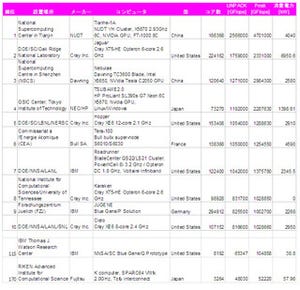
Blue Geneの3世代のマシンの諸元を次の表に示す。

|
|
Blue Gene 3世代の計算ノード諸元の一覧 |
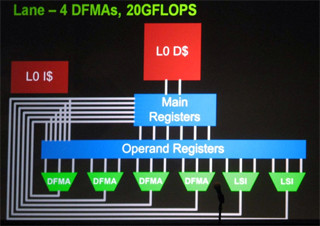
BG/Qのプロセサは、まだ、明らかになっていない点が多いが、IBMブースの説明員から聞いたところでは、チップは18コアで、16コアが計算に使用され、1コアがLinuxを動かす制御用のコアとして使われ、残りの1コアはスペアであるという。そして、各コアは従来の2倍の4つのFMA演算器を備えていると説明された。これらの情報とLINPACKのピークFlops値を組わせると、クロックは1.6GHzと考えられる。プロセサコアは従来の延長で何等かのPowerPCに浮動小数点演算ユニットを強化したものを使っていると予想されるが、詳細は不明である。
プロセサチップのコア数は、BG/Pの4倍、演算器は2倍、そしてクロックも約2倍であり、結果として、倍精度浮動小数点演算のピーク性能は、BG/Pの13.6GFlopsから204.8GFlopsと15倍に向上している。このピークFlopsは、Top500の1、3、4位のシステムに用いられたNVIDIAのFermi GPUの515.2GFlopsには及ばないが、それでも約40%の演算性能がある。また、今回のTop500のデータでは、ピークが104.858TFlopsであるのに対してLINPACKが65.347TFlopsとピーク比は62.3%しか出ていないが、以前のBG/L、BG/Pでは80%強の値を出しており、メモリの増強やチューニングで同等まで持って行けるとすると、チップあたり170GFlops近いLINPACK値が出せることになる。
一方、GPUベースの天河一号Aや東工大のTSUBAME2.0ではLINPACK値のピーク比率は52%わずかに上回る程度である。これらのシステムのCPUとGPUの貢献度を分離することはできないが、GPUも同一比率と考えるとGPU 1チップのLINPACK値は270GFlops程度と言うことができる。そうすると、BG/QのCPUチップはLINPACKでもFermiの63%(現状のBG/Qは47%)の性能を持っていることになる。
Top500 115位の512チップのシステムの消費電力は38.8kWとなっており、単純計算で1チップあたり76Wである。一方、GPUベースのシステムの中でも電力効率の高いTSUBAME2.0でも総電力をGPU個数で割ると331Wとなっており、メインの計算チップ1個あたり4倍強の電力を使っている。これがGreen500でBG/Qが圧倒的に強い理由である。さらに、BG/Qチップは、ノード間インタコネクトのスイッチやコントローラを内蔵しておりDRAMを付けるだけで制御プロセサを含む計算ノードを構成できるが、GPUの場合はCPUやInfiniBandのNIC、そしてIB Switchなどが必要になる。
Blue Geneのプロセサは、初代からEmbedded DRAMのLast Level Cacheを備えており、BG/Qプロセサも32MB(推定)のEDRAMのキャッシュを備えている。このキャッシュ量は、前世代のBG/Pの4倍であり、演算性能の向上比率には追い付いていない。
メモリは初代のDDRから2代目のDDR2を経て、BG/QではDDR3になっている。展示されたマシンのDRAMチップの捺印は判読できないが、プロセサチップはDDR3-1600に対応していると仮定すると、メモリバンド幅は51.2GB/sとなる。ただし、ここでは×8のDRAMチップを表面の36個で、メモリバス幅は288ビットと考えたが、表裏別で576ビットのバス幅とすると、DRAMを両面搭載した場合は、この表の2倍のバンド幅ということもあり得ないことではない。
初代と2代目のBlue Geneチップのインタコネクトは、データ通信路は3次元トーラスで、このトーラスを形成するためのXYZ 3方向の+/-でそれぞれinとoutを持つ6in、6outのポートを持っていた。さらに、それに加えてCollective通信(例えば全ノードの値の合計とか最大値とかを求める)用のバイナリツリーを構成する3in、3outのポートとバリア(全ノードの終了を待ち合わせる)通信のポートを備えていた。
これに対して、BG/Qではノード間の接続は5次元となり、10in、10outになった。一方、Collective通信やBarrier用の専用のネットワークは無くなり、データ通信用の5次元ネットワークの上に仮想チャネルのような形で論理的に実現されているという。この5次元の使い方であるが、1次元は2枚のノードボードをループ状に接続し、3次元で16×16×16のトーラスを構成するという。
この2×16×16×16ノードの塊は8Kノードとなり8筐体のグループとなる。そして、残った1次元で8筐体グループ間を接続する。この8筐体グループ内の接続は電気のケーブルで、8筐体グループ間の接続は光になっている。
BG/Qチップのピーク演算性能は204.8GFlopsであり、1024ノードの筐体当たりの性能は209.7TFlops、8筐体グループの性能は1.678PFlopsとなる。これで20PFlopsを実現するには12グループ96筐体があれば良い。したがって、5次元のサイズは、2×16×16×16×12のような構成になるのではないかと思われる。
計算ノードがアルミ削りだしのヒートスプレッダが付いていると述べたが、BG/Qでは、アルミと銅で出来た水冷のレールにこのヒートスプレッダを密着させるという方法で放熱している。水の通るのは銅パイプであるが、その外側にアルミは張ったのは、異種金属を接触させると、湿気が付くと電気分解などが起こるのを嫌ったのではないかと思われる。

|

|
|
BG/Qの水冷冷却レール |
|
この左側の写真の左右方向に走っているのが冷却レールで、一番手前にヒートスプレッダをクランプで挟んでレールに押し付けている2個の計算ノードモジュールが見える。また、看板の右端の手前にちょっと見えるように、コールドレールの間を水を通す銅のパイプが接続している。なお、8本のレールがあるが、右の写真のように、すべて芋づるで繋がれている。まあ、32計算ノードモジュール全部でも2kW程度であり、Blue WatersのPOWER7 MCM 2個分の消費電力しかないので、冷却上、問題ないと思われる。

|
|
BG/Q I/Oドロアー |
そしてI/Oドロアーは写真の奥の方に8個BG/Qモジュールが搭載され、手前の右側にはPCI Expressスロットがあり10Gbit EthernetのNICが搭載されている。また、I/Oドロアーは空冷であり、BG/Qチップには銅のフィンが付いた放熱板が付けられ、写真の左側にはファンが見える。

|
|
I/OドロアーのBG/Qボード付近の拡大図 |
BG/Qの筐体は展示されなかったが、CADで書いた図は展示されていた。それによると、計算ノードボードはミッドプレーンを挟んで前後に搭載されており、上半分のこれが8段に積まれ、合計16計算ノードボードを搭載している。そして、I/Oドロアーが最大2台搭載できる。筐体の下半分も同じ構成であり、全体では32台の計算ノードボードと4台のI/Oドロアーが搭載できる。そして、電源は筐体最上部に搭載され、下から冷却水のパイプが出ている。

|
|
計算ノードボードのミッドプレーン側コネクタ。180ピンのコネクタが多数並んでいる |