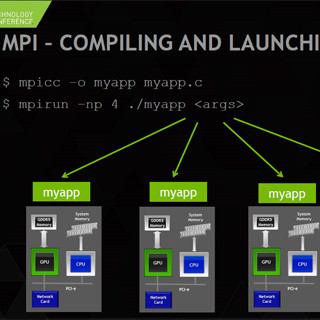
GTC 2015 - MPIを使ったマルチGPUのプログラミング「高性能化編」の関連記事 |
|---|
|
・【【レポート】GTC 2015 - MPIを使ったマルチGPUのプログラミング「基礎編」 ・→ そのほかのGTC 2015の記事はコチラ |
NVIDIAは、CUDA4以降、UVA(Unified Virtual Addressing)という機能をサポートしている。CPUとGPUを単純にPCIeで繋いだ場合は、両者のメモリは独立で、CPUメモリの0番地とGPUメモリの0番地の両方が存在することになる。
一方、UVAでは次の図の右側の絵のようにCPUメモリの後にGPUメモリが置かれることになり、0番地はCPUメモリにしか存在しない。しかし、CPUはCPUメモリにしかアクセスできないし、GPUはGPUメモリにしかアクセスできないという状況は変わらない。
これで何が良いかというと、番地を見ると、それがCPU側のメモリであるか、GPU側のメモリであるかが分かり、それに応じた処理ができるという点である。

|
|
UVAではCPUとGPUのメモリに連続の番地が振られており、番地を見ると、どちらのメモリであるかが分かるようになった |
つまり、CUDA対応のMPIは、送受信のデータのアドレスを見て、それがGPUメモリにある場合は、GPUメモリからCPUメモリ、あるいはその逆方向のコピーを自動的に行ってくれる。従って、プログラマはcudaMemcpyを明示的に書く必要がない。

|
|
CUDA対応のMPIはバッファがGPUメモリにあることが分かると、GPUとCPUメモリのコピーを自動的に行ってくれる。通常のMPIでは、この場合は明示的にcudaMemcpyをプログラムに必要がある |
また、MPIの性能を改善するため、NVIDIAはGPUDirect RDMAという機能をサポートしている。通常ならば、MPIの通信を行うには、GPUのメモリからホストCPUのメモリにPCIeのDMAを使ってデータをコピーし、また、PCIeのDMAを使って、そのデータをInfiniBandのネットワークインタフェースカード(IB NIC)に転送するという操作が必要である。
これに対してGPUDirect RDMAは、GPUメモリから読み出したデータを送るPCIeのDMAの転送先をIB NICにしてしまう。つまり、いったん、CPUメモリに入れて、それからIB NICに送るという手間を省いている。このため、MPI通信の遅延が減り、バンド幅も向上する。さらにホストCPUのメモリに転送のためのバッファを用意するということも不要になる。
なお、この図では送信側しか書かれていないが、受信の場合はIB NICからGPUメモリに直接DMA転送する。
また、この図はGPUからIB NICへの転送であるが、GPUDirectはGPU間のデータ転送にも使える。

|
|
GPUDirectは、GPUメモリからのDMAの転送先をIB NICとして、CPUメモリにコピーするステップを省いている |
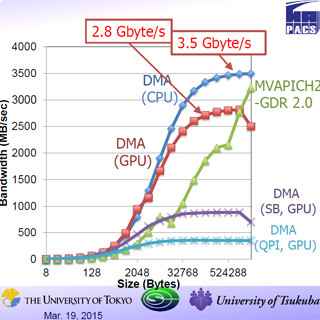
次の図は、GPUDirect RDMAを使うMPIとGPU対応ではあるがGPUDirectは使っていないMPIと、CUDA対応でない一般のMPIの性能を比較したものである。図の横軸はメッセージのサイズで縦軸は通信のバンド幅である。
緑のGPUDirect RDMAを使うMPIの性能が一番高く、データサイズが大きい場合は6GB/sのバンド幅が得られ、1B転送の遅延時間は5.7μsと短い。この遅延の短縮はCPUメモリへのコピーを省いたことが効いていると考えられる。
青のGPUDirectを使わないMPIも大きなデータサイズでは6GB/sのバンド幅となっているが、データサイズが小さくなるとバンド幅が減少している。また、1Bメッセージの遅延は17.97μsと大きい。
そして通常のMPIはバンド幅が2GB/sと前の2つのMPIの1/3の性能に留まっている。また、1Bメッセージの遅延も19.97μsの最大である。遅延はともかく、バンド幅は同じだけ出ても良いと思うのであるが、GPUメモリからCPUメモリへのcudaMemcpyとCPUメモリからIB NICへのDMAが同時並列に実行できていないという問題がありそうである。

