前回の連載では、関数RANKを使ってランキング(順位)を求める方法を紹介した。このほかにもランキングを求める関数として、RANK.EQやRANK.AVG、PERCENTRANK.INCといった関数が用意されている。状況に応じて使い分けられるように、これらの関数の特徴も覚えておくとよい。そのほか、関数PERCENTILE.INCの使い方も紹介しておこう。
同順位の扱い方、RANK.EQとRANK.AVGの違い
各データのランキング(順位)を求める際に、RANKの代わりに「RANK.EQ」や「RANK.AVG」といった関数を使用することも可能だ。また、順位を0~1(0~100%)の割合で示す「PERCENTRANK.INC」という関数も用意されている。今回は、これらの関数の使い方を紹介していこう。
-

関数RANK.EQ、RANK.AVG、PERCENTRANK.INC、PERCENTILE.INCの使い方

前回の連載で紹介した関数RANKによく似た関数として、RANK.EQやRANK.AVGといった関数も用意されている。引数の指定方法は関数RANKと同じで、第1引数に「順位を調べたい数値」、第2引数に「全データのセル範囲」を指定する。
◆関数RANK.EQの書式
=RANK.EQ(数値, 範囲, [順序])
◆関数RANK.AVGの書式
=RANK.AVG(数値, 範囲, [順序])
いずれも第3引数は省略することが可能だ。省略した場合は、数値の大きい順に並べた順位が返される。数値の小さい順に並べた順位を求めたいときは、第3引数に0(ゼロ)以外の数値を指定すればよい。
前回の連載と同じ「自転車のヘルメット着用率」を例に、各関数の違いを説明していこう。なお、このデータは、警察庁が公表している「令和5年秋の全国交通安全運動の実施について」に基づいたものとなる。
まずは、関数RANKでランキング(順位)を求める。今回の例もD5~D51のセル範囲に「着用率」のデータが入力されている。よって、第1引数に「D5」(順位を調べたい数値)、第2引数に「D5:D51」(データ全体のセル範囲)を指定すればよい。この部分は、オートフィルで関数をコピーしたときにセル範囲が変化しないように絶対参照で指定するのが基本だ。
-

関数RANKの入力

同様の手順で「RANK.EQ」と「RANK.AVG」を入力していくと、以下の図のようになる。
-
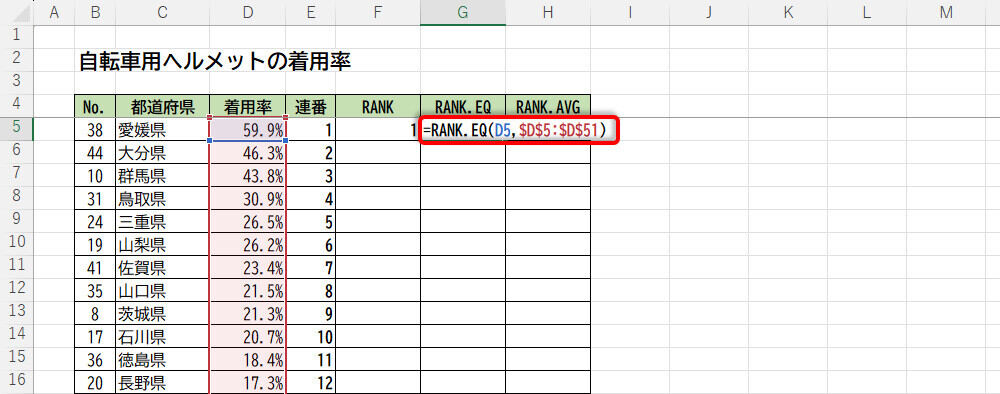
関数RANK.EQの入力

-
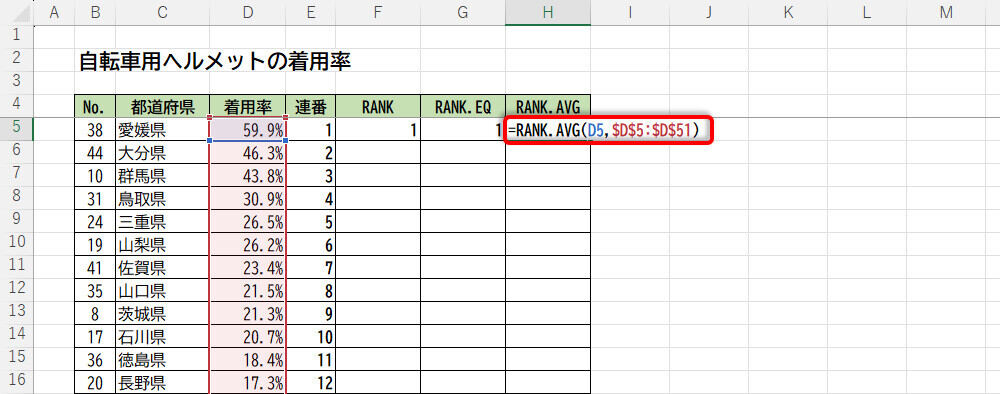
関数RANK.AVGの入力

あとは、これらの関数をオートフィルでコピーするだけ。これで各都道府県のランキング(順位)を求められる。今回の例は「着用率」の大きい順にデータを並べ替えてあるため、いずれの関数も「1、2、3、…」という数値(順位)が並ぶことになる。
-

