創業50年のスポーツ用品チェーンのアルペンが、オラクルの自律型クラウドデータベース「Oracle Autonomous Data Warehouse」を導入し、マルチクラウド環境上のさまざまなデータを集約する基盤を構築している。あわせて、同社は内製化を進めることで事業側の変革を後方支援する体制を整えている。このプロジェクトを進めているのは、長年経験を積んだ情報システムのプロではなく、店舗出身者が大部分を占めるスタッフだ。
今回、執行役員 デジタル本部長 兼 情報システム部長を務める蒲山雅文氏に、アルペンが考えるDXとその進め方について話を聞いた。
-

アルペン 執行役員 デジタル本部長 兼 情報システム部長 蒲山雅文氏



HOWに重きを置いているアルペンの脱レガシー戦略
アルペンが約900万人の会員データ、約400店舗とECサイトの販売データを高速に処理するため、Autonomous Data Warehouseを導入することを決定したのは2019年後半のことだ。
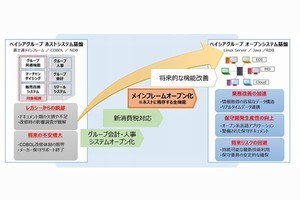
その背景にはDXよりも、「レガシーのホストシステムを撤廃すること」があったと蒲山氏は明かす。蒲山氏は中期IT計画を立てるにあたって、HOW(=脱レガシーのアプローチ)を中心に据えた。WHAT(=レガシーに代わってどんなシステムを構築するか)を具体的にすると、計画が完了する数年後に、完成したシステムとその時点のビジネス環境に不整合が起きかねないからだ。
「この先、世の中がデータドリブンになっていくことは間違いありません。そこで、ホストシステムが担っていた大量のデータ処理に変わる高速演算機能と、データ分析を加速させるために社内に分散しているデータを統合するデータウェアハウスが必要であること、この2つだけを2019年の時点で明確にしていました」と、蒲山氏は話す。
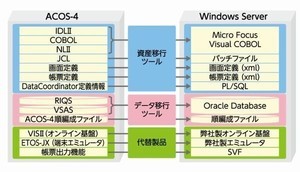
ホストシステムからどのように脱却するか。アルペンが取った策は、パーツに分解するというやり方だ。具体的には、ホストでの運用を継続したまま発注、物流などと領域ごとに切り出して独立した業務アプリケーションとして構築し、切り出した業務アプリケーションの安定稼働を見届けたら、その領域を担うホストの機能を閉じるという形で進めていった。
こうして進めた結果、最後に残ったのが、大量のデータ演算だった。この移行先として、Autonomous Data Warehouseが選ばれた。
メンテナンスフリーだからミドルウェアの知識がなくても運用可能
Autonomous Data Warehouseを選定した理由について、蒲山氏は「Exadataレベルの処理性能がクラウドでも提供されるようになったうえ、Autonomous Data Warehouseは自律型なのでほぼメンテナンスフリーで使えます。これならいけるかもと思いました」と説明する。
アルペンの情報システム部のメンバーは約20人。そのうち15人がITを担当するが、ITの経験が浅い店舗出身者がほとんどだ。つまり、彼らは現場の実務ややビジネスは熟知しているが、情報システムに関する知識は少ない。そこで、蒲山氏はミドルウェアの知識がなくても使えるAutonomous Data Warehouseがぴったりと感じたわけだ。
競合製品と比較して、演算処理(集計や更新)と分析(検索や抽出)の両方において高速であること、CPUとメモリを分けてスケールアップでき、コストと性能のコントロールがしやすいことなどが魅力だったとも、蒲山氏は振り返る。
一方で、「安くはない」というコストについては、Google BigQueryの併用により抑えることができたという。BigQueryは発行したクエリに対して課金されるのに対し、Autonomous Data Warehouseの課金単位は稼働時間だ。
日中の業務ではBigQueryを動かし、夜間はAutonomous Data Warehouseでビッグデータを高速処理、その結果をBigQueryに蓄積していくという合わせ技により、「コストはかなり抑えられている」と蒲山氏。
ここで生きているのが、中期IT計画でWHATをガチガチに固めなかったことだ。「構想段階から巨大なデータウェアハウスを構えることを既定路線としてしまうと、最初に選択したOracleありきになってしまいます。当社は、ちょっとずつ付け足していくアプローチだったため、BigQueryとの併用という発想が生まれました」と、蒲山氏は分析する。