


Markdown(マークダウン)記法をご存じだろうか。これは、文書を記述するための軽量マークアップ言語の一つだ。「#」や「-」といった記号を利用して、見出しやリストなどを指定して、綺麗に整形された文書を出力する。手軽に見栄えの良い文書が作成できるので人気がある。出力フォーマットも、HTML/EPUB/PDF/Word/PowerPoint形式と幅広い。そのためマニュアルや報告書、電子書籍の作成に活用する例も増えている。今回は、Pythonを利用して、Markdownで書いたテキストデータをPDF出力するプログラムを作ってみよう。
Markdown記法とは?
これまでにも、テキストファイルに書いた文書を見栄えの良いHTMLに変換できるツールやアプリはいろいろあった。特に、Webページをその場で編集できる「Wiki」界隈では、PukiWiki記法やMediaWiki記法など、そのアプリごとに独自の記法が使われてきた。
しかし、最近では、Webのコメント欄や、ブログなどの記事を投稿する場面で、手軽に見栄えの良いドキュメントを生成する目的で、Markdown記法が採用されることが多くなっている。その理由として、プログラマーがよく使うGitHubやBitbucket、Stack OverflowやQiitaなどのWebサービスが、コメント欄などにMarkdownを採用したことが大きい。それに伴って、様々なMarkdown対応ライブラリが公開されている。
それで、Markdownを使えば、手軽に文章をHTMLやPDFなどの形式に変換できるので、大きなメリットとなる。
-
GitHubなどで積極的にMarkdown記法が採用されている

Jupyter NotebookでMarkdownを練習しよう
また、本コラムではおなじみのJupyter NotebookもMarkdown記法に対応している。そこで、Jupyter Notebookを使って、Markdownの練習をしてみよう。Jupyter Notebookの実行方法については、本連載の15回目「最新Anacondaに入っている各種ツールを概観しよう」が参考になるだろう。
Jupyter Notebookを起動したら、適当に新規ノートブックを作成しよう。
そして、最初のセルをMarkdownに変更してみよう。画面上部のメニューから[Cell > Cell Type > Markdown]を選択しよう。
-
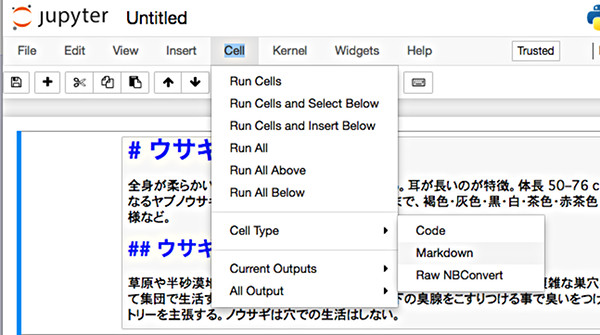
Cell TypeをMarkdownに設定する

すると、Markdownの編集中は、見出しを表す「#」などの記号が自動的に色がついたり太字になったりする。Markdownを記述した後に、実行ボタンを押すと、Markdown記法に基づいて、レンダリングが行われる。また、セルをダブルクリックすると、レンダリング結果から編集画面に戻る。
-

Markdownをレンダリングしたところ、下:編集中のところ-自動的に色がつく

よく使う記法には、「#」が見出し、「-」がリスト、「>」が引用などがある。また、「*xxx*」のように、アスタリスクで文字列を囲むと強調となり、「xxx」のようにバッククォートで囲むとプログラムやコードの一部であることを示すことができる。
Markdown記法について、ここでは詳しく紹介できないので、以下のリンク先を参考にしよう。
- Qiita > Markdown記法 チートシート --- https://qiita.com/Qiita/items/c686397e4a0f4f11683d
MarkdownをPDFに変換する手順を確認しよう
さて、Markdownに慣れたところで、Pythonを使って、MarkdownをPDFに変換する方法を確認してみよう。主要なMarkdownのライブラリは、テキストファイルをHTMLに変換するものがほとんどだ。そこで、最初にMarkdownをHTMLに変換し、その後、HTMLをPDFとして出力するという手順でプログラムを作ろう。
まずは、Markdownを扱うために、PyPiからmarkdownパッケージと、PDFを生成するためにpdfkitパッケージをインストールしよう。コマンドライン(Windowsなら、PowerShell。macOSならターミナル.app)を起動して、以下のコマンドを実行してパッケージをインストールしよう。
pip install markdown
pip install pdfkit
あるいは
pip3 install markdown
pip3 install pdfkit
モジュールをインストールしたら、Jupyter Notebookも再起動しておこう。
その上で、以下のようなプログラムをJupyter Notebookに書き込んで実行してみよう。
import markdown
text = '''
# ウサギについて
全身が柔らかい体毛で覆われている小型獣である。
'''
md = markdown.Markdown() # ---(*1)
html = md.convert(text) # ---(*2)
print(html)
すると、以下のようなHTMLが生成されているのが確認できる。
<h1>ウサギについて</h1>
<p>全身が柔らかい体毛で覆われている小型獣である。</p>
プログラムを見てみると、(*1)の部分で、Markdownオブジェクトを作成し、(*2)の部分のように、convert()メソッドを呼ぶだけ。とても簡単であることが分かる。
HTMLからPDFを生成しよう
今回、PDFを生成するためには、pdfkitパッケージを利用するのだが、pdfkitは、内部で「wkhtmltopdf」というライブラリを利用する。そのため、別途「wkhtmltopdf」のインストールが必要となる。
Windowsであれば、こちら(https://wkhtmltopdf.org/downloads.html)からインストーラーをダウンロードできるので、wkhtmltopdfをインストールしよう。その後、wkhtmltopdfを環境変数のPathに追加する必要がある。なお、環境変数を編集するには、Windows10では、コントロールパネルから、[システムとセキュリティ>システムの詳細設定>システム>環境変数]をクリックする。
-
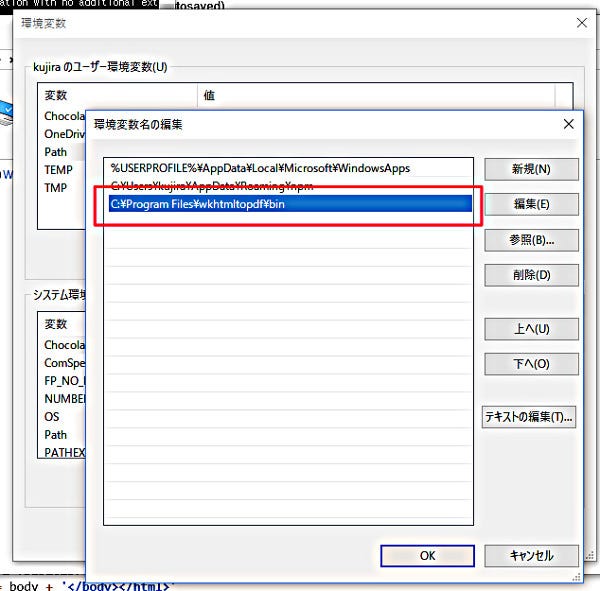
環境変数Pathにwkhtmltopdfのパスを追加