|
|
Open MPI 1.8.4でGPU Direct RDMAをサポートした場合、GPU対応であるがGPUDirectを使わない場合、そしてGPU対応でない一般のMPIの性能の比較 |
A、B2つのプロセスで1つのGPUを共用すると、プロセスAのComputeとStreamsの実行とプロセスBのComputeとStreamsの実行は排他的に行われる。

|
|
GPUを2つのプロセスで共有する場合、それぞれのプロセスの処理は排他的に切り替えられ、空き時間ができる |
しかし、NVIDIAはMPS(Multi Processing Service)という機能を提供している。各プロセスからのGPUへの処理依頼はいったんMPSプロセスが受信し、プロセスAのメモリコピーのストリームとプロセスBの計算処理のように、依存関係がないものは並列に実行するようにスケジューリングを行う。このため、次の図のように、隙間がなくなり実行効率を高めることができる。

|
|
GPUへの実行依頼はMPSプロセスがいったん受信して、異なるランクの処理で依存関係のないものは並列に実行するようにスケジューリングする |
ただし、MPSプロセスが間に入るため、多少のオーバヘッドがあるので、まったく並列化ができない場合は性能が低下するので使用すべきでないという。
また、NVIDIAはKepler GPUからHyper-Qという機能をサポートした。CUDAにはストリームというメモリ転送やカーネル実行を行うコマンド列を実行する機能があるが、Hyper-Qは複数のストリームから実行できるコマンドを探して実行する機能で、GPUの空き時間を減らすことができる。
次の図はHyper-QとMPSを使って、処理のオーバラップを引き上げたときの実行状況を示す。

|
|
Hyper-QとMPSを使って、同時に実行できる処理を最大限に引き上げる。上の楕円は異なるプロセスのCopyとComputeをオーバラップ。下の楕円は複数のMPIプロセスのオーバラップ |
次の図はCPUの1コアだけを使い、1ランク/GPUの場合と複数ランク/GPUの場合の性能を5種のアプリケーションで比較したもので、棒グラフの下側の緑の部分は、複数ランクでGPUを共有したことによる性能向上、上の部分はMPSを使った場合の性能の上積み分である。

|
|
5種のプログラムのHyper-Q/MPSによる性能改善。棒グラフの下の部分は1ランク/GPUに対する複数ランク/GPU化による性能向上。上の部分はMPSによる上積み分 |
MPSによる性能向上はアプリケーションを変更する必要はなく、その効果はMPIアプリに留まらない。また、CUDA7からはマルチGPUの環境でもMPSが使えるようになっている。

|
|
MPSはプログラムを変更する必要はないので、使いやすい。また、その効果はMPIを使う場合に限定されない |
さらに実行の並列度を上げる方法として、ノンブロッキングのMPIコールを使う手がある。MPI_SendやMPI_Recvを呼び出すと、送信や受信が完了するまで、呼び出し元には戻ってこない。しかし、MPIにはMPI_Isend、MPI_Irecvという関数があり、このIの付いた関数は送信や受信の起動をすると、その動作の完了を待たないで、呼び出し元に戻ってくる。
次の図の上側のブロッキングのコードでは、最初のMPI_Sendrecvの送信と受信が終わってから、2番目のMPI_Sendrecvを実行するが、下側のノンブロッキングのコードでは2つの受信を起動してから2つの送信を起動している。そして、その後のMPI_Waitallでこれらすべての終了を待ち合わせている。このようにすれば、1番目のMPI_Sendrecvの終了を待ち合わせる時間を有効に使え、性能が上がる。

|
|
MPI_Isend、MPI_Irecvを使うと、送信や受信の完了を待たずに呼び出し元に戻るので、待ち時間を有効に利用でき、性能を上げられる |
まとめとして、MPIを使えば、マルチGPUの環境を抽象化してプログラムを書くことができる。特に、CUDA対応のMPIを使うことにより、プログラムの書き方も容易になるだけでなく、レーテンシの短縮やバンド幅の増加も得られる。CUDA対応のMPIは、OpenMPI、MVAPICH2などのオープンソース、CrayやIBMなどのメーカー系のものが利用できる。

|
|
MPIを使うことで、マルチGPUの環境を抽象化してプログラムを書くことができる。特にCUDA対応のMPIを使うと、記述が容易になるだけでなく、レーテンシやバンド幅の点でも高い性能が得られる |