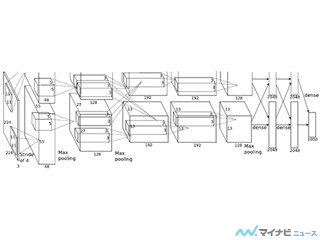
TPUのブロックダイアグラムは、次の図のようになっている。右側の中央が256×256(64K個)の積和演算器からなる行列乗算ユニットであり、上辺に重みを記憶するDDR3 DRAMとDRAMインタフェースがあり、読み出された重みは重みFIFOを介して行列乗算ユニットに供給される。
中央付近にあるユニファイドバッファは24MiBのローカルメモリで、ここに入力をいれて重みと掛け合わせて、アキュムレータで総和を求める。
アキュムレータに格納された結果はユニファイドバッファに書き込まれ、必要に応じてPCI Express経由でホストCPUのメモリに書き戻される。

|
|
TPUのブロックダイアグラム。右側の中央が256×256(64K個)の積和演算器からなる行列乗算ユニット |
行列乗算ユニットは左上の角から計算が進んで行くシストリックアレイになっており、そのためのセットアップ回路が付いている。乗算結果の累積は32ビットで行われ、アキュムレータは4K×256個存在する。この値は、後述のルーフラインモデルで、フルの演算性能を発揮するには1350以上の演算強度が必要であるので、これを切り上げて2Kとし、さらにダブルバッファで使うことを考えて4Kエントリとなっているという。

|
|
左上から計算を行っていくシストリックアレイ方式の乗算累積ユニット |
次の図はTPUダイのフロアプランである。24MiBのユニファイドバッファが29%、行列乗算ユニットが24%を占め、この2つで半分を超える。そして、4MiBのアキュムレータの6%を加えると約6割の面積が主要データパスで占められている。一方、コントロールは2%で、CPUなどと比べると簡素なコントロールになっている。

|
|
TPUのフロアプラン。24MiBのユニファイドバッファが29%、行列乗算ユニットが24%を占め、この2つで半分を超える |
ホストCPUからの命令はCISC命令で、典型的な命令の実行には10~20サイクルを必要とする。主要な命令としては、
- Read Host Memory
- Read Weights
- Matrix Multiply/Convolute
- Activate
- Write Host Memory
がある。ActivateはNormalize/Poolユニットを使って、ReLUやSigmoidなどの非線形関数を適用したり、プーリングを適用したりする命令である。
この論文で性能の比較を行っているのは、次の表の3つのシステムである。CPUもGPUも、現在ではより新しい製品が出ているが、TPUが完成した2015年の同世代の製品同士で比較を行っている。
TPUのチップサイズは書かれていないが、Haswellの半分より小さいと書かれており、最大で331mm2で、まあ、300mm2程度ではないかと思われる。
この表の左半分は、1チップあたりの比較で、8ビット整数演算ではTPUはXeonの35.4倍の性能となっている。また、K80は8ビット整数演算を持っていないので、32ビット浮動小数点演算との比較であるが、TPUは32.9倍のピーク演算性能となっている。
実測の消費電力では、ビジー状態で、CPUシステムは455W、GPUシステムは991W、TPUシステムは384Wとなっている。

|
|
CPUシステムはXeon E5-2699 v3 2ソケット。GPUシステムはNVIDIAの2チップ搭載のK80を4台。TPUは4個搭載のシステムである |
なお、NVIDIAのMaxwell GPUは、この時期に存在しており、これを使えばより高い性能が得られるという指摘があり得るが、Maxwell GPUはサーバ用のECC機能をもった製品が無くGoogleのデータセンターには採用できないので、この比較には含めていない。