
今年6月に開催されたVLSI Symposiumで、Intelは論文だけで12本。Short Course(技術講座)なども含めると15もの発表を行っている。そのうちの目玉がIntel 4プロセスの詳細である。この内容をもう少しご紹介したいと思う。
Intel 4は、Intelにとって久しぶりの全く新しいプロセスである(Photo01)。10nm SuperFinとかIntel 7はいずれもIntel 10nmの延長にあるプロセス(Intel 7は、以前は10nm Enhanced SuperFinという名称だった)であり、この世代まではSAQP(Self-Aligned Quadruple Patterning)を利用したArF+液浸のQuad Patterning(といってもSADPを2回やるだけなので、実質3回)の露光で回路パターンを描画していたが、Intel 4では初めてEUV露光を利用する事になる。
-
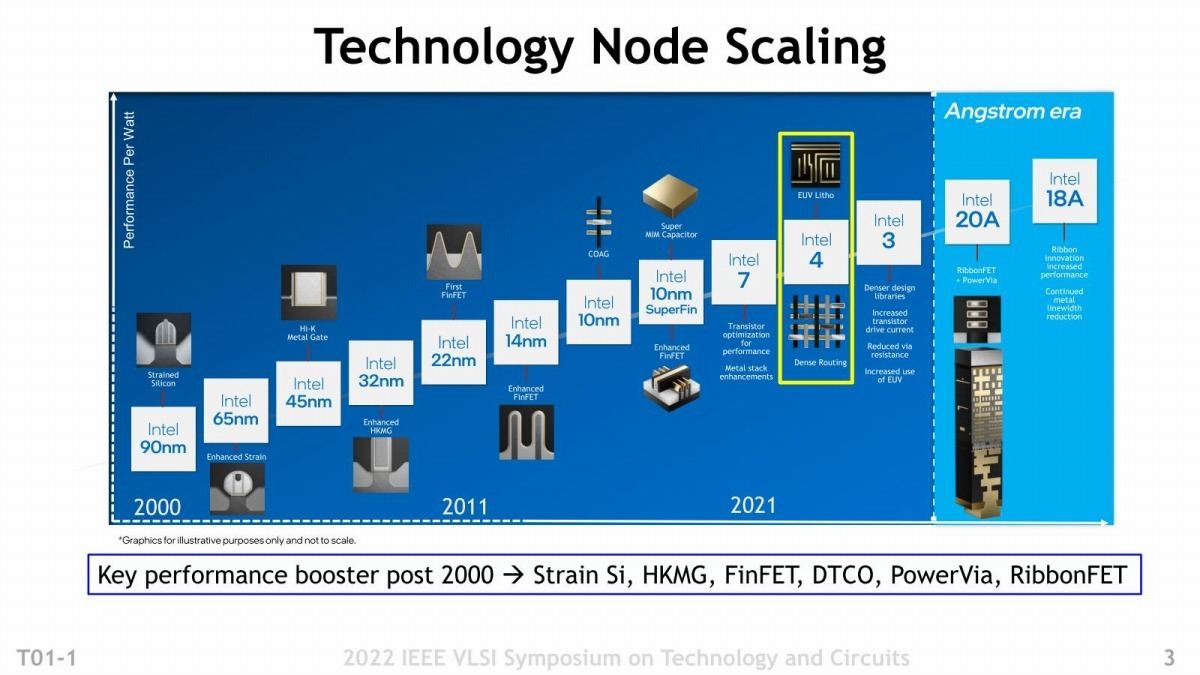
Photo01: 実際には14nm世代も14nm/14nm+/14nm++と複数あったし、10nm世代もこれ以外にもう一つ(Cannon Lakeだけで利用)もあったが、まぁそのあたりは敢えて出さないのだろう。

そのIntel 7の大まかな特徴がこちら(Photo02)。High Performance Libraryを利用した場合同士で比較して2倍の密度を実現し、また同一消費電力で20%動作周波数を引き上げられる、としている。では具体的にこれらをどうやって実現したのか? という話であるが、まずは配線密度の話。
-

Photo02: まぁそりゃSAQPをEUVにするだけで簡単になるのは当然である。

-
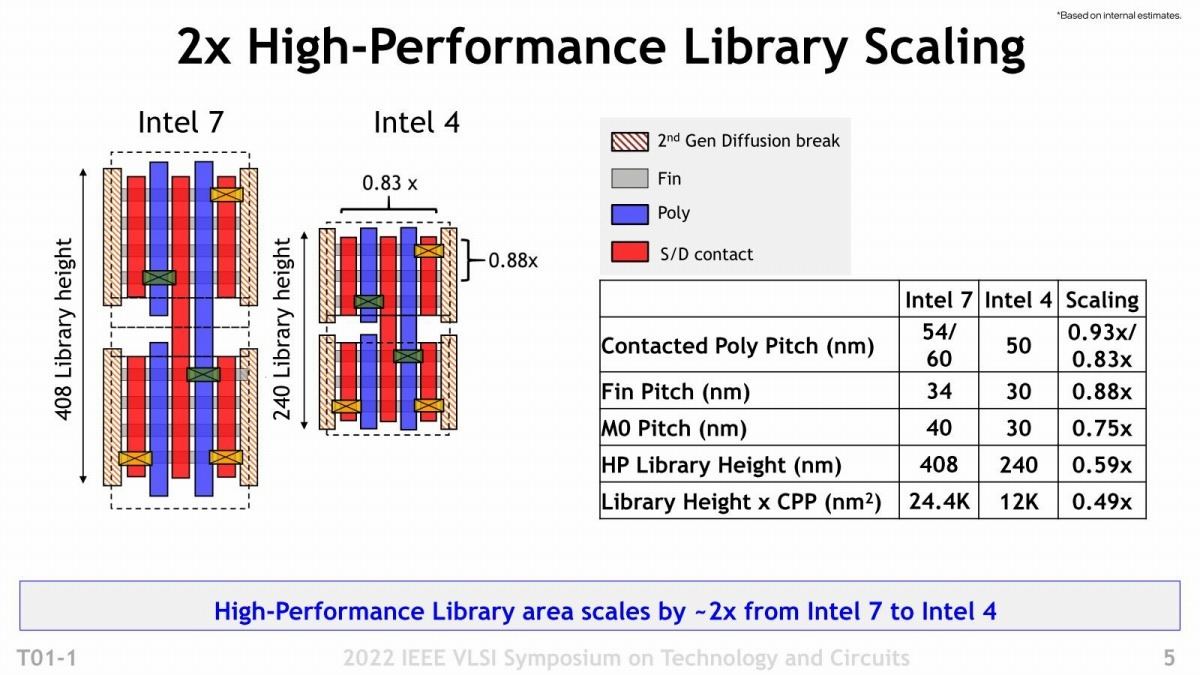
Photo03: Intel 4では3 Finでも十分な駆動電流を確保できたという話になる訳だが、そのあたりはもう少し後で。

