
AMDは11月9日から19日に掛けてオンラインで開催されるSC20にあわせ、CDNAの第1世代を実装したRadeon Instinct MI100を発表した。これに関し事前説明が行われたので、この内容を基にご紹介したい(Photo00,00-2)。
-

Photo00

-

Photo00-2

Radeon InstinctはAMDのGPGPU向け製品である。これまではGPU向けと同じダイを使いながら製品を作り分けを行っていたが、そうした共通の製品は2018年11月に発表されたGCNベースのRadeon Instinct MI50/60が最後となった。というのは、Gaming GPUとHPC向けのGPGPUでは求められる要素が全く異なる(GamingにはFP64のサポートは不要であり、逆にHPC向けはTexture Unitとかがそもそも要らない)からで、そこで従来のGCNがGaming向けのRDNAとComputing向けのCDNAに分化するという話は今年3月に明らかされていた。このCDNAの簡単なロードマップも公開されていたが、このCDNAに基づく最初の製品がRadeon Instinct MI100として実装された形だ。
さてそのRadeon Instinct MI100であるが、基本的なコンセプトはExascaleに対応できる性能である(Photo01)。AMDは2019年5月に1.5 ExaflopsのFrontier、更に今年3月には2 Exaflops以上のEl Capitanを受注しており、これをEPYC+Radeon Instinctで実現することになっている。このためには、計算効率がより優れたGPGPUコアに載せ替える必要がある。このためには性能が対数的に上がる必要があるが、これを実現したのがこのRadeon Instinct MI100だというのがAMDの主張である。具体的には、1枚のGPUでFP64で10TFlopsを超え、FP32ではRadeon Instinct MI50比で3倍以上の性能、更に性能価格比でNVIDIA A100の1.8~2.1倍優れている、とする(Photo03)。このFP64で10TFlopsというのは、2000年11月のTop 500で1位を取ったASCI Whiteとほぼ同じ性能である、としている(Photo04)。
-
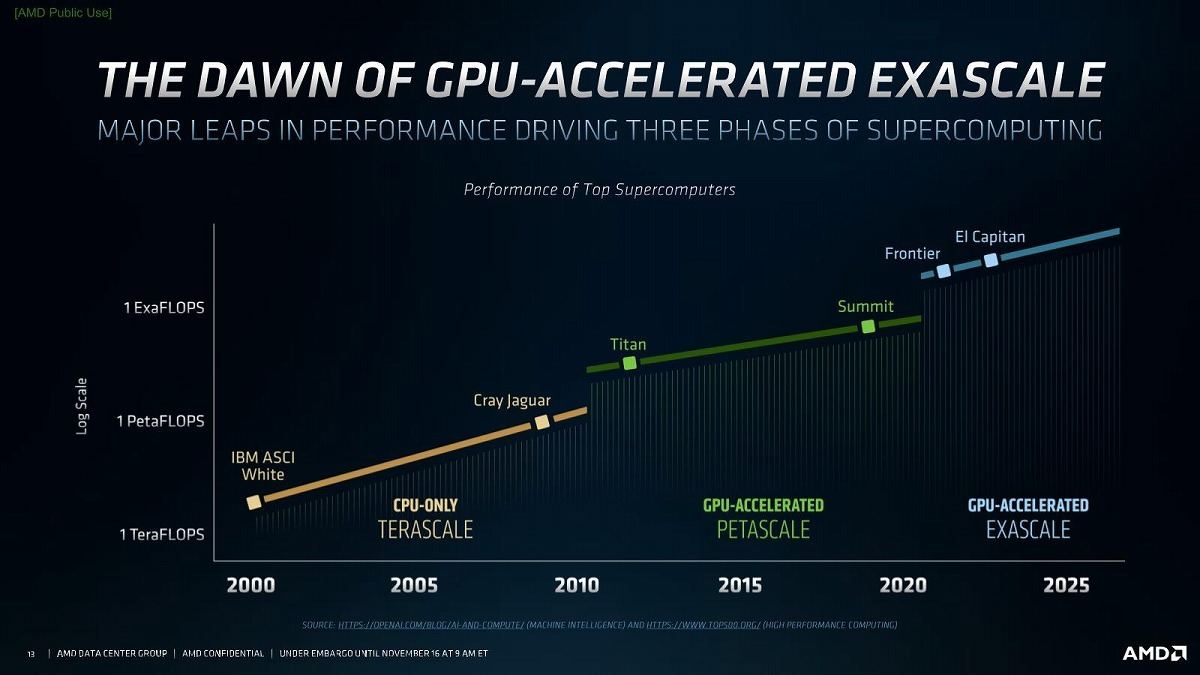
Photo01: 縦軸は対数な事に注意。

