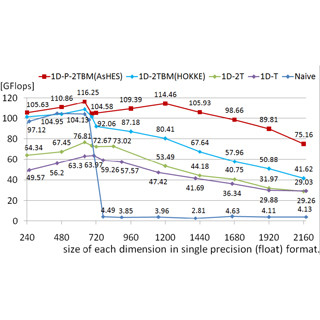
TSUBAME3.0の諸元をまとめたのが次の表である。CPUは、Xeon E5-2680(14コア、2.4GHzクロック)を2個、GPUはNVIDIAのSXM2 P100 GPUを4個使っている。メモリはDDR4-2400で256GBの容量となっている。
システム全体の倍精度浮動小数点演算性能は12.15PFlopsで、メモリバンド幅は1.66PB/sとなっている。B/F比は0.137B/Flopsで、約0.5B/Flopsの京コンピュータと比較すると演算に比べてメモリバンド幅が小さい設計になっている。
右側の棒グラフは、Oakforest-PACSと京コンピュータとの倍精度浮動小数点演算の理論ピーク性能の比較である。Oakforest-PACSと比較すると半分程度の性能であるが京コンピュータと比較すると若干上回っている。
ただし、Top500のランキングに使われるLINPACK性能は、Oakforest-PACSはピーク性能の54.4%、京コンピュータは93.2%である。TSUBAME3.0 と構成の似ているNVIDIAのSaturn Vは67.5%であるので、これから類推すると、Top500での順位はOakforest-PACS、京コンピュータ、TSUBAME3.0という順になると予想される。

|
|
TSUBAME3.0 の諸元のまとめ。CPUはXeon E5-2680 V4、GPUはNVIDIAのTesla P100 SXM2を使用している。計算ノードのメモリはDDR4-2400で256GB。ローカルのストレージとして2TBのSSDを搭載している |
これまでのTSUBAMEシステムは、古いシステムを撤去して、同じ場所に新しいシステムを入れていたが、今回は、TSUBAME2.5の運用を継続して、新しいコンピュータルームにTSUBAME3.0 を入れる。
これは、TSUBAME3.0 の重量が重く、TSUBAME2.5を入れている2階に置けないという事情もある。そのため、現在1階にあるTSUBAME2のストレージを移動するなどしてスペースを作り、平米当たり1トンの荷重に耐えられる床を作る。コンピュータルームでは床を持ち上げ、その下にケーブルを通す構造が一般的であるが、TSUBAME3.0では、床はコンクリートで、ケーブルや冷却水などはラックの上を通すことになる。

|
|
TSUBAME3.0用には、1階を片付けて、新たに130m2のコンピュータルームを作り、TSUBAME2.5と同時運用する |
次の図は各種の用途で必要とされる演算精度を表したものである。数値解析では64ビットの倍精度が要求されることが多いが、コンピュータグラフィックス、ビッグデータ、機械学習などでは32ビットの単精度、あるいは16ビットの半精度でよいという場合も多い。
右側の棒グラフは、東工大のセンターと東大のセンター、京コンピュータの半精度演算性能を示したもので、TSUBAME3.0とTSUBAME2.5、さらにTSUBAME-KFCを合わせた性能は65.8PFlopsとなり、多少苦しい説明であるが、日本で最大性能ということになる。
なお、京コンピュータはビッグデータや機械学習が盛んになる以前の設計であり、精度を下げた演算でも性能は向上しない。

|
|
ビッグデータや機械学習などでは単精度や半精度の計算が多い。半精度の総計算能力では、東工大センターは東大の柏センターを上回る |
次の表は、TSUBAME2.5 とTSUBAME3.0の1ノードの諸元の比較である。

|
|
計算ノードあたりのTSUBAME2.5とTSUBAME3.0の性能比較 |
そして、こちらは1ノードのベンチマーク性能の比較である。SPECintやSPECfpと言ったカバー範囲の広いベンチマークでは4倍弱、演算比率の高いHPLやHPCGでは5.55倍から7.42倍とTSUBAME3.0 での性能向上度が大きくなっている。

|
|
計算ノードあたりのベンチマークプログラムでの性能比較。汎用のSPECベンチマークでは4倍弱。HPLでは7.42倍,HPCGでは5.55倍 |
TSUBAME2.5ではノードを4コア+3GPUか8コアという構成に固定的に分割して、実行するジョブに割り当てていたが、TSUBAME3.0では、Dockerを使用して、計算ノードのリソースをCPUコア、GPU、NIC、メモリの単位という細粒度で割り当てられるようになる。

