


図2のようにTsが0.2%以上の場合は、カーブは右肩下がりになる。図2からは読み取り難いかもしれないが、Tsが0.1%より小さい場合は右端の1024コアの場合の性能が一番高いが、0.2%と0.5%のケースでは256コア程度の方が良く、さらにTsの比率が増えると64コア以下が適していることになる。
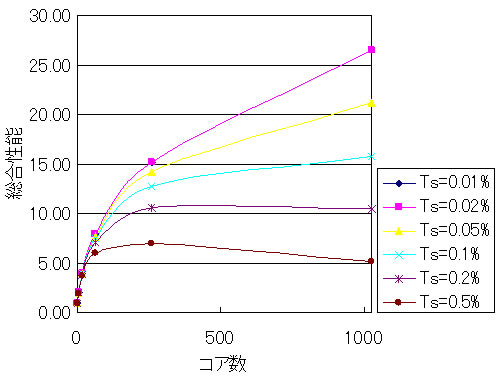 |
図2 ポラックの法則によるマルチコアプロセッサの性能 |
つまり、コア数を増やせば性能が上がるというわけではない。Borkar氏によると、コア数が増えるに従って、ソフトウェアもムーアの法則に従ったスケールにしなければならないという。
また、マルチコアで性能が上がると、それにデータを供給する側の問題も出てくる。例えば、100Gバイト/sのメモリバンド幅が必要になったとしよう。このとき、2Gbpsの高速シリアルインタフェースを用いたとすると、必要となるピンの数は800にもなる。かなり楽観的に見ても、メモリの接続だけでI/O部分は25Wを消費することになる。
この消費電力を減らすには、接続距離を2cm以下に短縮し、シングルエンドの低消費電力のドライバを使うことが考えられる。この場合、データ伝送速度は下がり、さらに多くのピンが必要となる。この問題を解決するために、Intelではマルチコアプロセッサにおいて「Through Silicon Via」と呼ぶプロセッサとメモリをチップ内でスタックする技術を開発しているという。
プロセッサとメモリの面積が同程度の場合、このメモリはメインメモリとしては不十分である。そのため、このメモリをキャッシュメモリとして使う。そしてキャッシュミスが起きた場合だけメインメモリをアクセスするという方法により、キャッシュメモリからメインメモリへの伝送速度は100Gバイト/sを下回るため、メモリと接続するためのピン数を減らすことができるという。
つまり、将来は1,000コアという大規模なマルチコアプロセッサを作ることはできるようになるが、それには消費電力やソフトウェアのスケーラビリティといった重要な問題を解決する必要があるという内容の発表だった。










