スキャン精度はかなり高いが英数字の読み取りにムラがある
実際にスキャンしてみて驚くのは日本語OCR機能の精度が高いことだ。実際、筆者が依然書いた原稿をプリントアウトしたものを「Office Lens」の「ドキュメント」モードでスキャンし、その後「Word」で保存してみたところ、1ページの原稿内にある文字数653字に対して誤認識があったのは3字。また、名刺の読み取りも漢字やかな部分の読み取り間違いはほとんどない。
ただし漢字とかな、アルファベットが混ざった原稿をスキャンすると、漢字・かなの認識率は高いものの、英数字では「0」と「o」の区別がつかない、アルファベットではなく漢字として認識してしまう傾向がある。
また、書類や活字ならすんなり認識できるが、手書き文字の場合はドキュメントモードでスキャンしても文字として認識されず、写真として扱われてしまう。

|

|
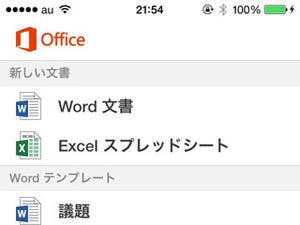
Office Lens」でスキャンした原稿を開くとテキスト化されている。ただし、英数字の認識に多少まちがいがある |
手書き文字は写真として認識される |