2019年8月に米国にて開催された最先端のLSIチップに関するトップレベルの学会「Hot Chips 31」での多数あった発表の中でもっとも度肝を抜かれたのはCerebrasの「Wafer Scale Deep Learning」という発表である。
発表を行ったのはCerebrasの創立者の1人でチーフハードウェアアーキテクトを務めるSean Lie氏である。
-

Cerebrasのウェハスケールディープラーニングを発表したSean Lie氏

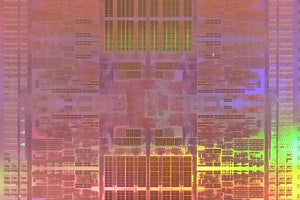
次の写真がウェハスケールエンジン(WSE)で、右下のチップは比較のために置いたNVIDIAのV100 GPUである。何しろ、46,225mm2で215mm角となると巨大で、チップと呼ぶのも憚られる。V100 GPUは815平方mmであるので、CerebrasのWSEは56.7倍のシリコン面積である。また、トランジスタ数では、Cerebrasは1.2Tトランジスタに対して、V100は21.1Bトランジスタであり、こちらも56.9倍である。
なお、V100は12nmプロセスで、Cerberasのウェハは16nmプロセスであるので、V100の方が微細なプロセスを使っているが、面積比率とトランジスタ数比率は似通った値になった。
CerebrasのWSEは、次の写真に見られるように、12×7のタイルに分かれている。ウェハに回路を形成する露光装置は一度に大きな面積を露光できないので、4個の黒丸で囲まれた領域を1回の露光で処理していると見られる。ただし、角のタイルは少し欠けているので、使ってないのかもしれない。
-

46,225mm2の巨大シリコンのCerebrasのウェハスケールエンジン(WSE)。右下は最大のGPUであるNVIDIAのV100 (出典:このレポートのすべての図は、Hot Chips 31におけるCerebrasのSean Lie氏の発表スライドのコピーである)

シリコンの諸元を纏めたのが次の図で、シリコン面積は46,225mm2、トランジスタ数は1.2Ttr、AI処理に最適化したコアを400,000個搭載する。各コアは45kBのメモリを持ち、WSE全体では18GBのメモリを持っている。このメモリの総バンド幅は9PB/sである。
なお、CerebrasはAIコアのクロックなどは発表していない。
-

CerebrasのWSEの諸元。46,225mm2という巨大サイズで400,000コアを集積する

ディープラーニングに使われるモデルはドンドン複雑になっており、多くの演算コアとメモリが必要になってきている。このため、1チップに入らない場合は、例えばNVIDIAのV100 GPUを複数使用することになる。GPUの数が16個までであればDGX-2を使えば、16個のGPUをNVLINKで接続したものを使うことができるが、それを超えると、複数のDGX-2をInfiniBandで接続することになる。
しかし、InfiniBandはケーブル遅延もあり、チップ内の通信に比べると大幅に遅い。このため、ウェハ内の通信で済むWSEの方が高い性能が得られる。もちろん、WSEはV100の60倍程度の大きさであるので、おおざっぱにDGX-2が4台程度の規模と思われ、それ以上に大きなモデルであればCerebrasのWSEでも複数台で分割処理する必要が出てくる。
CerebrasのAIコアは次の図のようになっている。基本的に、各コアは独立したプロセサであり、MIMDのアレイになっている。そして、通常のコントロールに必要な命令を実行できる。それに加えて最適化されたテンソル処理命令をサポートしている。
そして、処理はデータフロー的に行われる。
-

CerebrasのWSEのコアは独立の命令を実行でき、全体としてはMIMDとなる。一般的な命令とML拡張命令を持ち、最適化されたテンソル演算を実行できるようになっている

ニューラルネットは当初、密な接続であったとしてもReLUのような非線形演算を行うと、係数がゼロになるものが出てきて右下の図のように疎な接続になる。Cerebrasのエンジンは、ゼロの枝があるとそれを取り除いてしまう。そして、枝が無くなり不要になった処理をスキップし、無駄な演算を行わないようになっている。
-

Cerebrasの計算エンジンはデータフロー的に動作し、入力データがゼロで演算が必要ない場合などは処理をスキップする

メモリとAIエンジンが別になっている場合は、メモリに格納されている重みなどを読むにはチップをまたいでメモリにアクセスする必要がある。
しかし、CerebrasのWSEではメモリは論理と同様に分散されており、すべて同一ウェハ内にあるので、高速でアクセスすることができる。
-

CerebrasのWSEではメモリはコア領域全体に分散しているので、ディープラーニングに適した構造になっている

そして、各コアは2次元のメッシュで接続されている。短い配線での接続であるので、通信プロトコルのようなものは不要で、ハードウェアだけで通信を行えるので、高速で通信ができる。
-

コア間は短い配線で接続されているので、通信時間は短い。そして、WSE全体では100Pbit/sと通信速度も速い2Dメッシュネットワークになっており、効率的にローカル通信を行うことができる

このように、CerebrasのWSEは
- より多くのAI処理に最適化したコアを持ち、
- より高速のメモリを持ちレーテンシが短く、
- バンド幅の大きいネットワークを持つことにより
他のAIエンジンに比べて圧倒的に高い性能を実現している。