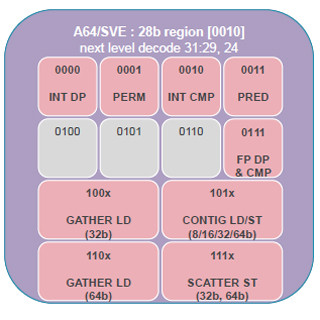
一方、このアーキテクチャでは、プログラマやコンパイラは、ベクトル化のやり方を変える必要が出てくる。また、ベクトル長非依存といっても、関数呼び出しなどでは、スタックに引数を入れて渡す必要があり、スタックに必要なメモリはベクトル長に依存し、ベクトル長が変わると意図しない副作用が出る可能性がある。また、プログラムが本当に128bitの1-16倍の長さのレジスタで正しく動くかを確認するのは手間が掛かるという問題がある。これに関しては、用途別に推奨するレジスタ長の範囲を決めて手間を減らすことも考えているという。

|
|
ベクトル長非依存は、将来的に長いベクトルを使用する命令の追加がなく、プログラムを変更する必要もないというメリットがあるが、本当にベクトル長非依存になっていることを確認するには手間が掛かるし、意図しない副作用が出ることもあり得るという問題もある |
SVEではベクトルレジスタにパックされたそれぞれのデータにプレディケートレジスタを使って、命令の実行の可否を指定することが出来るようになっている。次の図の最初の例は256bit長のレジスタに64bitデータを4個詰め込み、4個のデータともプレディケートは1で命令を実行するという指定になっている。
次の例は、32bitのデータを8個詰め込み、プレディケートはすべて1というものである。最後は、32bitデータを8個詰め込み、プレディケートは0、1、0、1と1つ置きに命令を実行する指定になっているという例である。

|
|
エレメントごとにプレディケートがある。プレディケートの値が1のエレメントはアクティブで、演算などの対象になる。プレディケートが0のエレメントはインアクティブで演算などの対象にならない |
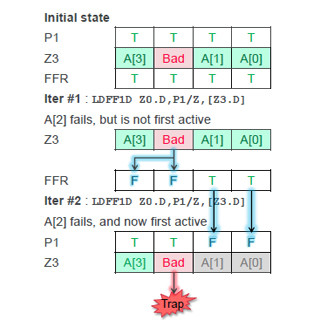
次の図の右側の表のように、SVEの場合はコンディションコードの意味が変わり、例えばZ=1の場合はNoneで、アクティブなエレメントの中にはTRUEのものが無い場合は条件成立、Z=0の場合は、アクティブなエレメントの中に1つでもTRUEのものがあれば条件成立、C=1の場合は、ベクトルの中の最後のアクティブなエレメントがTRUEの場合は条件成立となる。このようにNZCVのコンディションレジスタの値は、どのエレメントの値を見るのかを指定している。
そして、そのエレメントのプレディケートが1(TRUE)か0(FALSE)で成立、不成立が決められる。この場合のプレディケートの値は比較命令などでセットされる。

|
|
SVEでは条件コードは、どのエレメントをチェックするかを指定するのに使われ、条件の成立、不成立はプレディケートの1/0で決まる |
次の図は、y[i]=A*x[i]+y[i]を計算するSAXPYのコードで、左はスカラのコードで、右はSVEを使ったコードである。SVEコードでは、X3レジスタにベクトル長を入れ、X4レジスタをどこまで計算したかのカウンタに使っている。このX4レジスタは、最初は0を入れて置く。
ld1rw命令は、Aの値をZ0レジスタの全要素にブロードキャストする。そして、.loopの次の2つのld1w命令でx[i]をZ1レジスタ、y[i]をZ2レジスタにロードする。その次のfm1a命令でA*[xi]をy[i]に足し込む。そして、X4レジスタにベクタ長/32を足し込み、whilelt命令でX4レジスタとX3レジスタの値を比較し、まだ、終わりでなければb.first命令で.loopにジャンプして処理を繰り返している。
つまり、長いベクトルをハードウェアのレジスタに格納できる長さずつ計算し、全エレメントを計算するまでループを回るというプログラムになっている。そして、incw命令はレジスタのベクトル長を自動的に考慮してくれるので、レジスタの長さが幾らであっても同じプログラムで計算ができる。また、whilelt命令は、ループ回数がベクトルレジスタ長の整数倍でなくとも、余った分のエレメントはプレディケートでinactiveにして計算されないようにしてくれる。これがベクトル長非依存の仕掛けである。

|
|
左はSVE命令を使わないSAXPYのアセンブラコードで、右はSVEを使うSAXPYコードである。SVE版では1つのベクトルレジスタに含まれる全要素が並列に計算されるので、その分、性能が上がる。しかし、プログラムとしてはレジスタのベクトル長を意識したコードとする必要はない |
次の図はNEONとの性能比較で、7つのプログラムで比較を行っている。棒グラフは同じ128bit長のレジスタを使い、NEONに比べてベクトル化できた部分がどれだけ増えたかを示している。この7つのプログラムでは45%-70%ベクトル化できるところが増えている。
3本の折れ線グラフはSVEのレジスタ長を128bit、256bit、512bitとした場合の性能をNEONと比較したもので、例えば、512bitとした場合は、2倍-7倍の性能が得られている。

|
|
NEONとの性能比較。棒グラフはベクトル化比率の増加分を示す。折れ線グラフはSVEのレジスタ長を変えて、NEONを1.0とした場合の性能向上を示す |
NEONは単純なSIMDであるので、次の図の右側に書いたCコードの?表現(選択表現)が使われている部分はベクトル化できない。しかし、SVEではプレディケートを使って値の選択を行うことが出来るので、?表現が使われている部分もベクトル化ができる。
このasc_coral_haccmkの例では、ベクトル化が出来ない場合は、この部分の実行時間が72%を占めており、SVEを使ってベクトル化することにより大きな性能向上が得られている。

|
|
SVEはプレディケートを持っているので、C言語の?表現が使われている部分もベクトル化できる。そのため、ベクトル化比率が上がっており,この部分の実行時間が大きいasc_coral_haccmkの性能向上が大きくなっている |
ニューラルネットの処理では、学習の場合はある程度の精度が必要である。この場合は32bitの浮動小数点数の行列乗算SGEMMを使えば良い。この場合、SVEのmultiply by indexed element命令を使えば、性能を上げることができる。
一方、推論ではそれほどの精度は必要ないので、16bitの半精度のHGEMMを使えば、SGEMMのほぼ2倍のスループットが得られる。また、SVEの8bitのdot product命令を使えば32bit整数での計算と比べて約4倍のスループットが得られる。
右のグラフはAlexnetでは、行列乗算のGEMMの計算時間が80%を越えていることを示している。

|
|
ニューラルネットの計算は行列乗算のGEMMの計算時間が長い。SVEを使うことで、この計算時間を短縮できる。また、推論の場合は、16bitの半精度や8bitの整数でも良い場合があり、これらを使えば、さらにSVEのスループットを高められる |
ARMでは、HPC用のC/C++コンパイラに加えてSVEをサポートしたコンパイラを提供している。また、SVEを使うライブラリ、SVEの命令エミュレータ、OpenMPも提供している。さらに、ベータ版であるがコードアドバイザも提供を始めている。ということで、SVEを使ったプログラムを開発できるツールが揃いつつある。

|
|
ARMは、SVEを使うC/C++コンパイラ。ライブラリ、OpenMP、命令エミュレータなどを提供している。また、ベータ版であるがコードアドバイザの提供を始めており、SVEを使う環境が整いつつある |