-
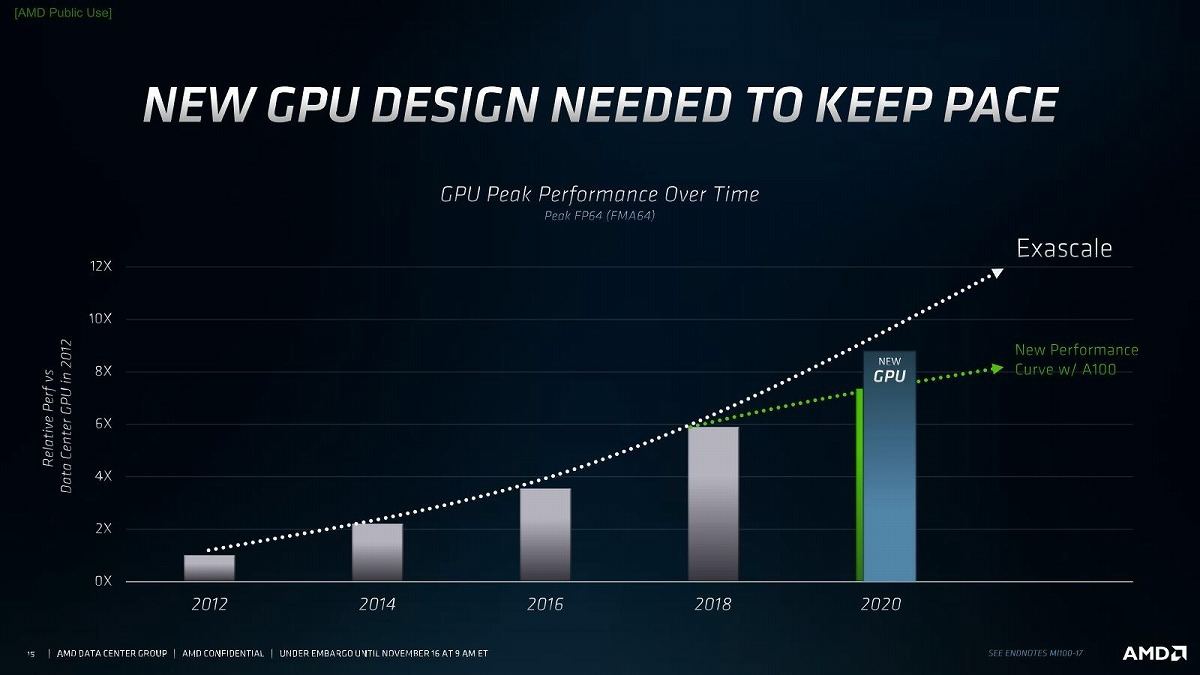
Photo02: NVIDIAのA100があまり性能向上がなく、なので直線的になっているとAMDは主張する。まぁこの世代はそうだが、だからといって今後もそうなるとは限らない気がするのだが。

-

Photo03: こういう書き方をするのは、要するに絶対性能では大きく変わらないから、という話でもある。

-

Photo04: ASCI WhiteはPOWER 3をベースとしたシステム。理論性能は12.28TFlopsながら、実効性能はチューニングが進んでも7.304TFlopsほど。ただそれでも2001年11月まではTop 500の1位の座を死守した。ちなみにお値段は9300万ドルほどである。

