データファブリックとデータメッシュは、データとアナリティクスの分野でたびたび取り上げられる2つの概念です。いずれもデータアナリティクスを行う上で、押さえておく必要があります。ただし、どちらも柔軟なデジタルの布地といったイメージが浮かびますが、実際はまったく異なるものです。
そこで本稿では、両者がどのようなものであるか、どのように活用できるかについて説明します。まずは、両者のアプローチが普及してきた背景について見ていきます。
データを1カ所で保管する際の課題を解決
この20年間、データベース、DWH(データウェアハウス)、クラウドデータストア、データレイクなど、データストレージは集中化と分散化のサイクルを繰り返してきました。
現在、企業は形式や用途などに応じて、利用可能なデータをすべて収集するDWHやデータレイクといったモノリシック形態のリポジトリを使用しています。また、AWS(Amazon Web Services)、Microsoft Azure、GCP(Google Cloud Platform)などのクラウドベースのハイパースケーラー、SnowflakeのようなクラウドベースのDWHソリューションも利用できます。
データストレージには利用可能なあらゆるオプションがある一方で、変わらず難しい問題が残っています。企業では、データを見つけやすくするために1カ所に集めたいと考えますが、すべてのデータを単一の保管場所に集めるとなると課題が生じます。
さまざまなサイロから別の中央リポジトリに物理的にデータをコピーするには、時間と労力とコストがかかります。また、あらゆる専門分野にわたる内容のデータを専門家ではない中央のITチームが管理する必要があります。
データファブリックとデータメッシュは、この一元化の課題の解決を目的としていますが、その方法は異なります。
データの一元化の課題を解決する「分散化」
モノリシックなリポジトリにデータを物理的に一元化するには問題があり、それを解決する方法として分散化があります。ただし、データが分散している場合、ビジネスユーザーはどうすれば統合されたデータを入手できるでしょうか。
論理的にデータが統合されていれば、データがどこにあってもそれを活用し、仮想的にデータに接続して、同様に統合された「データビュー」を設けることで分散化に対応できるため、物理データの複製に関する問題が回避されます。論理データの統合アーキテクチャでは、利用者はデータに直接アクセスするのではなく、該当するデータソースの場所や物理スキーマと利用者を分離する、共有セマンティックモデルを通じてアクセスします。
こうしたことを実現するソリューションでは、ソースデータは完全に元の状態のままで、データの仮想ビューが提供されます。データベース、DWH、データレイクなど、さまざまなリポジトリにデータが残るため、分散型のアプローチでありながら、集中型のモノリシックなアプローチのメリットをすべて備えています。
論理データファブリックとデータメッシュは、この新しい論理パラダイムに準拠した技術的進歩を示す2つの例です。どちらも革新的な分散型アプローチで、物理的にデータを1カ所に収集しようとするのではなく、異種のデータソースに論理的に接続します。ただし、その方法はまったく異なります。
論理データファブリックの特徴
データファブリックは、衣服の布地のさまざまな糸のように、異なる場所、形式、種類のデータで構成されます。ただしこの構成でも、データは従来の複製によって物理的に統合されていると考えることができます。
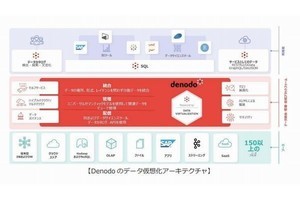
論理データファブリックは、データ仮想化などの論理データ統合の構成要素で、物理的なデータの統合を置き換えたものです。データ仮想化は、データを移動することなく、必要に応じて異種のデータソースをリアルタイムに閲覧できる最新のデータ統合アプローチです。
論理データファブリックは、組織内の各種システム全体からデータをシームレスに統合します。論理データファブリックにソースデータが格納されることは、あるとしてもごく少量ですが、作業のために必要な技術メタデータとビジネスメタデータは保持します。
これらのメタデータは、データがどこに保存されているか、誰がデータにアクセスしているか、関連するすべての共通ビジネス定義などの詳細を示します。情報はカタログ化され、データソースに関する情報を提供するだけでなく、承認済みのユーザーに即時アクセスを許可するリソースとして利用できるようになります。また最新の論理データファブリックでは、機械学習や人工知能を組み込み、重要なプロセスの多くを自動化しています。
組織内のすべてのユーザーが同じ論理データファブリックを通じてデータにアクセスするため、セキュリティとデータガバナンスに固有のサポートが提供されます。アクセスを制御するプロトコルの管理は一度限り行えばよく、論理データファブリックのあらゆる構成要素にわたって効力が及びます。
また、ビジネスユーザーは、論理データファブリックを使用することで実際のデータソースの上のレイヤーにビジネスセマンティクスを追加できます。どのような場合も基盤となるデータソースに影響を与えることはありません。
ビジネスユーザーはこの機能を利用して、特定のニーズに合わせて特注のデータストアを構築でき、この場合も基盤となるデータに影響を与えることはありません。データサイエンティストは各自のツールを使用し、同様の信頼できるデータに基づき独自のモデルを繰り返して開発することができます。結果として、論理データファブリックでは利用可能なデータがすぐに活用できるので、データサイエンティストはデータの収集と準備に多大な時間を費やす必要がなくなります。
論理データファブリックでは、データ利用者がデータの保存場所に関係なくデータにアクセスできるため、大規模な最新化プロジェクトや移行プロジェクトのようにデータを移行する過程でも、ビジネスユーザーはデータを引き続き使用できます。また、論理データファブリックにより、データ利用者がデータにアクセスする際の複雑性がかなり緩和され、ビジネスユーザーは余裕を持って迅速に適切な意思決定を行うことができ、開発サイクルが短縮されます。