Hot Chips 28におけるメニーコアのセッションでは、プリンストン大学の「Piton」と呼ぶ25コアのプロセサと、カリフォルニア州立大学デービス校(U.C.Davis)の1000コアの「KiloCore」の発表が行われた。
大学の研究用のプロセサであるから、メーカーが作るような規模や完成度はないが、そこに盛り込まれた新しいアイデアが見どころである。
32nm SOIプロセスを用いた25コアのPiton
PitonはIBMの32nm SOIプロセスを使い、チップサイズは6mm×6mm。460Mトランジスタを集積する。電源電圧0.9Vで、1GHzクロックで動作する。25コアであるが、18mm×18mmのチップを16nmプロセスで作れば、36倍の900コアを集積できる密度である。これなら、メニーコアと呼んでおかしくない。

|
|
Pitonプロセサを発表するプリンストン大のMichael McKeown氏 |
Pitonはデータセンタレベルまでスケールすることを目的とし、チップやボード、ラックといった物理的な分割を超えてスケールできるアーキテクチャを目指している。
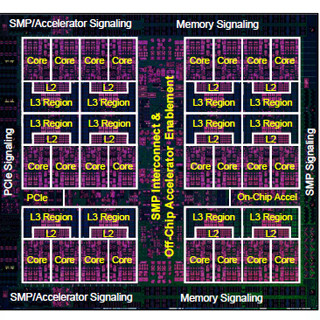
そのため、チップ内の25コアは5×5のメッシュ接続であるが、上辺のチップブリッジを通して、チップ間を接続する上位のメッシュに接続するというアーキテクチャになっている。チップはワイヤボンドで接続されている。

|
|
チップ内の25コアは5×5のメッシュ接続で、チップは上位のメッシュに接続されるというアーキテクチャになっている (このレポートの前半のすべての図は、Hot Chips 28でのプリンストン大のMcKeown氏の発表スライドのコピーである) |
PitonコアはOpenSPARC T1をベースにした設計で、25コアをオンチップのメッシュネットワークで接続している。そして、チップにネットワークインタフェースを付けて、最大64Kチップをメッシュ接続できるようにしている。
メッシュを経由してチップ間でのキャッシュコヒーレンシをサポートする。しかし、多数のチップでコヒーレンシを維持しようとするとそのためのプロトコルの通信が多くなり、身動きが取れなくなってしまう。このため、ドメインを定義して、ドメイン内のチップだけコヒーレンシを維持するという新しい考え方を採用している。

|

|
|
コアはSPARC V9アーキテクチャで、チップ間のメッシュ接続機能を持つNoCとなっている。最大64Kチップまで接続できる仕様となっている |
Pitonチップは5×5にタイルが並び、上辺にチップブリッジが配置されている。チップはワイヤボンドで接続されている |
各コアごとに2スレッドをサポートし、L1.5という8KBのプライベートキャッシュを持つ。L2キャッシュは、各コアが64KBのスライスを持ち、チップ全体で1.6MBのキャッシュとして動作する。

|

|
|
Pitonチップのダイ写真とワイヤボンドの接続 |
OpenSPARC T1をベースにしたコアを使い、メモリトラフィックシェーパという機能を付け加えている |
プリンストン大の第1の工夫は、各コアやアプリ単位に公平にメモリが使用されるようにする「Memory Traffic Shaper」という機能を取り入れたことである。これもPitonで実装された新しいアイデアである。25コアが1つのメモリをシェアして使うので、メモリバンド幅を各コアに公平に分配することが重要になる。各コアのメモリアクセス間隔をモニタし、短い間隔でL2キャッシュをミスするアクセスが起こるコアのアクセス要求を待たせることによって、メモリバンド幅の使用の公平化を図る。

|
|
Memory Inter-arrival Time Traffic Shaperは、各コアのメモリアクセス間隔をモニタし、短い間隔でDRAMアクセスを行うコアのアクセス要求を待たせる |
次の図は8プログラムを実行した時、プログラムの実行速度がどれだけ遅くなるかを測定した結果である。左端のグラフは何もしない場合で、メモリアクセスが競合して、最大5.33%、平均2.92%スローダウンしている。これに対して、Memory Traffic Shaperを使用した右端のグラフでは、最大3.52%、平均2.31%のスローダウンと平均では0.61%程度スローダウンが減少(=性能向上)している。
もっと、メモリが混み合っている状況では、もっと大きな違いがでるのではないかと思われるが、新たな機構を導入して0.61%の性能改善では物足りない。

|
|
左端のNoQoSは何もしないで自由にアクセスさせた場合で、8プログラムを実行させると平均2.92%のスローダウン。メモリトラフィックのシェーパを使うと右端のグラフでは、平均2.31%のスローダウンに改善している |