それぞれの関数をオートフィルでコピーした様子

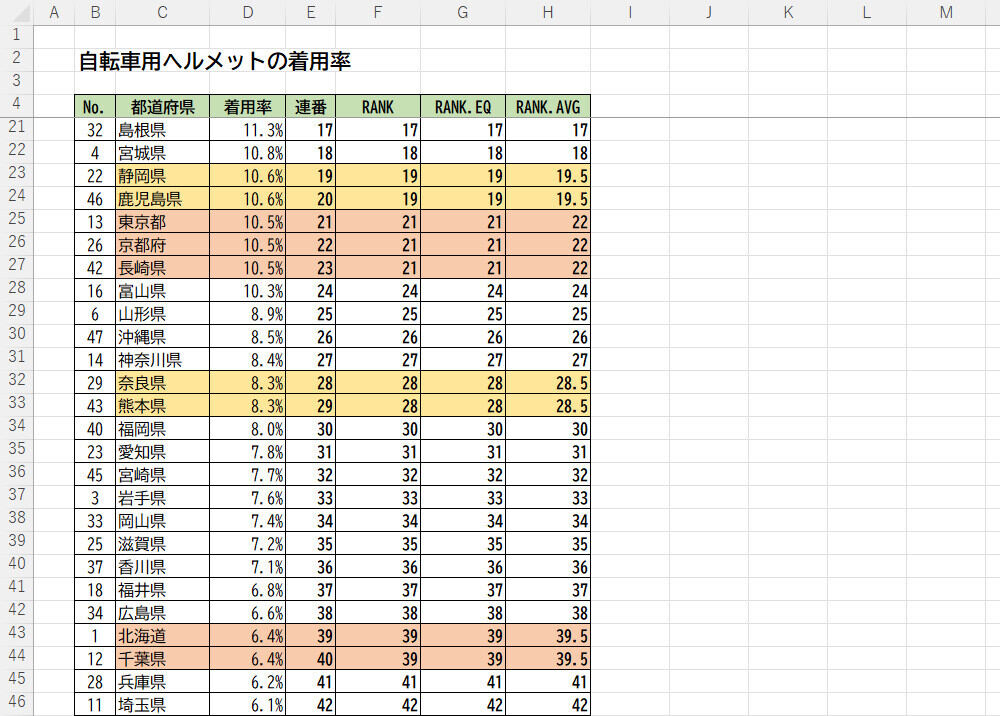
関数によって違いが生じるのは「▲▲位タイ」となる部分だ。たとえば、「着用率」が10.6%の静岡県と鹿児島県は、関数RANK.EQでは19位、関数RANK.AVGでは19.5位という結果になっている。これは「▲▲位タイをどう扱うか?」という問題に起因している。
-
数値が同じデータの順位

静岡県と鹿児島県は「上から数えて19番目に位置しているので19位」と考えるのが関数RANK.EQ。一方、静岡県と鹿児島県は「19~20位に相当するので、その平均をとって19.5位」と考えるのが関数RANK.AVGとなる。
「着用率」が10.5%の東京都、京都府、長崎県も同様の考え方になる。関数RANK.EQの場合は「上から数えて21番目に位置しているので21位」、関数RANK.AVGの場合は「21~23位に相当するので、その平均をとって22位」という結果になる。
ちなみに「RANK」と「RANK.EQ」は、基本的に同じ関数と考えて構わない。同じ関数なのに名前が異なる理由は、関数が実装されるまでの経緯に由来している。
Excel 2007までは、ランキングを求める関数は「RANK」しか用意されていなかった。その後、Excel 2010にバージョンアップした際に「▲▲位タイ」を平均値で求める「RANK.AVG」が新たに導入された。この「RANK.AVG」に合わせて、旧来のRANKも「RANK.EQ」に関数名に変更された。
ただし、関数名を変えてしまうと、それ以前のバージョンと互換性を維持できなくなってしまう。そこで、名前が「RANK」の関数もそのまま残されている、というのが現状だ。つまり、「RANK」と「RANK.EQ」は同じ関数になる。「▲▲位タイ」を平均値で示すケースは少ないので、基本的には「RANK」または「RANK.EQ」の使い方を覚えておけば十分であろう。


