まとめと考察
ということでちょっと日があいてしまったが、こちらの特集で予告したHaswell検証レポートをお届けした。色々と内部への理解が深まった気がする。
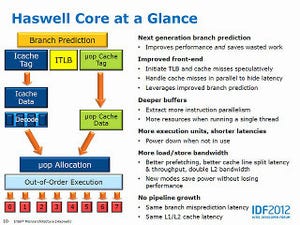
Haswellでは、見かけよりも大きくFront Endにも手が入っていた事を確認できたのは非常に有意義だった。冒頭のDecode Bandwidthの一連のグラフを見る限り、Decoded μOp CacheはサイズこそIvy Bridgeと変わらないものの、内部の管理方法に大きく手が入っており、従来よりもより効率よくプログラムを格納できるようになっているのが判る。なんというか、μOpを可逆圧縮の形で格納できるように改変した、というのが一番正確な言い方かもしれない。グラフ3とか4で、8MBあたりまでBandwidthがフラットなのがこれを明確に示していると言える。
なんでこんな事をインプリメントしたかといえば、Front EndのBandwidthを変えずにBack Endを大幅に拡張したからである。Back Endを拡張するというのは同時に多くの命令を処理できるようになるという意味だが、これに有効に仕事をさせるには当然Front Endも拡張しないといけない。入り口が無茶苦茶狭い店舗で内部にレジを100台置いても、殆どのレジが遊んでしまうようなものだからだ。ただそうでなくても現在のx86プロセッサはDecode部が消費電力や回路の複雑さのボトルネック部であり、今のSimple×3+Complex×1でも相当大変なので、そうそうこれを拡張ができない。そこでDecoded μOp Cacheを見かけよりも多く命令を保持できるように改変したことで、入り口は狭いままでも店舗内部に回遊しているお客さん数を増やすことで、どのレジも仕事をするように変更したといえば良いのかもしれない。
しかしながら、当然これは従来と最適化の方法が全く異なる事になる。Haswellではまず、Decoded μOp Cacheにどうやって多くの命令を保持できるようにするかがポイントになり、次はそこからどうやって命令を実行ユニットにDispatchするかを考える事になる。ここで不明なのは、んではHaswellではどんな可逆圧縮技法でDecoded μOp Cacheに命令を詰め込んでいるかである。既にHaswellに対応したIntel 64 and IA-32 Architectures Optimization Reference Manualはリリースされており(I-TLBのところなどでリンクを示した、これである)、この2.2.2.2の"Decoded ICache"という節に、最適化を行なうためのルールが幾つか記されている。Decoded μOp Cacheは32setの構成で、1つのsetは8wayから構成され、1wayには6つのμOpが格納できるとされている。なので合計1500(正確には1536)のμOpを格納できるという訳だが、setとかwayとかの管理単位で判る通り、ベタにμOpが格納されているわけではない。つまり、ここに上手くμOpを格納できるようなプログラムの書き方をすると性能が上がりやすい(拡張されたBack Endをフルに生かしやすい)反面、Decoded μOp Cacheの利用効率の悪いプログラムの書き方だと、むしろ性能が落ちてしまう可能性もあるわけだ。その意味ではこちらの冒頭で書いた、
「・性能を上げるためには何らかの、これまでとは違った最適化が必要な可能性が高い。」
という筆者の推定は正しかったように思う。実際最後で示したChecksumとかSubstring Searchの結果を見ると、Haswellの性能の上がり方はアプリケーションの書き方次第という気がしてならない。
勿論Haswellの最適化はここだけではない。CacheやTLB周りも随分細かく手が入っている。ただこれらは個別に見てきたように、ある想定したアクセス方法だと高速化できるが、それを外すとぐっと性能が落ちる方向に作用するようだ。これは「どんなやり方で使ってもそこそこの性能」から「ある程度使い方を制限しても高速化に振る(なので、そこを外すとむしろ遅くなる)」という方向にチューニングを進めているように見える。
総じて言えば、Haswellは今後のIntelのx86プロセッサの更なる高性能化に向けて、従来と異なる方向に舵を切った最初の製品に見える。Decoded μOp Cacheもそうだが、キャッシュとかTLB類の使い方も、これまでとは違った最適化のルールが必要になるようだ。これは、単にHaswell世代に留まるものではなく、次のBroadwellは当然の事、その先のSkylake/Skymontまで見据えたものではないかという気がしてならない。
実はIntelは最新のIntel C++ 13.0で、既にこのHaswell向けの最適化を実装しているという話であった。なので、本当のところを言えば、幾つかのプログラムをこれで再コンパイルしてどの程度性能が改善するか確認したい所であるが、今回はそこまでやる時間はなかった。ただRMMAで見た限り、明らかにFront End周りというかDecoded μOp Cache周りの振る舞いがIvy Bridgeと異なるので、最適化方法が全く異なるのだろうというのは容易に想像がつく。逆に言えば、最適化の方向が全然違うアプリケーションであっても、Ivy Bridgeより「ちょっと遅い」程度で動かせるHaswellは、実は結構すごいプロセッサなのではないか、という言い方もできるかも知れない。
その意味では、Haswellは新世代のIntelのプロセッサの第一世代というと聞こえが良いが、要するに「踏み台」なのかもしれない。今後Haswellへの最適化を行なったアプリケーションが増えてくれば、ずっと性能が改善されてくる可能性があるが、それが実現するのは早くてもHaswellの次のBroadwell/Haswell-Refereshの時代であろう。Intelもそれが判っているからこそ、今は省電力をHaswellのメインとして前面に押し出しているのではないか、という事を強く感じたテスト結果であった。