Photo03はHigh Performance Library同士の寸法比較であるが、
- CPP(Contact Poly Pitch:図で言えば縦方向の配線密度)が0.83倍
- Fin Pitch(図で言えば横方向の配線密度)が0.88倍
になっている。またこの図には直接は出てこないが、M0(一番トランジスタに近い配線層)の配線ピッチも40nm→30nmに縮小されており、この結果としてライブラリの幅は0.83倍、高さが0.59倍になったことで、面積は0.49倍になった、という話である。実際はこれに加え、
- 2つのトランジスタの間の間隙(Dummy Gate)が、Intel 7では2 Fin分だったのが、Intel 4では1 Finに減っている。
- Finの数そのものも、Intel 7では4 Fin構成だったのが、Intel 4では3 Finになっている。
の2つの変更がある。こうした合わせ技によって、CMOSトランジスタ自身の面積を半分に減らす事が出来たという訳だ。
COAG(Contact Over Active Gate)についてはIntel 7に引き続き採用されている(Photo04)が、Gen 2 COAGとGen 1 COAGの違いは特に説明もなく、今一つ良く判らない。強いて言えばContact Gateの材質が異なる(後述)ので、そのあたりがGen 2という事かもしれない。
-

Photo04: 一番左がIntel 10nmで、配線層と接続するためのVIA(貫通電極)を、トランジスタ構造の外に置いている。これをトランジスタ構造の中に置くのがCOAGで、これは引き続きIntel 4でも採用されている。

また上で書いたDummy Gateの削除の話がこちら(Photo05)。Y軸方向の距離を最小限に詰める事で、高さを408nmから240nmに詰められた格好だ。ちなみにX軸方向に関して言えば、既にIntel 10nmの世代でSingle Diffusion Breakを採用しており、なのでIntel 4でX軸/Y軸共にSingleになった格好だ。
-
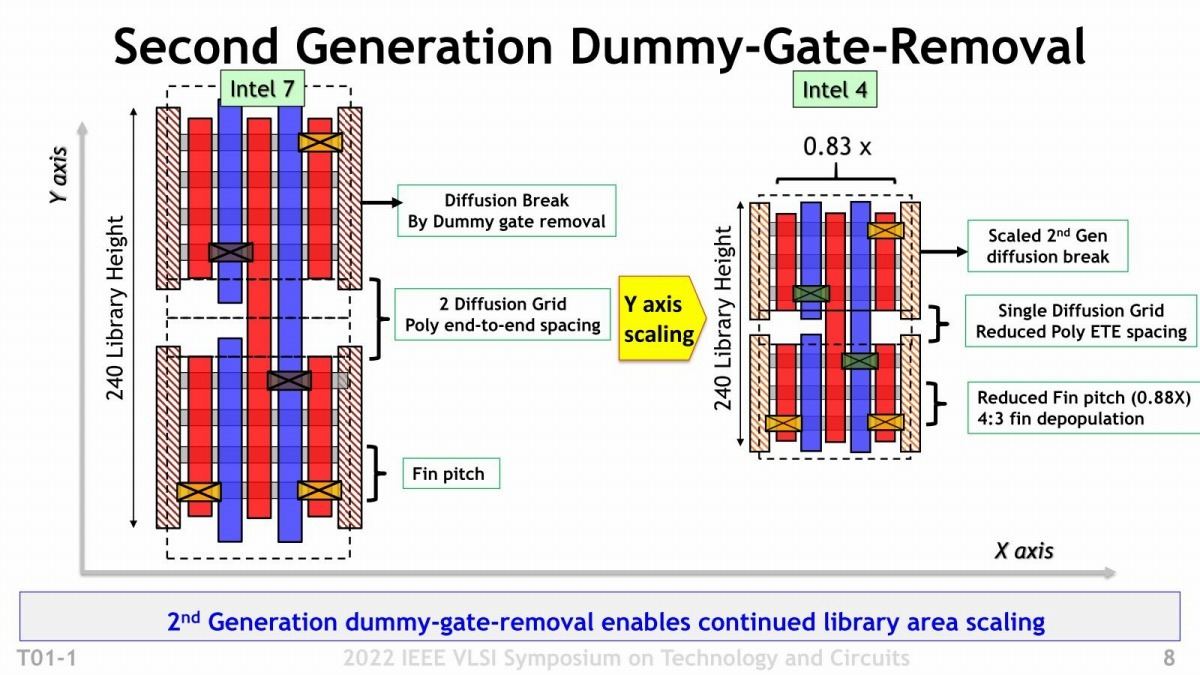
Photo05: この図ではIntel 7も"240 Library height"と書いてあるが、これは"408 Library height"の間違い(Photo02参照)。