順位を百分位で求める
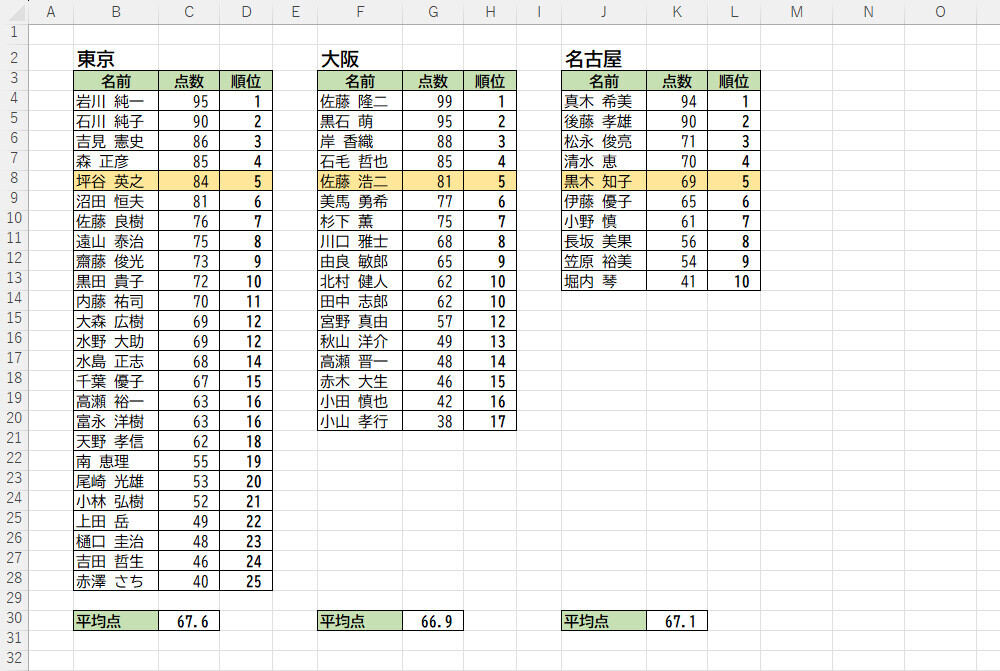
続いては、順位を百分位(0~100%)で示す方法を紹介していこう。以下の図は、ある企業が東京、大阪、名古屋で社員研修を行ったときのテスト結果をまとめたものだ。各地とも平均点は67点前後で、ほぼ同レベルの成績と考えられる。
-
順位が5位の点数を比較した場合

では、平均以外の部分はどうだろうか? 試しに、それぞれのランキング5位の点数を比較してみると、東京が84点、大阪が81点、名古屋が69点という結果になった。この結果を見ると、「名古屋の点数がかなり低い」と感じてしまうかもしれないが、これは仕方のない現象といえる。というのも、テストを受けた人の母数が各地で異なるからだ。
東京は全部で25人がテストを受けているので、第5位は「上位20%」くらいの成績になる。対して、大阪は17人中の第5位で「中の上」くらいの成績、名古屋は10人中の第5位で「ほぼ中間」の成績といえる。つまり、同じ第5位でも、その意味合いは全く異なる訳だ。これでは数値を比較しても意味がない。
このような場合は、全体を0~1(0~100%)と考えて、百分位で順位を求めると、同レベルで比較できるようになる。順位を百分位で求めるときは、PERCENTRANK.INCという関数を使用する。
◆関数PERCENTRANK.INCの書式
=PERCENTRANK.INC(範囲, 数値, [有効桁数])
この関数は、第1引数に「全データのセル範囲」、第2引数に「順位を調べたい数値」を指定する仕様になっている。関数RANKと似ているが、「範囲」と「数値」を記述する順番が逆になっていることに注意しよう。
第3引数には「小数点以下を何桁まで表示するか?」を指定する。このとき、「四捨五入」ではなく、「切り捨て」で表示桁数が調整されことを覚えておく必要がある。小数点以下の表示桁数は「表示形式」でも指定できるので、この引数は省略しても問題ないだろう。
先ほどのテスト結果を使って具体的な例を紹介していこう。東京は、テスト結果の「点数」がC4~C28に入力されているので、第1引数には「C4:C28」を絶対参照で指定する。続いて、第2引数に「百分位を調べたい数値」(C4)を指定すればよい。
-
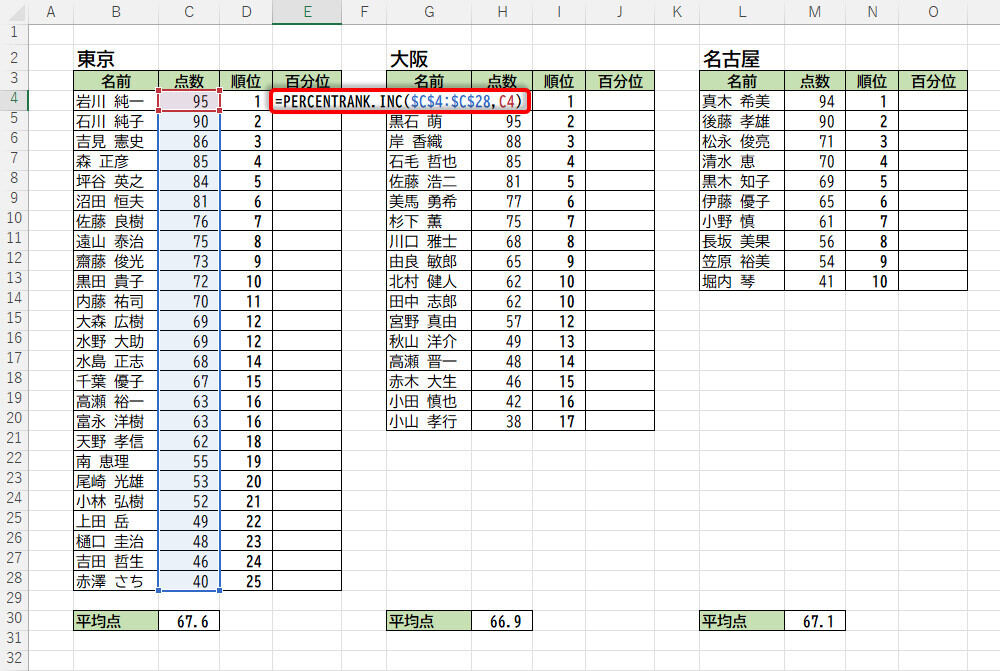
関数PERCENTRANK.INCの入力(東京)

