|
|
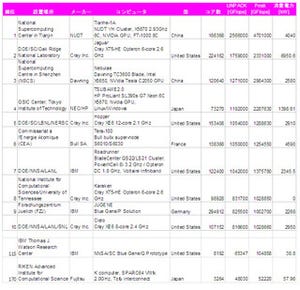
図3 28nmテクノロジのプロセサの消費エネルギー |
図3に示すように、28nmプロセステクノロジで作ったプロセサでは、64ビットの倍精度浮動小数点演算は20pJで実行できる。しかし、256ビット幅のバスで数mm程度の距離を信号伝送するには26pJ、10mmの伝送には256pJ、チップの対角線のもっとも遠いところまでの伝送は1nJを必要とする。また、8KBのSRAMから256バイトを読み出すのは50pJ、DRAMのRead/Writeには16nJ、他のチップへの信号伝送には500pJを必要とする。
したがって、消費電力を抑えるためには、信号の伝送距離を短くしできるだけレジスタ、その次はキャッシュやローカルメモリという風に近くにあるデータを使って演算することが必要であるという。

|
|
図4 Echelonシステムの実行モデル |
Echelonシステムの実行モデルでは、全部のメモリは統一されたGlobal Memory Spaceを構成し、そこに処理を行うスレッドや処理されるオブジェクトが存在する。そして、図4の一番下に書かれたスレッドの実行部分(SM)から階層的にメモリが存在し、実行に必要なスレッドやオブジェクトをできるだけ近くのメモリに持ってきて実行を行う。また、必要な場合にはメモリ間のブロック転送や、メモリ階層を跳ばしたLoad/Store、他のスレッドのメモリへのActive Messageなどの手段を使って消費エネルギーを抑える。
このため、1024個に分割されたL2キャッシュを持ち、実行するアプリケーションの特性に対応して、全部をフラットな大きな2次キャッシュにしたり、分割して論理的な各階層のメモリとしたりする再構成可能(Reconfigurable)な構造とするという。
また、図5に示すように、各コアは4個の倍精度浮動小数点のFMA(Fused Multiply Add)演算器と2個のロードストアユニットを持っているが、現在のFermiのCUDAコアと異なるのはメインレジスタとこれらの実行ユニットの間にオペランドレジスタが入っている点である。GPUのメインレジスタは容量が大きく、アクセスするのに大きなエネルギーを必要とする。これを小容量のオペランドレジスタでキャッシュすることにより演算処理あたりのエネルギーを削減する。

|
|
図5 各コアの構成 |
このような方法により演算あたりの消費エネルギーを減らし、1筐体で38kWを実現するという目論見である。これが実現できると、筐体あたり2.6PFlops、効率68.4GFlops/WとExtreme-Scale Computingプロジェクトの目標をクリアする。
そして、このEchelon筐体を400個並べてDragonflyインタコネクトで接続すると、~1ExaFlops、~15MWのシステムを作ることができる。
なお、各コアは4FMAユニットを持つので8浮動小数点演算/サイクルで処理が行える。これが各SMに8個あり、チップ全体では128SMであるので、全体では8K浮動小数点演算/サイクルとなる。そして、性能が20TFlopsであるので、クロックは2.5GHzという計算となる。また、 38kWという筐体あたりの消費電力を単純にノード数で割ると、1ノードあたり約300Wとなる。Echelonのプロセサチップの消費電力は現在のハイエンドGPUと同程度の200W程度で、それにDRAM CubeやHigh Radix Router Moduleの消費電力やDC/DCコンバータのロスなどを加えて300Wという感じではないかと思われる。
この基調講演でNVIDIAが考えているハードウェアについてはかなり明らかになったが、いくつか疑問もある。このEchelonがMaxwellの次世代とすると2015年末ころに出荷するプロセサで、2014年のPhase-1の成果に間に合わせるのは時期的に難しいし、一方、2018年の最終ターゲットに向けた仕様であるとするとアグレッシブさが足りない。また、各Echelonチップには8個のシングルスレッド性能の高いプロセサが含まれているが、64ビットアドレス化したARMプロセサで行くのか、それとも別のプロセサを開発するのかも興味深い選択である。

|
|
図6 基調講演を行うBill Dally氏 |
そしてDally氏は、図6のように、(1)GPUコンピューティングはTop500で第1位になり、Green500でも上位を占めている。(2)GPUコンピューティングにより消費電力を減らしてExaScaleを実現する。(3)GPUは単なるアクセラレータではなく、GPUこそがコンピュータである。(4)真の挑戦は、ソフトウェアであると結んだ。
Dally氏は、ExaScaleのハードウェアはこの基調講演で述べたような方向で実現可能であるが、このような構造のマシンで広範囲な問題を効率よく処理できるか、そしてプログラムが容易に作成できるようなソフトウェアシステムが作れるかなどが大きな問題という。
さらに、近くのメモリだけで大部分の処理ができないと、消費電力が大きくなってしまうので、データやスレッドプログラムの配置の局所性に配慮したコンパイラや自動チューニングツールなどが必要としている。今回の基調講演では、これらのソフトウェア関係についてはほとんど触れられなかったが、Echelonチームのオークリッジ国立研究所や多くの大学がこれらの課題に取り組むことになると思われる。