次にDesign Ruleについて。Intel 7とIntel 4のMetal Pitchを比較したのがこちら(Photo06)。平均するとやや微細化が進行している格好だが、それよりも大きいのは材質の違いである。元々Intel 7というかIntel 10nm世代が難航した理由の一つに、配線層のElectromigrationがあった。要するに配線層の劣化である。以前ここでも説明したが、Electromigrationは、配線の幅が電子の平均自由行程と呼ばれるものより短くなると、急激に起きやすくなる。この数値は材質によって異なるが、銅だとおよそ40nmほどで、M0/M1はこれを遥かに下回る(Photo06で示されているのは「配線同士の間隔」であって、配線そのものの幅ではない。だからIntel 7のM0だと、40nmということは無く、まぁ良くて半分の20nmになるし、M1は18nm程度と考えられる)。Intel 7世代でM0/M1にコバルト(CO)を利用したのは、コバルトの場合は電子の平均自由行程が7.8nm~11nm程度と銅よりもはるかに短いために、Contact GateとかM0/M1の様な微細な配線に使ってもElectromigrationが発生しにくい。ただコバルトは銅よりも遥かに抵抗が高い(銅の6倍)という問題があり、こちらが配線遅延の原因になりかかっていた(というか、Intel 7がそれほど動作周波数が上がらない要因の一つになっている気がする)。この問題に対し、IntelはここにeCu(Enhanced Cu)と呼ばれる新しい構造を導入した。eCuの構造はこの後説明するが、このeCuをM0~M4の5層に利用している。
-
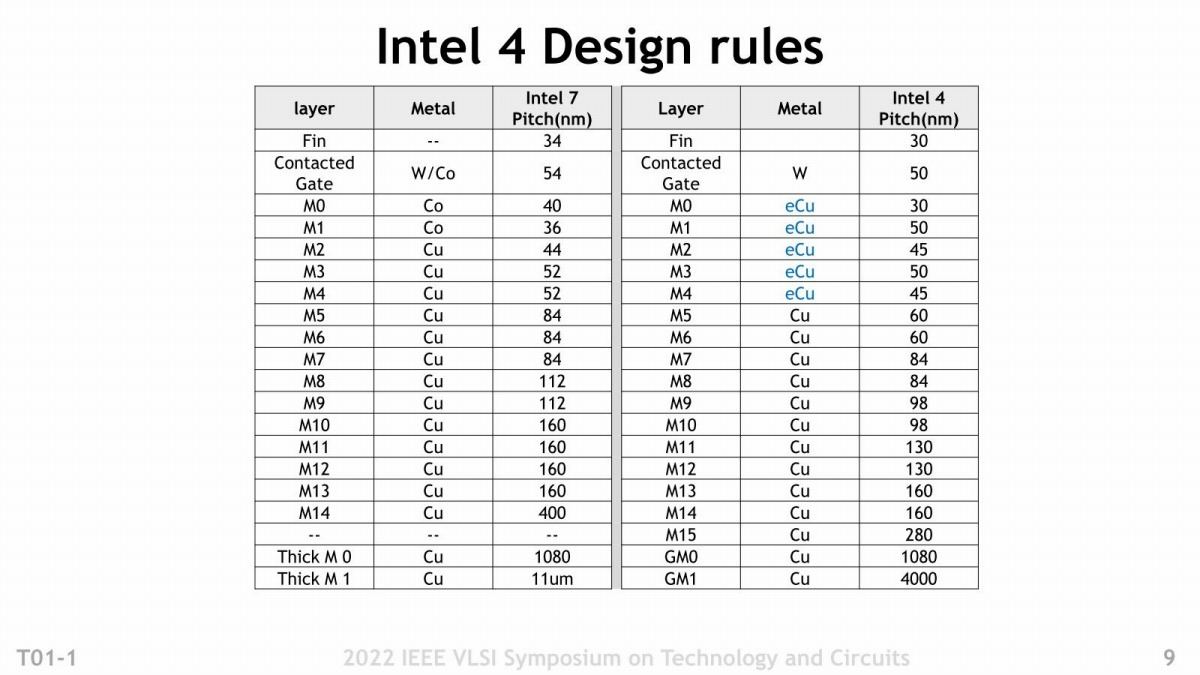
Photo06: Intel 4では配線層が1層増えて18層になっている。

そのeCuの構造がこちら(Photo07)。Intel 7の場合、M0/M1はタンタル(Ta)をバリア層としたコバルト配線を利用し、それ以外の配線は窒化タンタル(TaN)をバリア層とした銅配線を利用していた。これに対し、eCuでは銅配線の外側にコバルトのライナー層を構築、これをタンタルのバリア層で覆う仕組みにした。
-
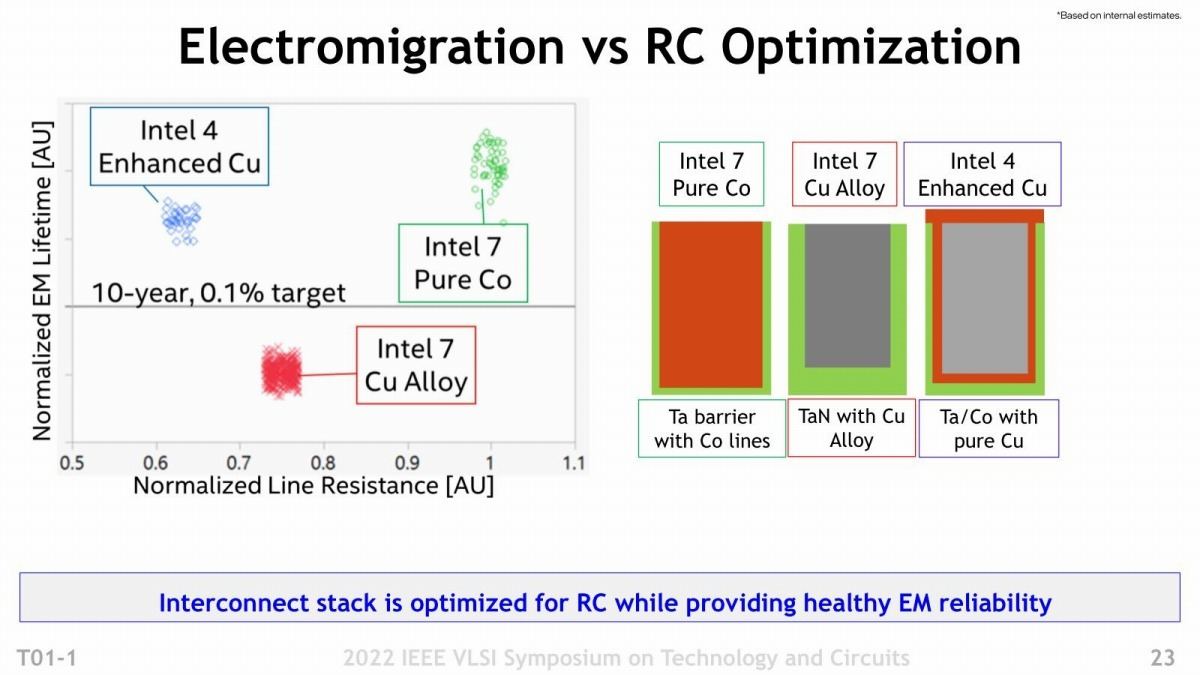
Photo07: 左のグラフ、横軸は抵抗値で縦軸がElectromigrationを発生するまでの時間である。中央の水平線は「10年後に0.1%の確率でElectromigrationが発生する事に相当する寿命」であり、eCuを利用する事で10年程度の製品寿命が確保できるわけだ(おまけに抵抗値はコバルト配線の半分である)。