|
|
TSUBAME3.0ではDockerを使い細粒度でのリソース割り当てができるようになる |
この結果、次の図のように各ジョブが必要なリソースをきめ細かく割り当て、利用効率を上げることができる。

|
|
Dockerによる細粒度リソース割り当ての例 |
次の図はTSUBAME3.0の冷却システムを示す図である。TSUBAME2では10℃程度の冷水での冷却を行っていたが、TSUBAME3.0では32℃の温水を用いる方式に変更された。32℃の温水でCPUとGPUは直接水冷している。そして、40℃程度に温まった水を屋外に設置したクーリングタワーで自然大気で冷却している。クーリングタワーは水を循環させる小さなポンプとファンだけで蒸発冷却をおこなうことができ、冷水を作るコンプレッサと比べると大幅に少ない電力で冷却が行える。
HPEのGoh氏は、32℃より高い温度にすれば冷却効率は良くなるが、半導体の動作温度が高まり信頼度にも影響するので、両者のバランスで32℃に決めたという。
一方、ファイルシステムやI/Oには14℃の冷水やエアコンで冷却を行っている。

|
|
TSUBAME3.0の冷却システム系統図。32℃の温水でCPU、GPUを冷やす。40℃に温まった水はクーリングタワーで自然大気冷却する |
ブレードの写真を次の図に示す。右奥に突き出しているのが冷却水のコネクタで、金属パイプが手前の4個のGPUのコールドヘッドに繋がっているのが見える。他の部品に隠れて見えないが、2個のCPUにも水冷のコールドヘッドが付けられている。

|
|
TSUBAME3.0の計算ノードブレード。右奥に突き出しているのが水冷のコネクタ。手前の4個がP100 GPU (写真提供:日本SGI) |
次の図は、ICE XAラックの観音開きのドアを開けた写真で、9枚×4段のブレードが見える。そして、冷却水を供給、排出する部分がラックの上に載っている。

|
|
ICE XAラックの前面扉を開けたところ。9枚×4段のブレードが見える (写真提供:日本SGI) |
CPUとGPUは直接、冷却水で冷却されるが、DIMMやSSDなどは空気で熱を運ぶ必要がある。次の図はラックを上から見た図で、ブレードを通り抜けてDIMMなどを冷却して温まった空気は、中央のICE XAと書かれたクーリングラックに戻り、この図では逆V字型に配置された水冷のコイルで冷却されて循環する。
なお、CMCはシャーシマネジメントコントローラの略であり、各ブレードの電源制御やラックの電源や温度の監視を行っている。

|
|
ICE XAのラックを上から見た冷却風の流れ。中央のクーリングラックの中に逆V字型の水冷コイルがあり、温まった空気を冷却する (図提供:日本SGI) |
このような冷却を行うことによりPUE(Power Usage Effectiveness、1年間の(機器電力+冷却電力)/機器電力)は1.033になると予想している。これは初代のTSUBAME1が1.4~1.6、TSUBAME2が1.28であったのと比べると大きな改善である。また、オイル液浸でクーリングタワーを使ったTSUBAME-KFCの1.09をも下回っている。
寒冷地は別として、東京に設置されるデータセンターとしては破格に低いPUEとなっている。

|
|
下の表は、各月の冷却電力とPUEを示している。8月でもPUEは1.036と僅かな上昇で留まっている |
TSUBAME3.0は、現在、コンピュータルームの工事中で、これが3月末に完了し、そこから機器の納入が始まる。契約上の納期は7月末で、8月から運用開始と言う発表である。
次回のTop500、Green500の実測結果の提出の締め切りは5月29日であり、この時期までに実測ができるかどうかは微妙なところである。
松岡先生によると、SGIのブレードは、CPU部とGPU部は分離されており、個別にアップグレードができるようになっているという。この機能を利用して、まず、CPU部をSkylakeにアップグレードし、その後、GPUをVoltaにアップグレードする計画であるという。Volta GPUの性能は、まだ、公表されていないが、性能が倍増すると、Oakforest-PACSに並ぶ性能に引き上げられることが考えられる。