そのコアであるが、従来比2倍のコア密度、4倍のGPU-to-CPU Communication、1.2倍のバス帯域といった数字が躍る(Photo05)。数字を並べると
- Compute Unit数: 120
- Stream Processor数: 7680
- Memory: ECC2付HBM2Eメモリ×4 容量32GB、メモリバス幅最大1.23TB/sec
- Host I/F: PCIe Gen4 x16
- GPU I/F: Gen2 Infinity Fabric
とされており、性能値としては
- FP64性能: 11.5TFlops
- FP32性能: 23.1TFlops
- FP32 Matrix性能: 46.1TFlops
- FP16/FP16 Matrix性能: 184.6TFlops
- Int4/Int8性能: 184.6TOPS
- BFloat16性能: 92.3TFlops(性能はいずれもピーク値)。
とされる。直接的な対抗馬であるNVIDIA A100の性能は
- FP64性能: 9.7TFlops
- FP32性能: 19.5TFlops
- FP16性能: 78TFlops
- BFloat16性能: 39TFlops
とされており、Radeon Instinct MI100はそれぞれ18%~137%ほど上回っている計算になる。もっともNVIDIA A100は疎行列演算の場合の性能を向上させるスパース性機能と呼ばれているものがTensor Coreにあり、これを利用すると倍に性能が上がるという話になっており、これにあたるものがRadeon Instinct MI100の方に実装されているかどうかは不明である(言及がない)。逆にRadeon Instinct MI100にはMatrix Core Technologyと呼ばれるもの(資料を読む限りでは、混合精度の演算に対応した仕組み)が新たに導入され、これを利用すると例えばFP32は倍の性能になるとしている。
-

Photo05: 今回シェーダ(というかAMDの用語で言う所のStream Processor)の内部構造などはまだ不明なままである。

ちなみにAMDは今回、コアの動作周波数を公開していない。ただ11.5TFlopsという性能から、凡そRadeon Instinct MI100の動作周波数はピークが1.5GHzほどと推定される。またダイ写真はちょっと解像度が荒い(Photo06)ものだけが提供されており、なので精度はあまり高くないが、HBM2メモリの寸法からダイサイズはおよそ24.0mm×31.8mmで763.2平方mmと推定される。ちょっと驚異的なダイサイズだが、実際Vega 7nmのダイと比較すると、縦方向も明らかにデカいし、横幅は言うに及ばずである。16nm世代ならNVIDIAのV100(815平方mm)という例があるが、7nmでここまで巨大なダイはこれが最初であろう。ちなみにダイ、映像効果付きかつ斜めのアングルの写真は高解像度のものが提供されている(Photo07)。
-

Photo06: 詳細が明らかになるのを嫌がったためか、妙に小さい解像度のものしか公開されていない。

-

Photo07: こちらだと、個々のCompute Unitの詳細が見て取れる。ただこれを見る限りはCompute Unitは128個あり、うち120個を有効にしているように見える。

さて、White Paperによれば内部構造はこんな感じである(Photo08)。要であるXCUの内部構造はこんな感じ(Photo09)。大きな違いはWaveの数だろうか。GCNは64Wave単位、RDNAは32Wave単位での管理だったのが、CDNAでは10Wave単位と大幅に粒度が減った。SIMDは512bit長で、FP64で×8、FP32で×16、FP16で×32の演算が可能なほか、SFU(Special Function Unit)が4つ搭載される。またMatrix UnitがDP×8などと並列の扱いであり、つまりMatrix演算の場合はSIMD全体を利用する形で演算が行われるようだ。このMatrix演算での性能を示したのがこちらのテーブル(Photo10)で、Matrix演算を利用することで2~4倍の演算スループットが実現する、としている。
-

Photo08: 各々16個づつのXCUを搭載するブロックが8つあり、中央にACEやDMAエンジンなどが搭載される。Multimedia Engineまで搭載されているというのはちょっと意外。

