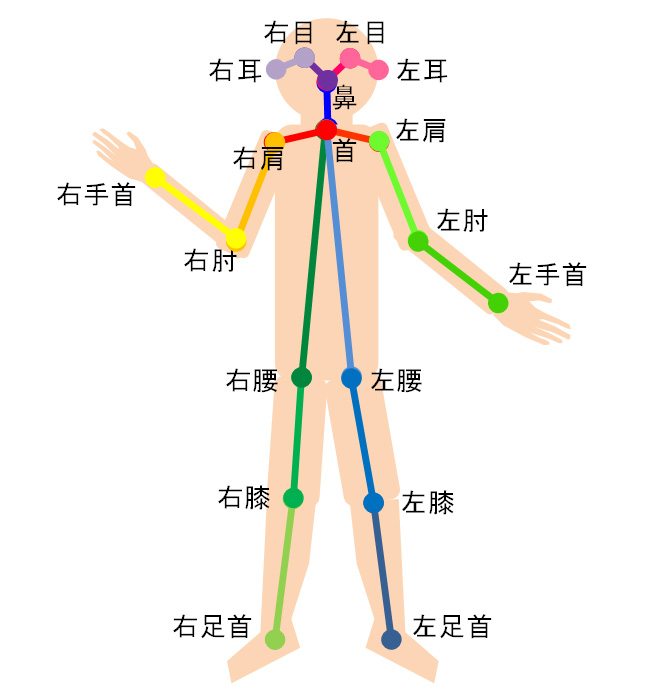
図1 OpenPoseで求めることができる関節位置

アルゴリズムの概要
既存手法では、画像から人が写っている領域のBounding Boxを検出したのちに、Bounding Box内の人のPoseを推定するというアプローチが主流でした。一方OpenPoseは、1枚の画像から複数人のPoseを同時に推定するために、画像からまずは各間接位置をDeep Learningを用いて推定してします(図2b)。各間接毎に1枚のconfidence map、つまり右手首のconfidence mapといった具合に計18個のconfidence mapを求めます。そして、それらの間接を繋ぎ合わせることで人の姿勢情報を得るわけです。このとき、複数の人物が写っている場合、左肩と左ひじのつなぎ方の組み合わせが複数存在することになってしまいます。この組み合わせの中から正しいものを推定するために用いられているのがPAFs (Part Affinity Fields) と呼ばれる手法です(図2c)。これは、関節間が繋がり得る可能性を方向ベクトルマップとして予測するネットワークです。
-
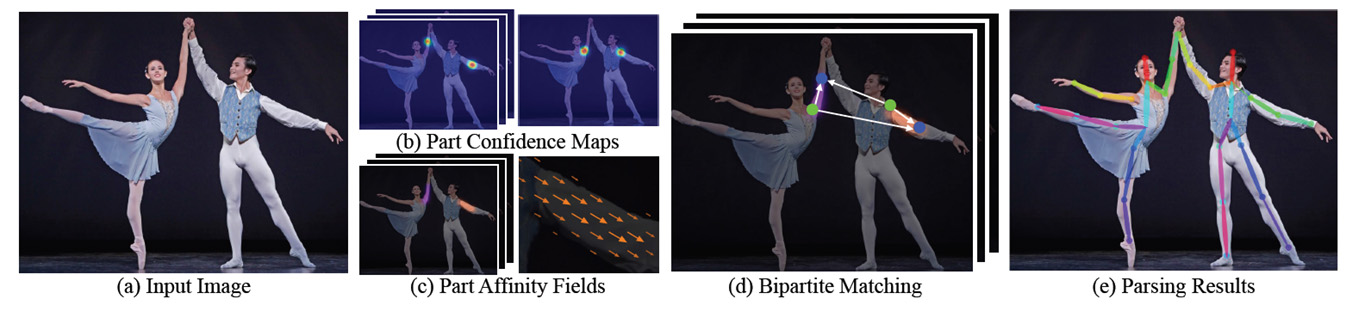
図2 処理の概要
OpenPoseでは、映っている人数に関わらず1回の推論でPose推定が可能なため、リアルタイムに近い処理速度を実現しているというのも大きな特徴です。
コンパイル済みのDemo用プログラムが配布されているので、手軽に試してみることができます。数年前では考えられない精度で検出できるようになっていますので是非実際に動かしてみて下さい!
参考文献
[1] Zhe Cao and Tomas Simon and Shih-En Wei and Yaser Sheikh. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In CVPR, 2017.
著者プロフィール
樋口未来(ひぐち・みらい)
日立製作所 日立研究所に入社後、自動車向けステレオカメラ、監視カメラの研究開発に従事。2011年から1年間、米国カーネギーメロン大学にて客員研究員としてカメラキャリブレーション技術の研究に携わる。
日立製作所を退職後、2016年6月にグローバルウォーカーズ株式会社を設立し、CTOとして画像/映像コンテンツ×テクノロジーをテーマにコンピュータビジョン、機械学習の研究開発に従事している。また、東京大学大学院博士課程に在学し、一人称視点映像(First-person vision, Egocentric vision)の解析に関する研究を行っている。具体的には、頭部に装着したカメラで撮影した一人称視点映像を用いて、人と人のインタラクション時の非言語コミュニケーション(うなずき等)を観測し、機械学習の枠組みでカメラ装着者がどのような人物かを推定する技術の研究に取り組んでいる。
専門:コンピュータビジョン、機械学習