実はこの方式、Globalfoundriesが2017年のIEDMで提案したやり方と同じである。最終的にGlobalfoundriesは7nm世代への移行を中止したから、実装したのはIntelが先であるが、図を見るとeCuの構造は抵抗値を下げながらElectromigrationへの耐性が高い結果になっているとされる。Intel 4はIntel 7に比べて同じ電力で動作周波数が20%高められるとしているが、その中にはこの配線層の抵抗減も寄与している部分はあるだろう。
次が露光の話。明示されていないが、恐らくIntel 4ではトランジスタ層に加えてこのeCuを利用するM0~M4にEUV露光を利用しているとされる(Photo09)。この効果であるが、まずマスクがよりシャープに可能となり、加えて何しろ1回の露光で処理が済むから、プロセス数で言えば3~5倍効率化が図れる、とする。もっともこれ、プロセス数で比較しているから減っている訳だが、肝心の処理時間で言えば現時点でのEUVではまだスループットがそう高くない。勿論これまでだと露光→CMP→積層を繰り返していたのが1ターンで済むから、時間が減らない訳ではないのだが、露光そのものの時間は結構長くなると思われ、差引すると微減位ではないかと思う。ちなみにマスク枚数とプロセス数を比較したのがこちら(Photo10)で、一応マスクの枚数などは減っているが、コストそのもので言えばまだEUVのマスクが高価な事を考えると、削減効果がどの程度あるのかは不明である。
-
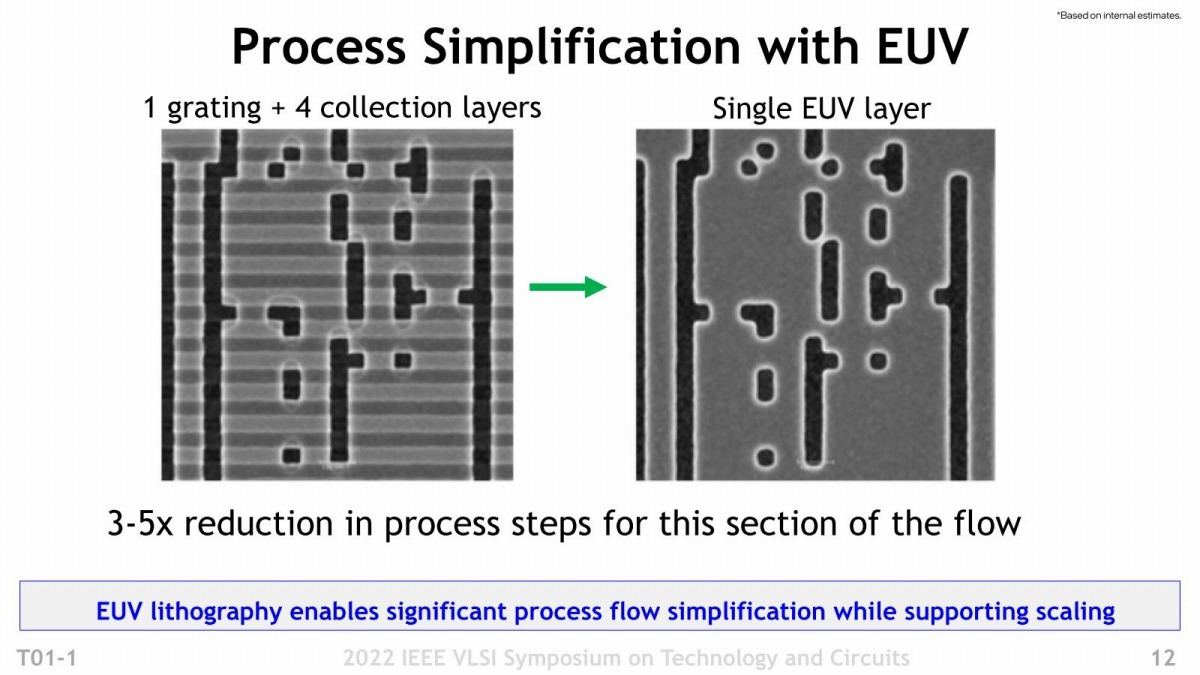
Photo08: 例えば左から2つ目の縦方向の溝が、SAQPだと微妙にガタガタしているのがEUVだと綺麗な直線になっているのが判る。これだけでも大きな違いである。