-
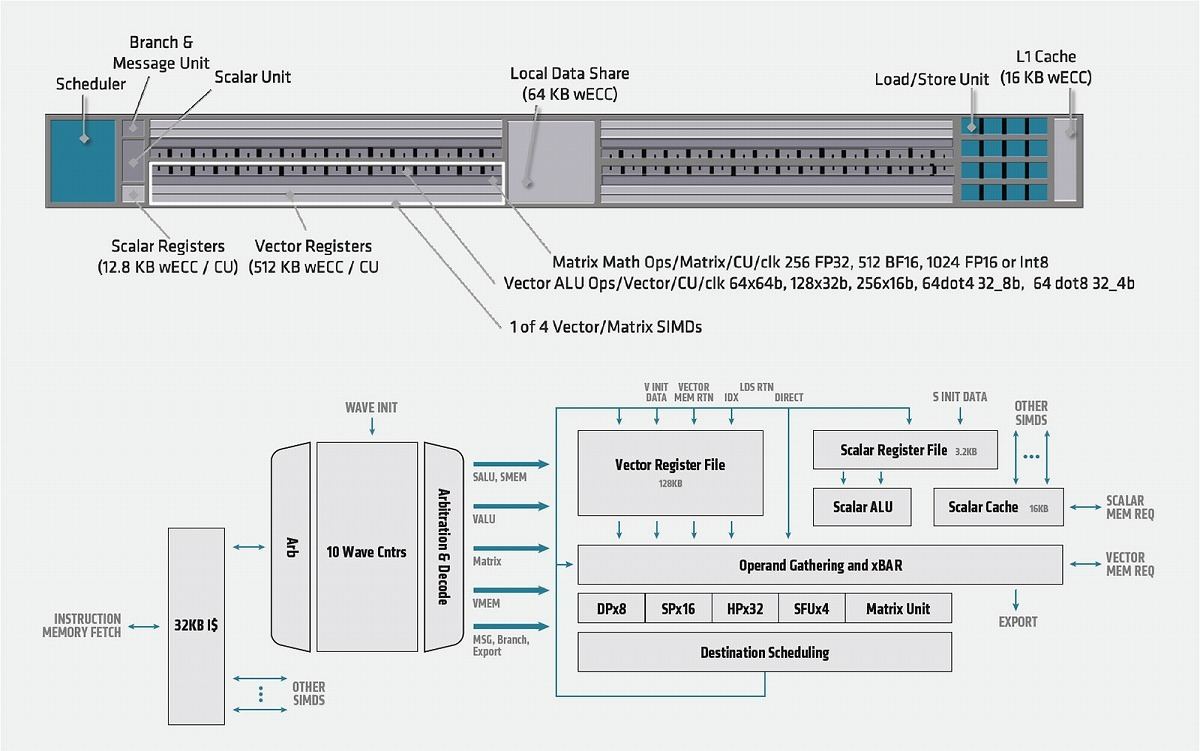
Photo09: SFUの数は半減。Scalar Unitの数は同じ。Matrix Unitは現時点でも今一つ、どう動くのかが良くわからない。

-
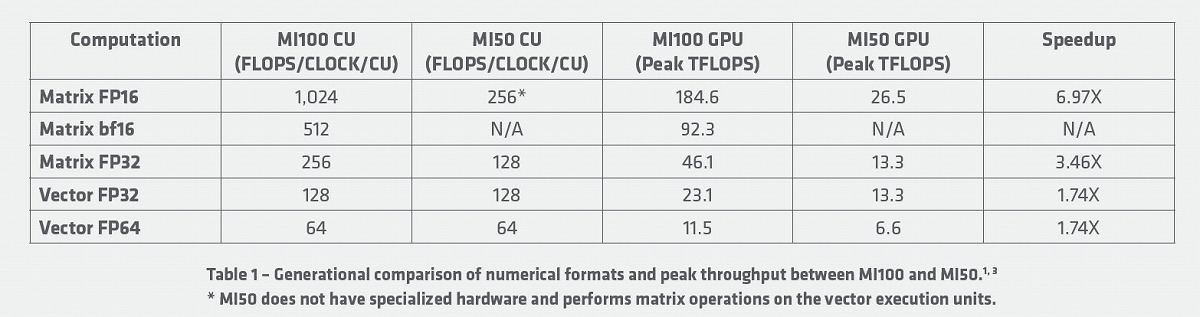
Photo10: なんとなくだが、このあたりはNVIDIA A100のTensor Coreを利用した演算に近いものがあると思う。ただA100はTensor Coreを別に用意しているのに対し、Radeon Instinct MI100では同一のSIMDエンジンの使い方を変えている格好だが。