この関数をオートフィルでコピーすると、以下のような結果を得られる。最高点を1(100%)、最低点を0(0%)として、それぞれの順位が0~1の数値で示されているのを確認できるだろう。なお、これらのセルには「数値」の表示形式(小数点以下3桁)を指定してある。
-
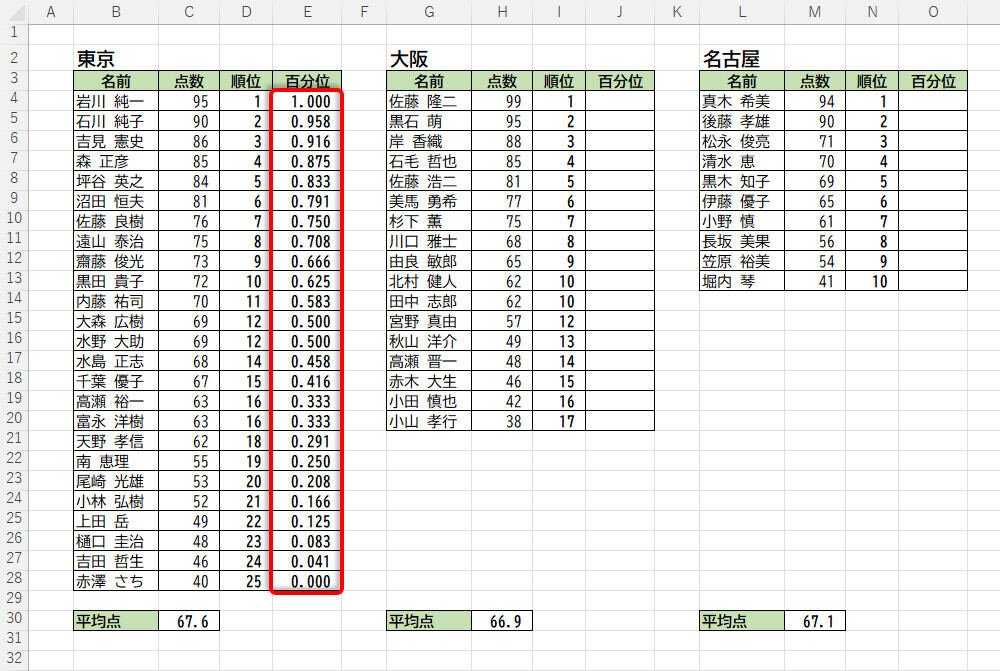
関数PERCENTRANK.INCをオートフィルでコピーした様子

念のため、大阪の百分位を求める関数PERCENTRANK.INCの記述を紹介しておくと、以下の図のようになる。
-
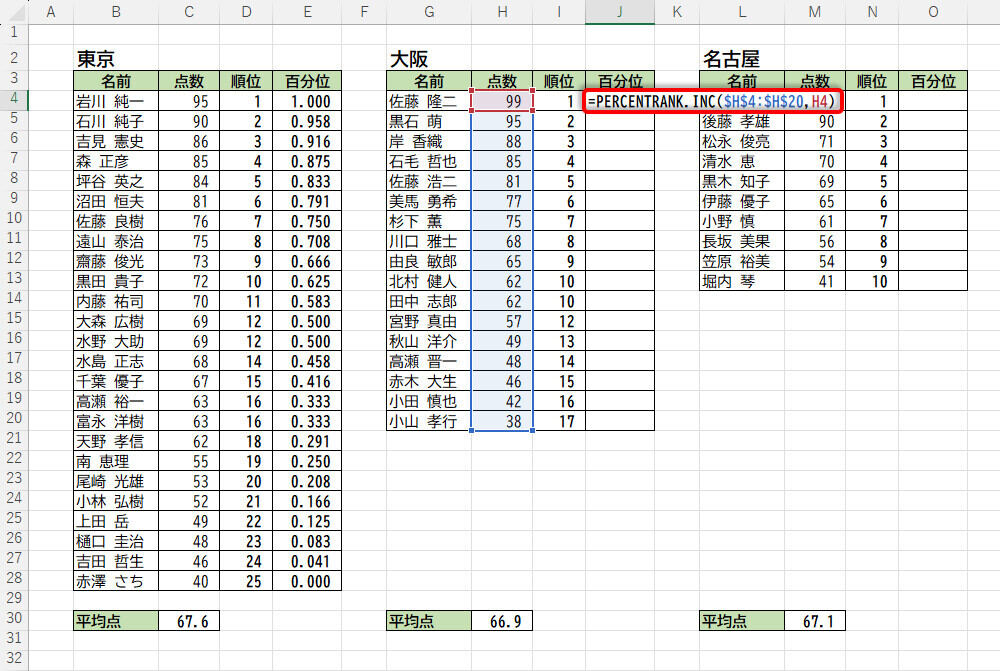
関数PERCENTRANK.INCの入力(大阪)