-
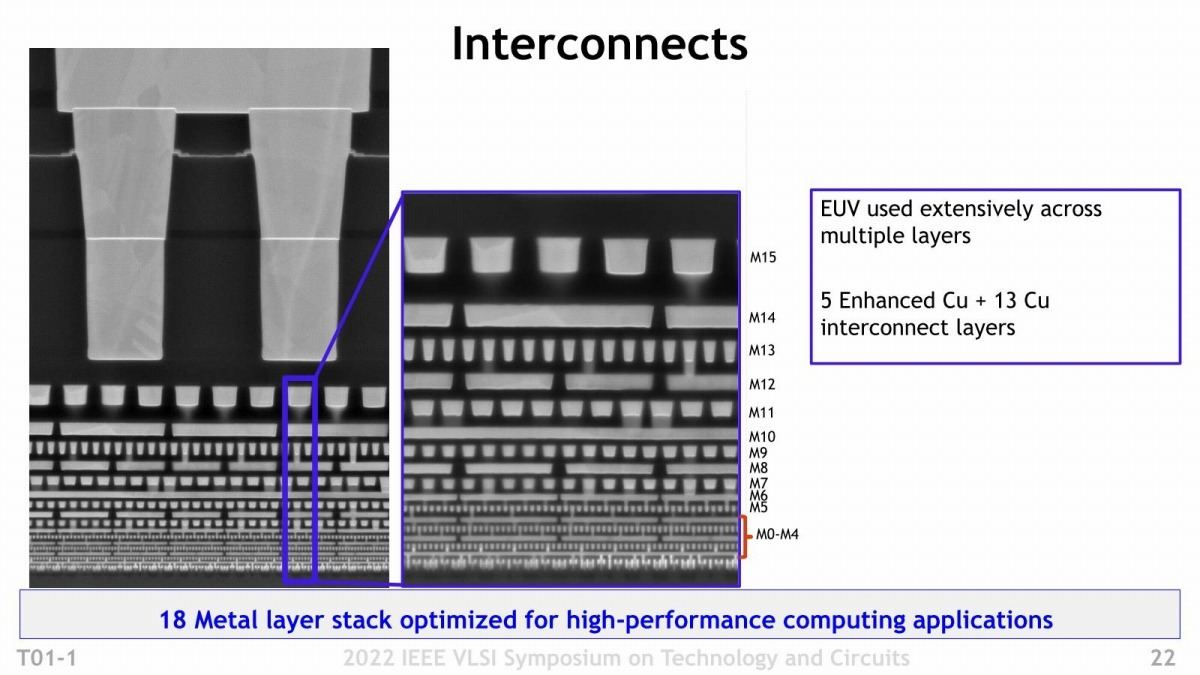
Photo09: これは要するにM0~M4がLocal Interconnect、M5~がGlobal Interconnectと扱われているという事と思われる。

-
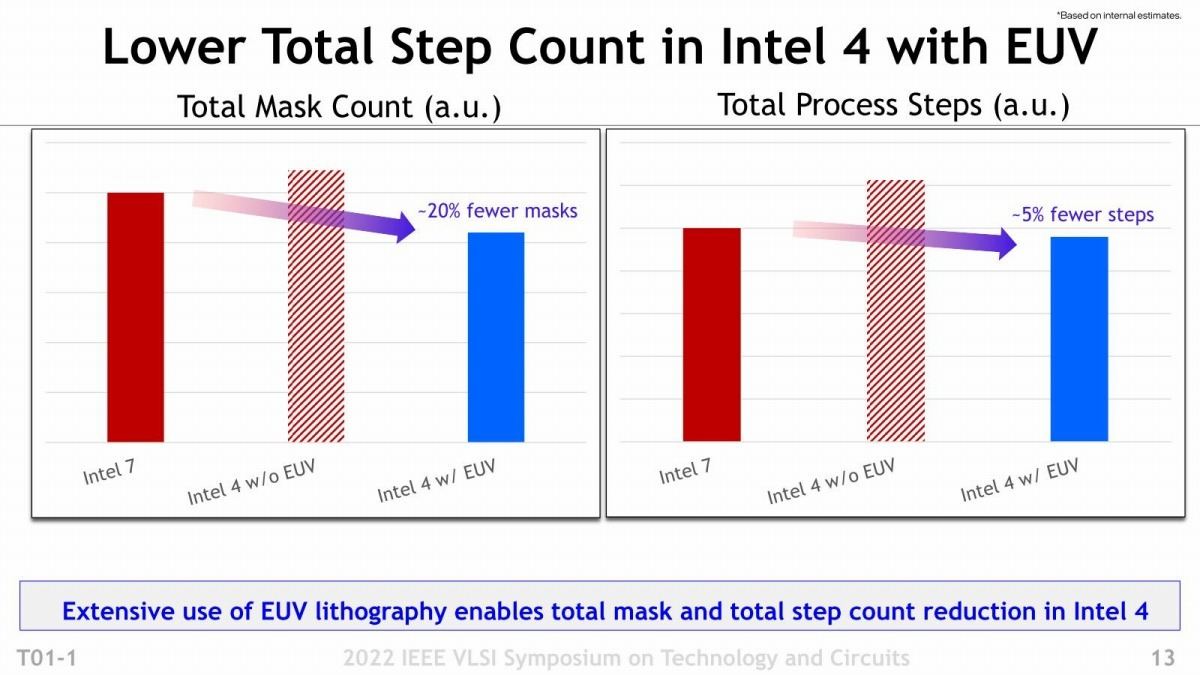
Photo10: 基準はIntel 7で、同じ製品をIntel 4でEUV無しとEUVで比較したもの。数字はIntel 7である。あんまり大きく減らないのは、そもそも配線層も上の方はEUVを使わなくても良い(どころか、ArF+液浸のSingle Patterningで行ける)から、枚数削減はそれこそトランジスタ層+M0~M4に限られる事、それとIntel 4では配線層が1層増えているのが主要因だろう。