次にメモリだが、HBM2を利用することはRadeon Instinct MI50/60と同じである。ただRadeon Instinct MI50/60はレーンあたり1GbpsのHBM2なのに対し、Radeon Instinct MI100では転送速度を1.2Gbpsに引き上げたHBM2Eが採用される。HBM2Eは、Samsungが今年後半から量産に入る事を2月に発表、SK Hynixも量産開始を7月に発表しており、入手性そのものは悪くないだろう。とりあえず妥当な選択と言える。
Interconnectであるが、Host I/Fは引き続きPCI Express Gen4 x16のままである。また4つのRadeon Instinct MI100をInfinity Fabricで接続できるという話も、Radeon Insinct MI60などと同じである(Photo11,12)。異なるのは帯域で、Radeon Insinct MI50/60は信号速度が50GT/sec、トータルでの帯域は100GB/secだったのに対し、Radeon Insinct MI100ではピークで276GB/secまで帯域が引き上げられている。ということは転送速度は138GT/secに達する計算になるが、どうやってこれが実現されているかは今のところ未公開である。
-

Photo11: 4枚のRadeon Instinctの上にブリッジを搭載するのも同じく。

-

Photo12: 1つのEPYCには4枚までRadeon Instinctが接続可能なので、2 Socket EPYCサーバだとこんな具合に8枚まで装着できる。

なお以前のロードマップによれば、第3世代のRadeon InstinctではPCIeを抜いてInfinity FabricのみでHost(EPYC)と接続可能という話だったが、これはおそらく次のCDNA製品まで先送りで、今回は第2世代と同じ接続方法となった。
さてこのRadeon Instinct MI100にあわせてROCm 4.0もリリースされることになった。実はこれに先立ちORNLではいくつかのアプリケーションが移植され、いずれも順調な性能を示している(Photo13)。そして間もなくROCm 4.0もリリースされる見込み(この原稿執筆時点ではまだRelease v3.9.0と、v3.9.1Patchが出ているだけ)である(Photo14)。Photo14だとちょっと見えにくいので拡大したのがこちら(Photo15)であるが、AI向け及びHPC向けのライブラリやフレームワークが完全に用意されることになる。このROCmへの移植作業、中にはQUDA(21日必要)というものもあるが、1日(SPECFEM3D)とか半日(HACC/CHOLLA)などのものもあり、そう難しくないとされる。既にORNLと米ピッツバーグ大、豪PAWSEIスーパーコンピューティングセンターの3箇所は、ROCmを利用してシステムの構築をスタートしているとの事だった(Photo17)。
-

Photo13: 比較対象はNVIDIA V100だったりRadeon Instinct MI60だったりと色々である。このあたり、もう少しするとNVIDIA A100との実アプリケーション性能比較も出てくるかもしれない。

-

Photo14: 一応ROCm 3.0の段階で主要な機能は全て提供されているが、幾つかのものはまだβとかEarly imprementation段階でしかない。これが全てProduction Qualityになるのが4.0とされる。

-

Photo15: ちなみに4.0のReleaseは一応年内の予定らしい。もう3.9.1あたりまで行っているから、そう遠い事ではないだろう。

-

Photo16: ちなみにCHOLLAはCUDAからの移植だったとの事。

-

Photo17: いずれもEPYC+Radeon Instinct MI100ベースのシステムを導入予定なので、まぁROCmでアプリケーションを構築するしかないのだが。

なおこのRadeon Instinct MI100をサポートするプラットフォームはHPC、Dell、SuperMicro、GIGABYTEから提供予定との事である(Photo18)。
-

Photo18: この期に及んでも価格が出てこないのは、恐らく価格はこの4社に問い合わせを行えという事と思われる。ただ、NVIDIA A100と比較して1.8~2.1倍価格性能比が良好とか言いつつ、肝心の価格が出てこないのはどうかと思う(まぁNVIDIAも単体価格は未公表だが)。









