Roadrunnerシステムは分散メモリ型のスパコンであり、これらの計算ノードのメモリは、他の計算ノードからは見えない。このため、MPI(Message Passing Interface)を使って通信を行っている。MPIは、マルチプロセサシステムのプログラミングでは一般的に用いられている標準のインタフェースであり、相手先の計算ノードを指定して、データの送信、受信を行うMPI_SEND、MPI_RECVや、グループの全計算ノードに同報するMPI_BCAST、グループの全計算ノードからデータを受け取るMPI_GATHERなどの機能がある。RoadrunnerはこのMPIを用いて、各計算ノードの処理に必要なデータを送ったり、計算結果を受け取ったりして並列処理を行う。
このMPIはクラスタでは標準的に用いられているが、このRoadrunnerでは、OpteronとPowerXCell 8iプロセサの中のPPE、そして、計算処理の中心となるSPEという3階層のプロセサがある。MPIで受信したデータはLS21ブレードのOpteronのメモリに入り、それを使って計算を行うためには、データをQS22ブレードのメモリに送り、さらに、SPEのローカルメモリに転送してやる必要がある。ここで、更に面倒なのがEndianの違いである。x86アーキテクチャのOpteronは最下位バイトが最初に来るLittle Endianであるが、PowerPCは、最上位バイトが先頭に来るBig Endianである。従って、OpteronとPowerXCellの間のデータ転送は、単なるデータの授受に加えて、Endianを逆転してやる必要がある。
この面倒な作業をやってくれるのが、DaCS(Data Communication and Synchronization)というドライバレベルのソフトウェアである。DaCSは、OpteronとPowerXCellのメモリ間のDMA転送や、MPIと同様のSend、Receive、メールボックスなどの機能をサポートしており、更に、バリアやMutexなどの同期機能を持っている。そして、DaCSは、転送効率を上げるためのダブルバッファリングや、Endianの変換もやってくれる。
その上にALF(Accelerator Library Framework)というライブラリが載っている。ALFは大きな塊のデータ処理をSPEが扱える大きさの小さな塊に分割し、その小さな単位の処理をキューイングする。そして、SPE側の実行状態に応じて、処理が途切れないように、次々と処理単位の仕事を送り込み、並行して処理結果を受け取る。このようにALFを使うことにより、アプリケーションのプログラマは、各計算ノードにある合計32個のSPEのスケジューリングを直接意識することなく、効率の良い並列処理を行うことができるようになっている。
そして、両者のメモリがアンバランスであると、このようなデータ転送が円滑に行えないということで、次の図のように、PowerXCellプロセサ1個にOpteronのコア1個を対応させ、双方のメモリを4GBと同量とする設計コンセプトで作られている。
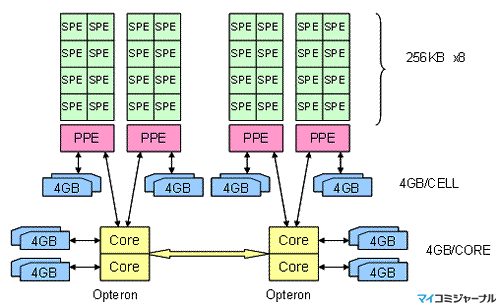 |
Equal Memory Sizeの設計コンセプト |
LANLの説明資料を基にRoadrunnerの概要を説明したが、LANLのWebサイトには、もっと色々な情報が公開されているので、興味のある読者は、直接、アクセスすることをお勧めする。
 |
詳細なRoadrunnerの情報が公開されているサイト(出典:LANLのRoadrunnerホームページ) |
なお、このスライドの右上に書かれているロゴマークの疾走する鳥がRoadrunnerである。