ただEUVの効果はもう一つあり、それはSAQPに比べてはるかに精密にパターンを描画できることだ。Photo05でDummy Gateを1本減らせるとしたが、これはEUVがあって初めて可能になったことだ(Photo11)。
-
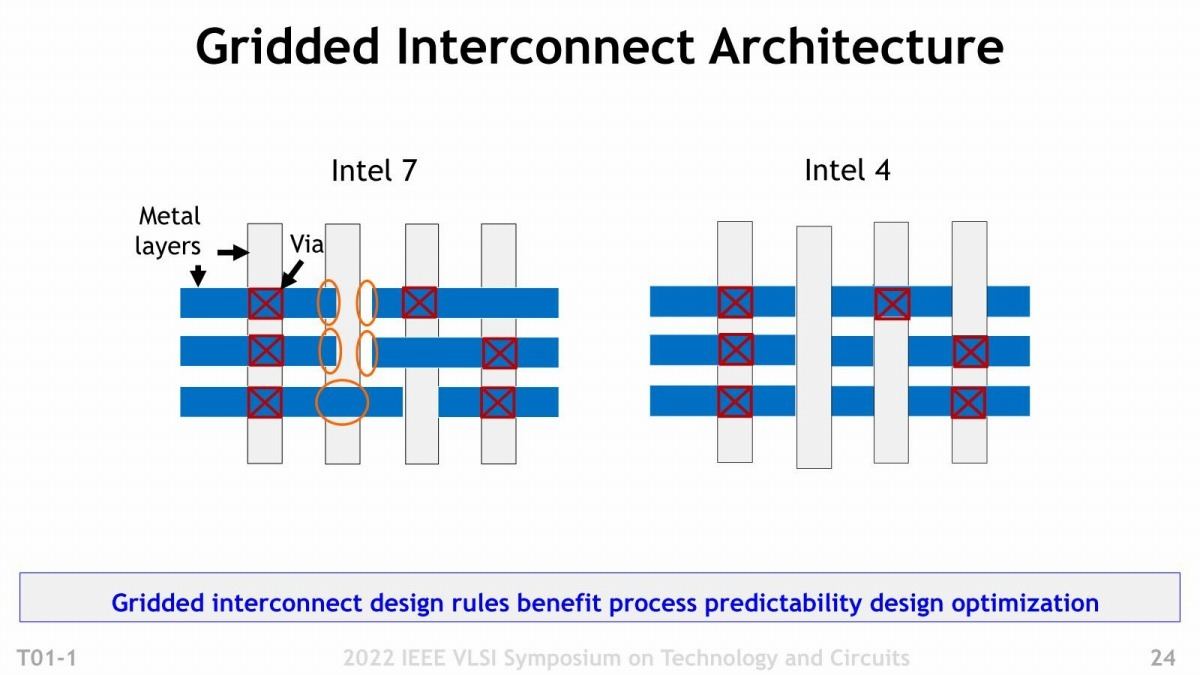
Photo11: SAQPだとどうしても配線のはみ出しとかがあるので、Single Dummy Gateだと配線が接触してしまう事があり得る(のでDouble Dummy Gate構成で明示的に切り離す必要がある)。EUVにすることで精密に配線長を管理できるようになったので、Single Dummy Gateで対応可能になった訳だ。

次に性能の話。先に同じ電力なら動作周波数を20%引き上げられるとしたが、その具体的な結果がこちら(Photo12)。Intel 7で0.65V駆動の場合、21.5%の向上が可能としている。ちなみに上限は最大1.3V程度まで可能となっているようだ。動作周波数がそれほど高くない(Intel 7でも3.3GHz程度)のは、これはx86ではなく"Industry Standard Core"とされており(具体的には不明)、恐らくはArmのCortex-A76とかその辺を利用しているためだと思われる。それよりも6VT(電源電圧が6種類)と8VT(同8種類)の2種類のオプションが提供されているのがちょっと面白い。右側に示すように、正確にはNMOSとPMOSそれぞれに3種類ないし4種類の電圧を利用可能(NMOSは190mV刻み、PMOSは180mV刻み)になっており、これで性能と消費電力のバランスを自由に調整できる、としている。おそらく6VT(要するに3種類)の方はHVTがなく、ULVT/LVT/SVTの3種類のトランジスタを利用して回路を構成する分消費電力は下げられるが、3GHzを超えると急激に消費電力が増える。一方8VTの方はこれに加えてHVTが利用可能で、クリティカルパスにこれを利用する事で、3GHzを超えても消費電力の増え方がやや緩やかになるという感じだろうか。またSRAMに関して言えば、HDC(高密度)とHCC(高速)の2種類が提供され、HDCだと25%ほどSRAMセル数が増やせることになるとの事であった(Photo13)。またMIM Capacitorについては、Intel 7世代に対してほぼ倍の容量を提供するとしており、これで回路の安定動作に貢献するとしている(Photo14)。なんで安定動作に繋がるか? といえば、このMIM Capacitorをパスコンとして使う事が可能だからで、これは動作周波数を引き上げるのに有利である。
-
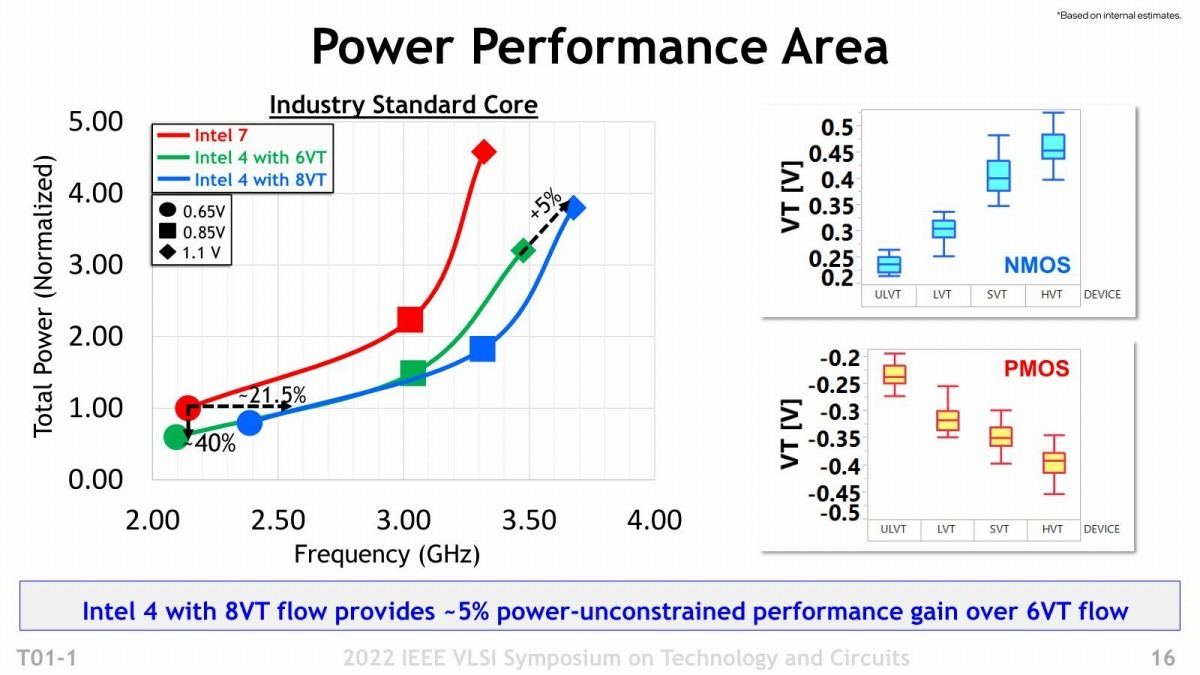
Photo12: むしろ同じ動作周波数だと、消費電力を40%程度下げられる方が効果としては大きい気がするのだが、まぁこの辺は商品構成としてどっちに振るかの問題だろう。

