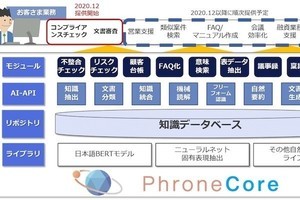
NTTデータは3月16日、汎用言語モデルBERTを特定の業務領域(ドメイン)に応じて最適化し、顧客の扱う業務文書に適した言語モデルを自動構築するドメイン特化BERT構築フレームワーク(以下ドメイン特化BERT-FW)を開発したことを発表した。
-
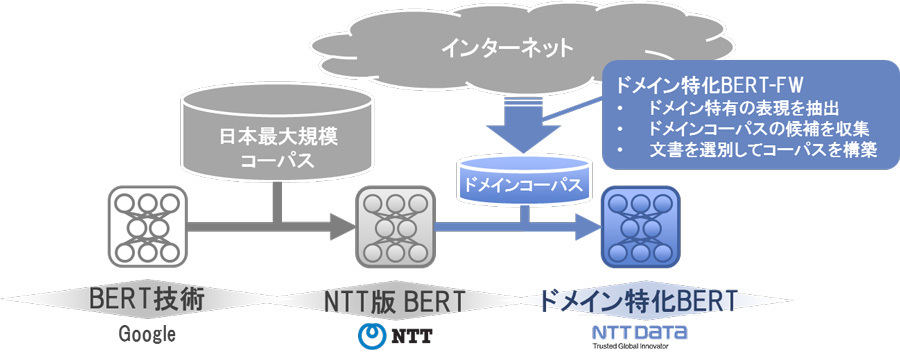
ドメイン特化BERT-FWの仕組み

ドメイン特化BERT-FWは、汎用言語モデルであるBERTに追加学習を行い、お客さまの業務文書に合わせて最適な言語モデルを構築する仕組みだ。
一般的なBERTでは、自然言語処理を適用する業務によっては事前に「業界」の範囲を適切に定義することが難しいことが課題となっていたが、本FWでは、対象とする業務文書ごとに最適なデータを収集して追加学習を行うことにより解決を図っているという。
処理対象の業務文書から学習前の一般的なBERTモデルによる扱いが難しい文章を効率的に選別する。主に専門用語を含む文を対象に類似した文章をインターネットから収集し、追加学習することで特定ドメインに特化した言語モデルを構築するという。これにより、顧客の業務ごとに最適化された言語モデルを提供可能になるということだ。この一連の流れを自動化することで、迅速に言語モデルを構築し、一般的なBERTモデルを上回る精度を実現するという。
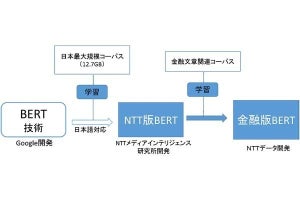
ドメイン特化BERTモデルの性能を評価するため、金融系資格試験に解答するタスクで検証を行った結果、汎用モデルであるNTT版BERTおよびNTTデータが2020年7月に構築した金融版BERTモデルと比べて、ドメイン特化BERT-FWで構築したモデルは高精度であることが確認できたということだ。
このFWの適用により、専門用語や特有の文脈への対応が必要だった分野での自然言語処理技術活用の幅が大きく広がることを見込んでいるという。
2021年4月以降順次、文書を扱う業務の効率化やサービスの高度化を検討している企業を募り、2021年度中に顧客との共同検証を5件実施する予定だという。また、2021年7月末まで企業・公共団体等の申込みを受け付けるということだ。