同様の手順で各データの百分位を求めていくと、以下の図のような結果が得られた。
-
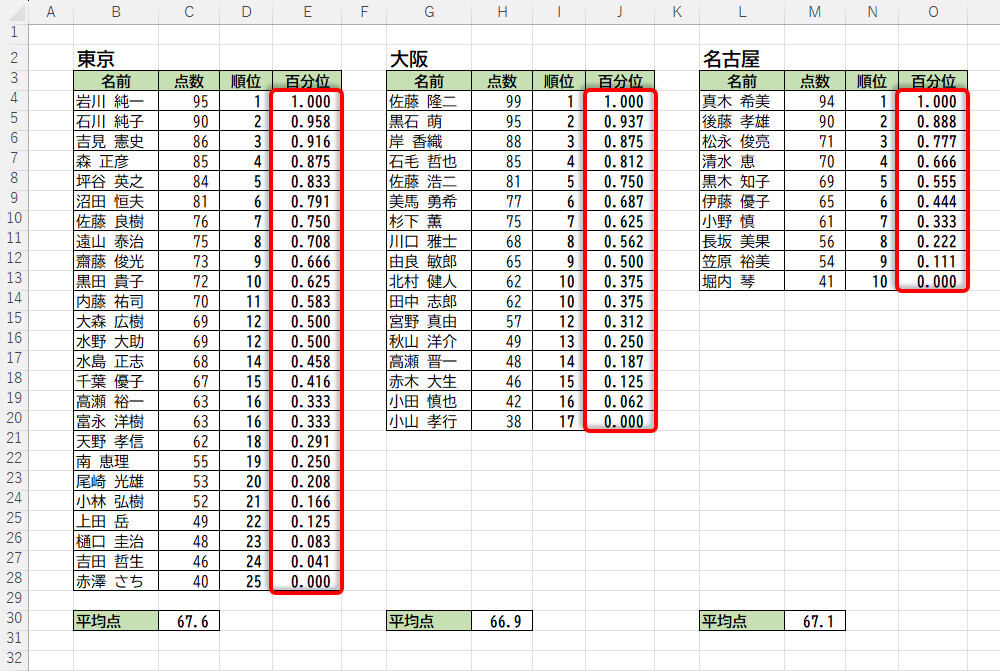
それぞれの百分位を求めた結果

この場合、各地の順位はいずれも0~1になるため、同レベルの順位として比較することが可能だ。試しに、百分位が0.75付近(上位25%付近)の点数を比べてみると、東京は76点、大阪は81点、名古屋は71点という結果になった。
-
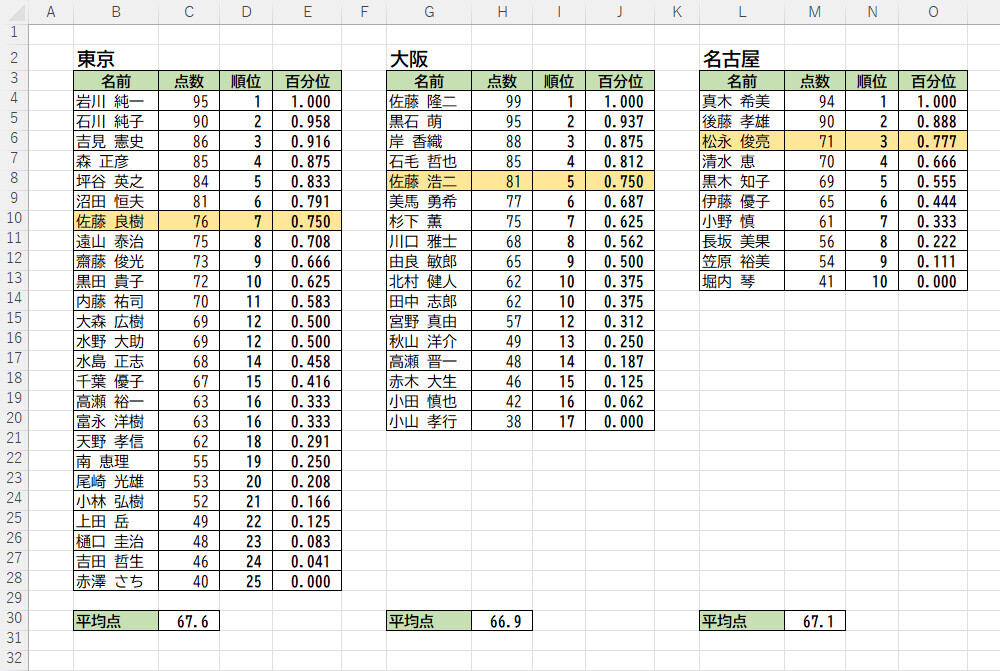
百分位が約0.75の点数を比較

