CDCのSTAR-100
STARはSTringとARrayを扱うという意味で名付けられており、100は100MFlopsを意味していた。CDC 7600はピークで36MFlopsであったので、STAR-100は、その3倍程度のピーク演算性能を目指していた。
STARもCPUとPPUを持つアーキテクチャのマシンであるが、スパコン調達のASCII化に対応するため、1語を64bitとして、1文字を8bitとしたマシンである。STARがCDC 6600/7600と大きく異なっているのは、ベクトル演算をサポートし、これで高い性能を実現しようとした点である。ベクトル演算の場合は、データのメモリからの読み込み、浮動小数点演算、演算結果のメモリへの書き戻しをパイプラインで処理することにより、1クロックサイクルごとに、次の要素の演算を開始することができる。このため、25MHzクロック(40nsサイクル)で動作する2本のパイプラインで50MFlops、32bit演算の場合は、各パイプラインが2演算を並列に処理できるので、100MFlopsの性能が出るという計算である。
浮動小数点演算器は1サイクルで演算を行うには複雑すぎ、クロック周波数を高めて性能を上げるため、5~10段のパイプラインで作られるのが一般的である。この事情は現在でもほとんど変わっていない。演算器をパイプライン化すると、前の演算が実行中であっても毎サイクル新しいオペランドを受け取って演算を開始することができる。
図1.30の上側の図のように、通常のスカラ命令の場合は、命令の読み込み、解釈、メモリからのオペランドのフェッチなどのセットアップ作業が演算の前に必要になる。スカラ処理の場合は、このセットアップと演算のペアが毎回必要になる。
しかし、連続アドレスのデータ間の演算を行うというベクトル命令の場合は、図1.30の下側の図のように、最初のセットアップはスカラ命令の場合より長く掛かり、1回目の演算の終了は遅いが、2回目以降はセットアップは不要であり、パイプライン演算器を有効に使って毎サイクル1つの演算を実行することができる。このため、ベクトル演算を行うと1命令ずつのスカラ実行より高い演算性能を実現することができる。
なお、この図はセットアップ同士はオーバラップさせることができないという前提で書かれている。一方、演算は4段のパイプラインで、毎サイクル新しい演算を開始できるとして描かれている。そして、ベクトル処理のためのセットアップは、スカラ処理の場合よりも長い時間がかかると想定している。ただし、STR-100の場合は、ベクトル処理のデータはメモリから読み込む必要があり、この図の比率よりもずっと長い時間がかかっていると考えられる。
-

図1.30 スカラ処理とベクトル処理の実行の様子

また、STAR-100は仮想化をサポートしているという点でもCDC 6600/7600とは異なっていた。
STAR-100の主任アーキテクトは、Crayを助けてCDC 6600の大部分の詳細な設計を担当したJames Thorntonである。
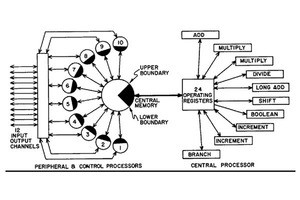
STAR-100のブロックダイヤは、図1.31のようになっており、2つの浮動小数点演算パイプを備えている。パイプ1は、加算、乗算専用のパイプラインで、パイプ2は浮動小数点数の加算、乗算、除算に加えて、スカラ命令の処理も含めて、その他の演算も行う多用途のパイプラインである。
STREAMユニットが命令を解釈し、「STRAGE ACCESS CONTROL(SAC)」に指示して、メモリから2つの入力ストリーム(ベクトル)を読み、パイプ1あるいはパイプ2で演算させて、演算結果の出力ストリームをメモリに書き戻させる。ベクトルの長さは、最大、64K要素まで指定することができるようになっている。このように、長いベクトルのオペランドであるので、レジスタにオペランドを保持するのは現実的でなく、メモリからオペランドを呼んで演算し、結果をメモリに書き戻すという構造を取らざるを得なかった。
メモリは、32バンク構成で、512バイト単位でアクセスされる。メモリは磁気コアでできており、アクセスタイムは1.28μsであった。メモリのバンクコンフリクトが無ければ、1.28μsで8バイトのデータを64個アクセスできるので、1データあたりは20ns、つまり、50Mデータ/秒のアクセスができる。これが性能の上限で、64bit浮動小数点の加算や乗算のピーク性能は50MFlopsである。半分の32bitデータの場合は、2倍の100MFlopsとなり、STAR-100の100MFlopsになる。
-

図1.31 STAR-100の基本構成。2つのベクトルパイプラインを持ち、メモリ間のベクトル演算を行う (出典:Charles Purcell,The Control Data STAR-100---Performance Measurement;May 1974 AFIPS '74: Proceedings of the May 6-10, 1974, national computer conference and exposition)

しかし、これは充分に長い(要素数の大きい)ベクトルの演算を行う場合で、ベクトル長が短いと、セットアップのメモリをアクセスする時間が見えてしまい性能が出ないという問題があった。このため、注意深く最適化された問題では高い性能が得られる場合はあるが、多くの一般的なプログラムでは、あまり性能が出ないマシンと言われた。
このため、ローレンスリバモア研究所(LLNL)に2台、NASAに1台と、STAR-100は3台しか売れず、ビジネス的には失敗であった。この失敗により、James ThorntonはCDCを去ることになる。
-

図1.32 STAR-100のキャビネットの配置中央の縦の部分が、SACとストリームという制御部分で、上部にメモリ、下部に演算器が付いている (出典:Charles Purcell, The Control Data STAR-100---Performance Measurement;May 1974 AFIPS '74: Proceedings of the May 6-10, 1974, national computer conference and exposition)

(次回は5月11日に掲載します)