-
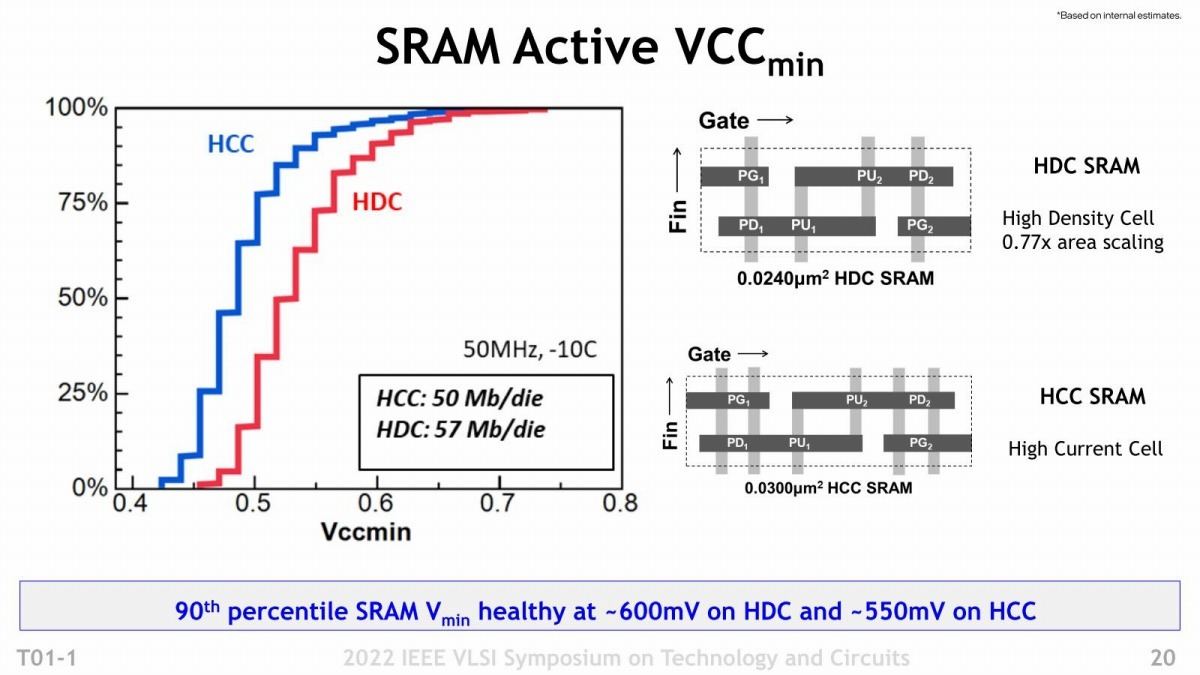
Photo13: HCCは0.55V、HDCは0.6V前後で全体の9割のSRAMセルが正常動作するとされる。

-
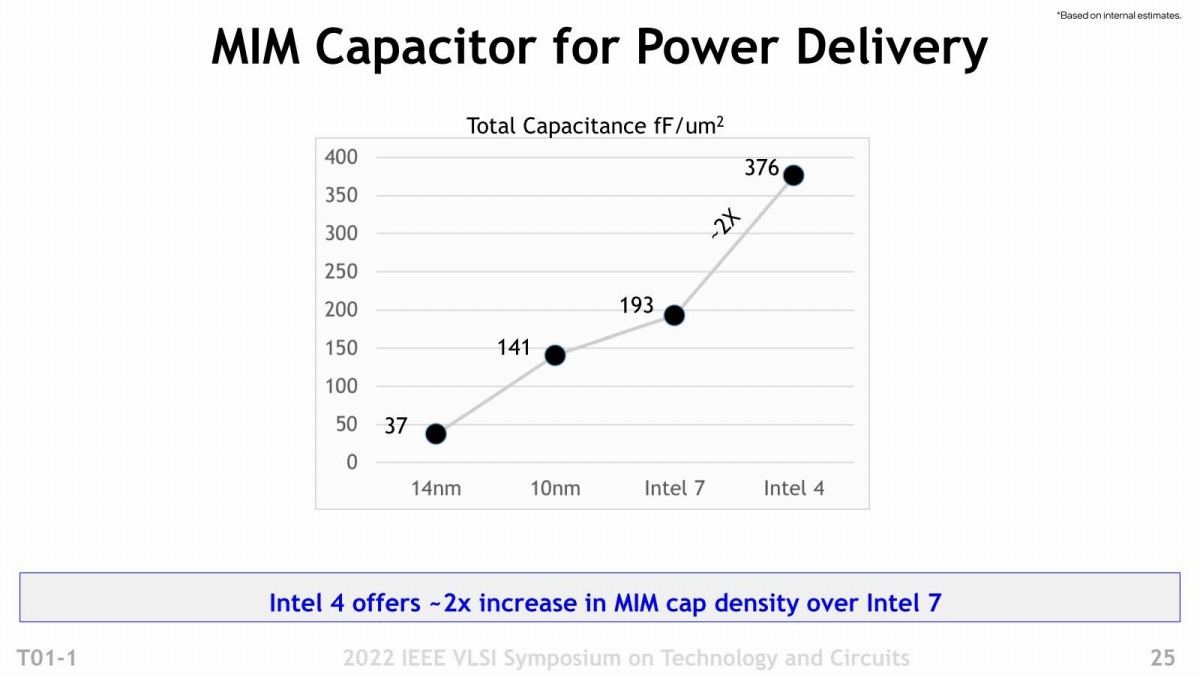
Photo14: MIM Capacitorは以前から搭載されていたがIntel 10nmでSuper MIM Capacitorを搭載。その後Intel 7で若干容量が増えたが、これがさらに増えた事になる。

