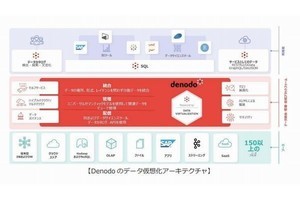
データメッシュの特徴
論理データファブリックがソリューションであるのに対し、データメッシュは組織内のデータ、人、プロセス、活動を体系化するための構造です。論理データファブリックと同様に、データメッシュもデータ統合の論理アプローチで導入することができます。
ThoughtWorks社のZhamak Dehghani氏が2018年に初めてデータメッシュを提言したのは、集中型データインフラストラクチャの課題に対処するためでした。この集中型インフラストラクチャでは、企業データはIT部署によって管理されますが、この部署は組織内の各部署のデータニーズについて限られた知識しか持っていません。
概念上は問題がないとしても、集中型データインフラストラクチャは不満を引き起こしてきました。ビジネス関係者はIT部門に優先的に対応してもらえるよう、たびたび懸命に訴える必要があり、待たなければ要求が満たされず、アクセス権も取得できないことが多いからです。考えてみれば、ほとんどの企業のIT部門は最大数百人で構成されていますが、大規模な組織には数万人以上のユーザーが存在する場合があります。どうすれば、IT部門はこの状態に対処できるのでしょうか?
こうした状況に対し、データメッシュでは、組織内の部署や機能に対応したさまざまな「データドメイン」によってデータが所有され、管理されます。その意味では、分散型構成となります。
データメッシュの原則では、各データドメイン内の関係者が、自分たちのデータを「製品」としてパッケージ化し、組織全体に提供します。各部門が、顧客データ製品、資産データ製品、財務データ製品、そしてもちろん製品データ製品など、独自のデータ製品を作成して管理します。
データメッシュでは、最終的に組織全体での一貫したデータ製品とデータ開発が確実になるように、データプロビジョニングとデータガバナンスの中心的な機能が必要になります。これがデータメッシュの中で唯一、集中的な性質を持つ要素です。
したがって、論理データファブリックと同様に、データメッシュを導入する際は、主要な構成要素としてデータ仮想化を活用することが重要になります。データ仮想化により、データドメインの所有者である各部門は、独自の「ビュー」やデータ製品を作成できます。そして、企業はプロビジョニングとガバナンスの中心となる機能を簡単な方法で設けることができます。
まず、データ仮想化は、各種のデータソースの上で抽象化されたデータアクセスレイヤーとして機能することで、中心となるプロビジョニング機能を提供できます。この仕組みは、論理データファブリックの場合と同様です。データ仮想化では、アクセスメタデータとビジネスメタデータが別のレイヤーに保持されるため、異なるデータドメインにまたがって企業全体のデータガバナンスを進めることも可能です。
さらに、組織でデータソース自体に影響を与えることなく、データソースの上にセマンティックレイヤーを作成できるため、データドメインの作成に不可欠な構成要素を用意できます。
データファブリックかデータメッシュか、あるいは両方か?
簡単に言えば、論理データファブリックはデータを統合するためのインテリジェントで強力な方法であり、データメッシュは企業全体を体系化するための潜在的にインテリジェントで強力な方法です。両者は規模、範囲、目的が大きく異なり、2つの特有の問題に対応しているため、組織によっては両方を選択する場合もあります。実際、企業が設立時からデータメッシュの設計に従った構造になっていた場合や、その設計に準拠するように再編された場合は、論理データファブリックはドメイン全体にわたるデータの整理方法として非常に効果的です。
組織でデータ仮想化を使用すれば、データファブリックとデータメッシュの両方の概念に含まれている論理的なデータ統合方法を活用でき、これらのアプローチのメリットをすぐに得ることができます。さらに、変化するビジネスニーズに対応するように将来にわたって使えるデータフレームワークが用意されているため、必要なものに応じて論理データファブリック、データメッシュ、あるいはその両方に対して備えることができます。
著者プロフィール