macOSであれば、Homebrewを使ってインストールできる。その場合、ターミナルを起動して「brew cask install Caskroom/cask/wkhtmltopdf」とコマンドを入力する。Homebrew自体のインストールは、こちら(https://brew.sh/index_ja.html)を参考にしよう。
wkhtmltopdfのインストールが完了したら、Jupyter Notebookで以下のコードを実行してみよう。
import markdown
import pdfkit
text = '''
# 今日やること
- 切手を買う
- xxの資料を作る
'''
# HTMLに変換
md = markdown.Markdown() # ---(*1)
body = md.convert(text) # ---(*2)
# HTML出力用のヘッダを足す # ---(*3)
html = '<html lang="ja"><meta charset="utf-8"><body>'
html += '<style> body { font-size: 8em; } </style>'
html += body + '</body></html>'
# PDF出力
pdfkit.from_string(html, "test.pdf") # --- (*4)
プログラムを実行すると、以下のようなPDFが出力される。
-
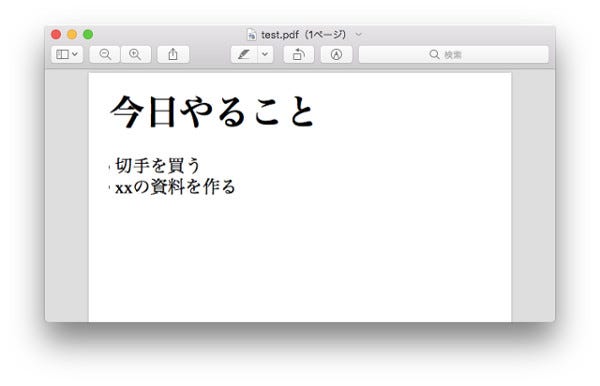
Markdownから生成したPDF

プログラムを確認してみよう。(*1)の部分では、Markdownオブジェクトを作成し、(*2)でテキストをHTMLに変換する。(*3)の部分では、HTMLに文字コードやフォントサイズの指定を追加し、(*4)の部分で、PDFを生成する。pdfkitパッケージとwkhtmltpdfを使うと、以下のように一行でPDFを生成できる。
[書式] PDFを生成する
pdfkit.from_string(入力HTML文字列, 出力PDFファイル名)
もし、用紙のマージンを設定したい場合には、以下のようにオプションを指定することもできる。
# オプションを指定
options = {
'page-size': 'A4',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8"
}
# PDFを生成
pdfkit.from_string(html, "test.pdf", options=options)
指定ディレクトリのファイルを全部PDFに変換しよう
続いて、指定ディレクトリにあるMarkdownで書かれたテキストファイルを全部PDFに変換するプログラムを作ってみよう。
import markdown
import pdfkit
import glob
path = "." # ここに変換対象ディレクトリを指定
files = glob.glob(path + "/*.md")
for f in files:
# Markdownのテキストを読む
with open(f, "rt", encoding="utf-8") as fp:
text = fp.read()
# HTMLに変換
md = markdown.Markdown()
body = md.convert(text)
html = '<html lang="ja"><meta charset="utf-8"><body>'
html += '<style> body { font-size: 3em; } </style>'
html += body + '</body></html>'
# PDFで出力
outfile = f + ".pdf"
pdfkit.from_string(html, outfile)
print("ok")
Pythonで『glob.glob("*.md")』のように書くと、拡張子が「.md」のファイル一覧を取得する。あとは、for文を使って繰り返しファイルを読み出し、Markdownのファイルを読み出して、PDFファイルを出力するという具合だ。
まとめ
以上、今回は、Markdown記法からPDFを生成するプログラムを紹介した。ここでは、直接PDFを出力するのではなく、Markdown→HTML→PDFと順に変換していく手順を踏んだ。
面倒にも感じるが、HTMLはCSSを利用して自由にデザインが変更できるので、都合が良い。ここで紹介したサンプルでは、文字の大きさ程度しかCSSを適用していないが、PDFを生成する前のHTMLに独自のCSSを加えるなら、見栄えをぐっと良くすることができる。
実は、今回のプログラムは、Markdownで書き貯めたマニュアルを一気にPDFに変換する必要があり作成したものだ。業務などで特定のフォーマットに沿って、PDFを出力する場面は多いので、今回のプログラムが参考になるだろう。