さて、このIntel 4を使う最初の製品がMeteor Lakeである。Compute・I/O・Graphics・SoC(≒Chipset)の4 Die構成になるものが、このうちのどこまでがIntel 4を使うかは今のところ明示されていない。ただ少なくともCompute DieとGraphics Dieは確実にIntel 4だろう。問題は、「ではそのIntel 4のYieldはどんな状況?」という、恐らく一番聞きたい質問に対する答えが"Meteor Lake with Intel 4 and 3D Foveros packaging technology is up and running"と、まるで答えになってないことだ。
-
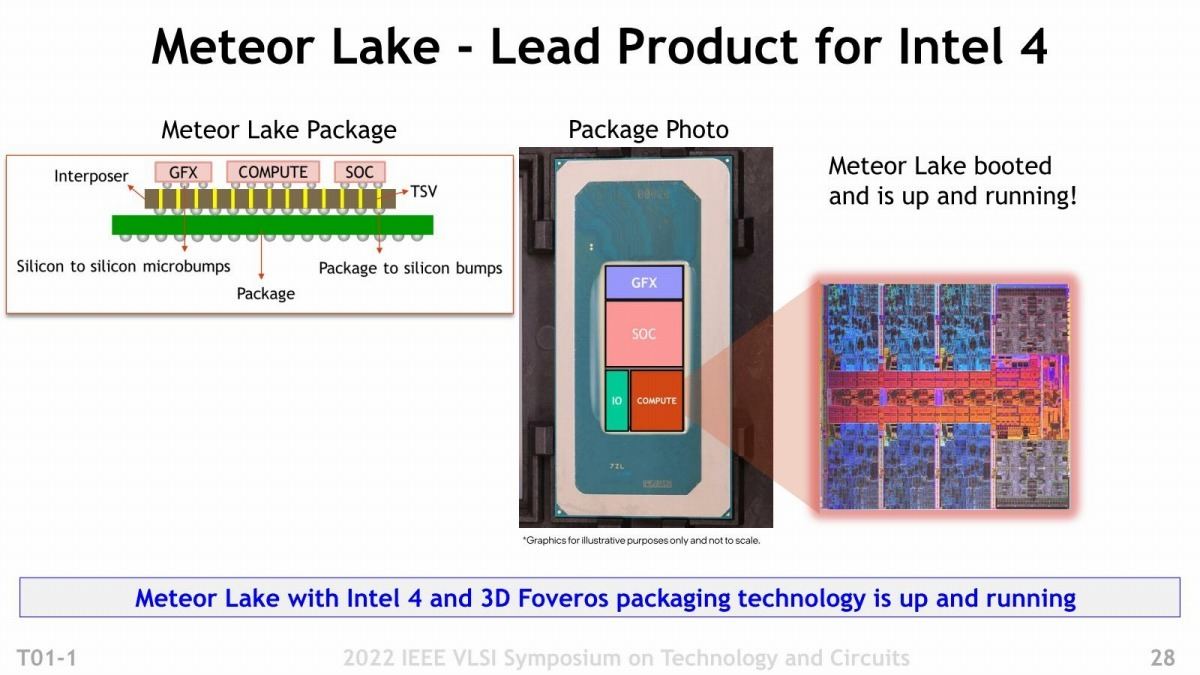
Photo15: Chiplet構成という意味でも、Foverosを使うという意味でも第2世代(第1世代はLakefieldである)になる訳だが、さて。

冒頭、今回Intelは12本の論文を発表したとしているが、うち5本でIntel 4が関係している。具体的には今回ご紹介したT01-1(Intel 4 CMOS Technology Featuring Advanced FinFET Transistors optimized for High Density and High Performance Computing)以外に
- C08-1 An 8-core RISC-V Processor with Compute near Last Level Cache in Intel 4 CMOS
- C13-3 A 90.9kS/s, 0.7nJ/conversion Hybrid Temperature Sensor in 4nm-class CMOS
- C16-1 A 7Gbps SCA-Resistant Multiplicative-Masked AES Engine in Intel 4 CMOS
- C24-1 Energy-Efficient High Bandwidth 6T SRAM Design on Intel 4 CMOS Technology
が挙げられている。ただどの論文も似たような感じで、例えばC08-1のRISC-Vプロセッサ+CNC(Compute Near last level Cache)だと"Intel 4 CMOS test chip boots Linux and performs CNC with RISC-V extension"だし、C16-1のAESエンジンの実装では"Intel 4 prototype demonstrates:1.8x and 50% improvements in area and performance overheads compared to AM AES"といった具合に「動けばちゃんと良い結果が出てくる」事はアピールしているのだが、Yieldについて何も言っていないあたりが非常に危うさを感じる。
ちなみに今年2月のInvestor Meetingの段階ではMeteor Lakeは2023年に投入(今年はRaptor Lakeのみ)という話となっているので、Intel 4の出来栄えがどうか? というのはあと半年しないと判らないことになる。ただIntel 7を利用したAlder Lakeが昨年から出荷されているのに、同じIntel 7を利用したSapphire Rapidsがアナウンスはともかく現実問題として製品出荷されていないあたり、Intel 4が問題なく製造可能になっているかどうか、ちょっと心配になるところである。









{kind=link}