つまり、上位25%付近で比較すると、「大阪 > 東京 > 名古屋」という傾向になっているようである。
このように百分位を使用すると、母数が異なる集団であっても(同じ順位)=(同等のレベル)として扱えるようになる。ひとつの分析手法として覚えておくと役に立つだろう。
百分位に相当する数値を求める
百分位は、小数点以下を含む「0~1の数値」で順位が示されるため、必ずしも「同じ順位」が見つかるとは限らない。先ほどの例の場合、東京と大阪には0.75の百分位が存在しているが、名古屋には0.75の百分位は存在していない。そこで、0.75に最も近い0.77の百分位で点数を比較したが、若干の誤差が生じていることは否めない。
こういった誤差を解消するために、指定した百分位に該当する数値を求める方法もある。この場合は、PERCENTILE.INCという関数を使用する。
◆関数PERCENTILE.INCの書式
=PERCENTILE.INC(範囲, 0~1)
この関数を使用するときは、第1引数に「全データのセル範囲」、第2引数に「百分位」を0~1で指定すればよい。
たとえば、東京で百分位が0.75(75%)になる「点数」を求めたいときは、以下の図のように関数PERCENTILE.INCを記述すればよい。
-
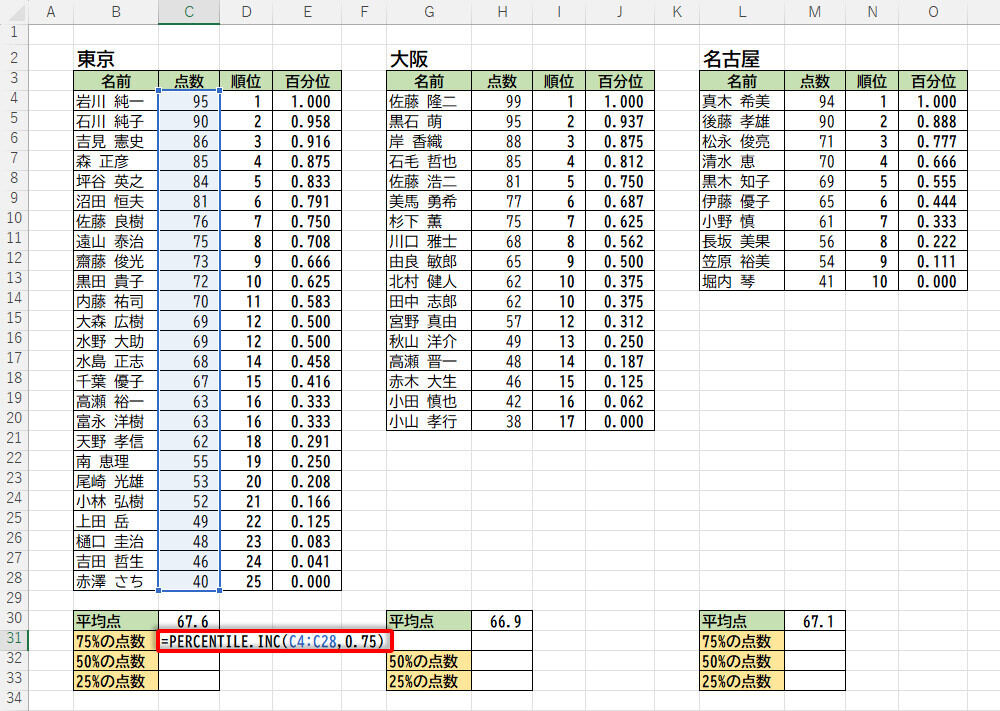
関数PERCENTILE.INCの入力(百分位が0.75の場合)

