GMOインターネットグループのGMOメディアのコエテコAI教育研究所は3月11日、ITパスポート試験とJGLUE(日本語一般言語理解評価)を用いてIT分野における日本語のLLM(大規模言語モデル)の推理能力・問題解決能力を評価するベンチマークを実施し、その評価結果の発表を行った。
JGLUEとITパスポート試験を用いたIT分野でのLLMの能力比較分析
研究は、日本語言語理解ベンチマークJGLUE(Japanese General Language Understanding Evaluation)を活用した一般常識の評価と資格試験「ITパスポート試験」を解答させその正答率でIT分野での日本語LLMの有用性の評価を行うもので、同時にプロンプトでヒントを入力することでLLMの解答を導き出す能力も調査している。
-

「大規模言語モデルの日本語実践的評価:JGLUEとITパスポート試験を用いた比較分析」(公式Webサイト)

研究に活用したLLMはOpenAIの「GPT-3.5(gpt-3.5-turbo-1106)」「GPT-4(gpt-4-11-6-preview)」、Stability AIの「Japanese StableLM Alpha(Japanese Stable LM Instruct Alpha 7B v2)」、東京工業大学情報理工学院・国立研究開発法人産業技術総合研究所の研究チームの「Swallow(Swallow-7B-instruct-hf)」、rinnaの「Nekomata(nekomata-7b-instruction)」、LYZAの「ELYZA-japanese-Llama-2-7b (ELYZA-japanese-Llama-2-7b-instruct)」の6つのLLM。
-
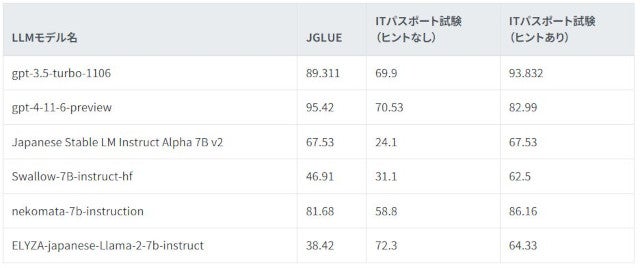
回答率一覧表。それぞれのLLMが獲得した点数割合(%)(同社資料より)

JGLUEのような一般常識問題では38.42%の「ELYZA-japanese-Llama-2-7b-instruct」が、ITパスポート試験(ヒントなし)での研究結果が72.3%。「Japanese Stable LM Instruct Alpha 7B v2」が67.53%(JGLUE)から24.1%(ITパスポート試験/ヒントなし)に見られるように専門的な日本語との比較では差がある。一方、プロンプトでヒント入力を行った結果では「gpt-3.5-turbo-1106」の93.832%、「nekomata-7b-instruction」の86.16%、「gpt-4-11-6-preview」の82.99%と好成績だが他のLLMでも精度向上が大きく見られる。
研究レポートでは、LLMのIT分野での能力については現時点で格差が大きく利用する際には、モデルをよく吟味する必要があると結論付けている。研究論文は一般社団法人人工知能学会主催の「2024年人工知能学会全国大会」へ提出、詳細はコエテコAI教育研究所のページに公開されている。