もちろん、第2引数の値を変更して、百分位が0.5(50%)や0.25(25%)になる「点数」を求めることも可能だ。
-
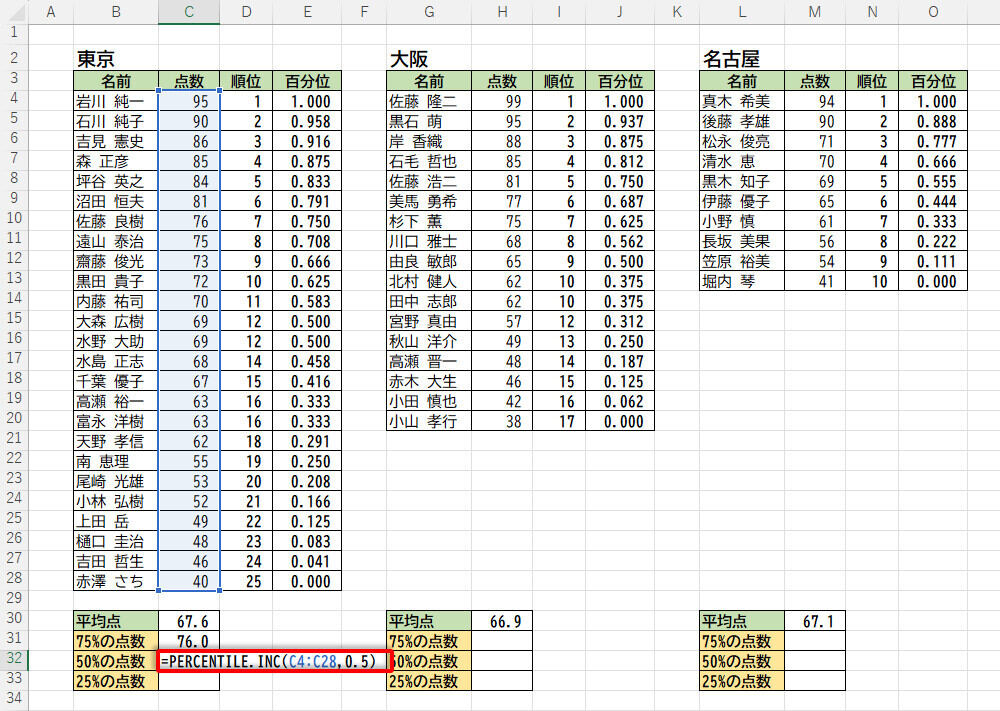
関数PERCENTILE.INCの入力(百分位が0.5の場合)

-
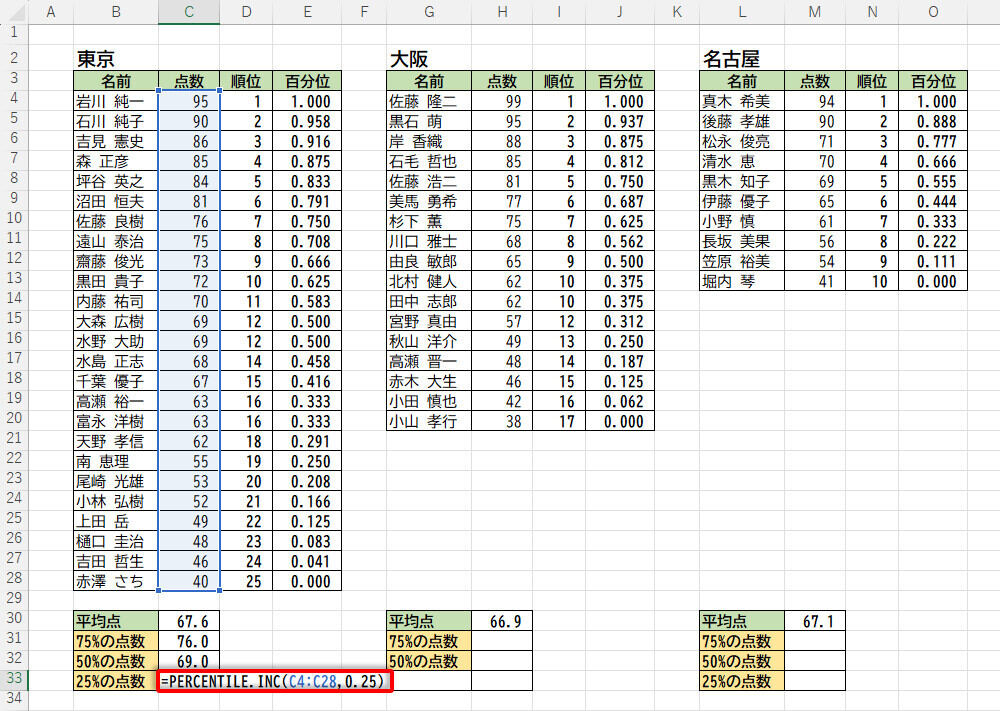
関数PERCENTILE.INCの入力(百分位が0.25の場合)

念のため、大阪で百分位が0.75(75%)になる「点数」を求めるときの記述も紹介しておこう。
-
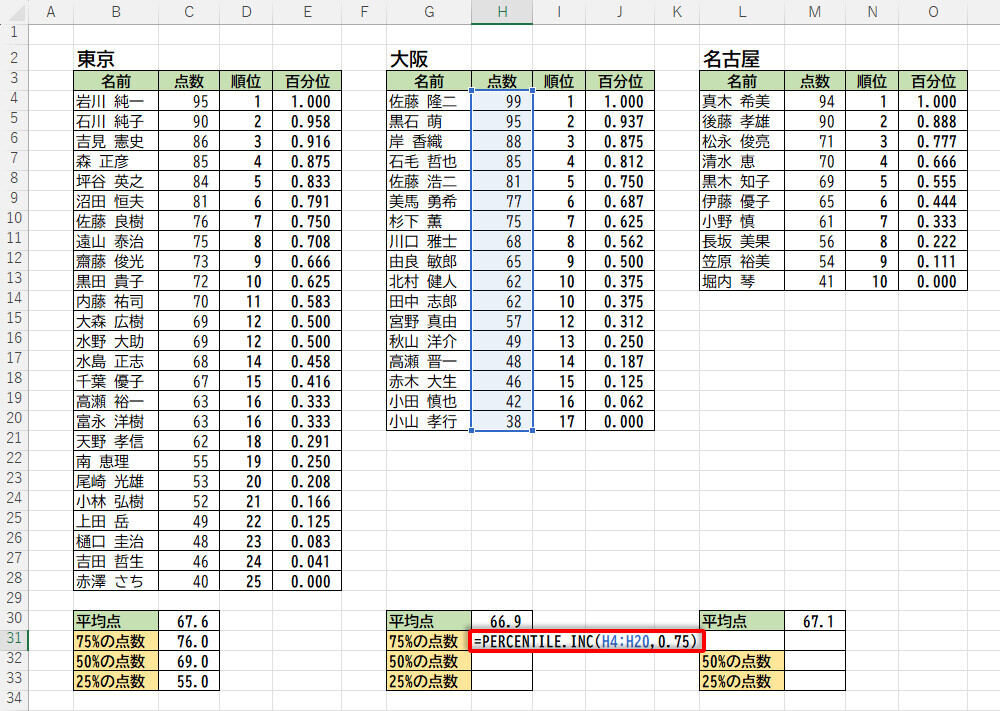
関数PERCENTILE.INCの入力(百分位が0.75の場合)

同様の手順で、百分位が0.75(75%)、0.5(50%)、0.25(25%)になる「点数」を調べていくと、以下の図のような結果が得られる。
-
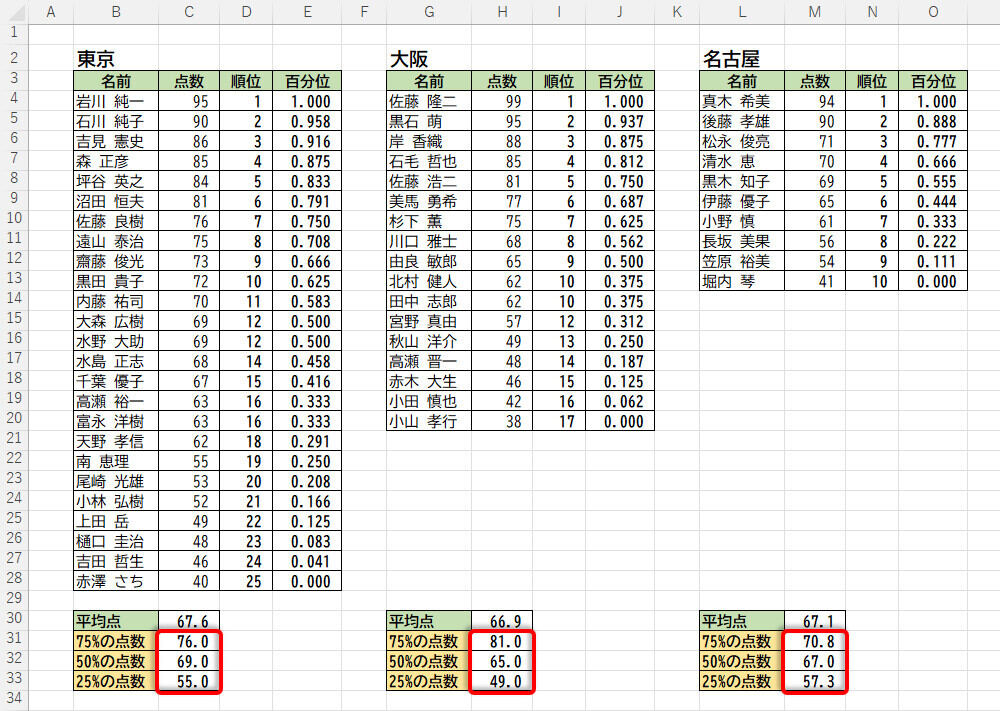
大阪、名古屋についても百分位に相当する数値を求めた例

「東京」を基準にして、それぞれの値を比較すると、
・百分位0.75(75%):「大阪」の点数が高い、「名古屋」の点数が低い
・百分位0.50(50%):「大阪」の点数が少し低め
・百分位0.25(25%):「大阪」の点数が低い
という傾向があるようだ。つまり、各地の平均点は似たような数値であっても、その“ばらつき"には差があると考えられる。特に大阪は、高得点の人が多く、また低得点の人も多い、という傾向があるようだ。
このように百分位を比較することで、各集団の傾向を探ることも可能だ。ただし、今回の例のように数十件程度しかデータがない場合は“誤差の範囲"と捉えるのが適切かもしれない。
もっとデータ数が増えて、数百件、数千件という規模になれば、百分位を“より意味のある指標"として使えるはずだ。百分位はあまり馴染みのない指標であるが、こういう比較方法もあることを覚えておくと、もしかしたら役に立つかもしれない。