



連載第2回の目的
前回は、TensorFlow.jsを活用するにあたり知っておきたい、機械学習の基礎とTensorFlowの基礎を説明し、そして、TensorFlow.jsを使った事例を2点紹介しました。本稿ではその実践として、まずはTensorFlow.jsの基本的な使い方を理解するためのハンズオンを行います。販売価格から売れ行きを予測する簡単なサンプルを通じて、ライブラリの読み込み方法、モデルの作成や訓練などの基本的な流れを理解します。
▼完成サンプル
https://github.com/wateryinhare62/mynavi_tensorflowjs/
ハンズオンのテーマは、「回帰分析」です。回帰分析とは、既知のデータから未知のデータを予測するために利用される統計的手法です。例えば、販売価格と売れ行きには一定の法則(価格が高いと売れ行きが悪くなる)が働くことが予想されます。このような場合に回帰分析を用いると、ある販売価格に対する売れ行きを予測できます。
今回の事例では、回帰分析の手法の一つである「線形単回帰分析」を行います。これは、入力が1つで、入力と出力が一次線形関係(方程式y = ax + bで表現できる)にあるものをいいます(図1)。難しいことはなく、中学数学で習う一次方程式で表せる関係、と理解しておけば十分です。この手法により、未知の販売価格から売れ行きを予測してみます。
[NOTE]変数
回帰分析では、入力は「独立変数」(説明変数)、出力は「従属変数」(目的変数)と呼ばれます。図1のように、独立変数をX、従属変数をYとすることが多いようです。
図1:線形単回帰分析

ハンズオンは、図2のステップで実施していきます。データの準備から予測(汎化)に至る第1回でも紹介したプロセスです。
-
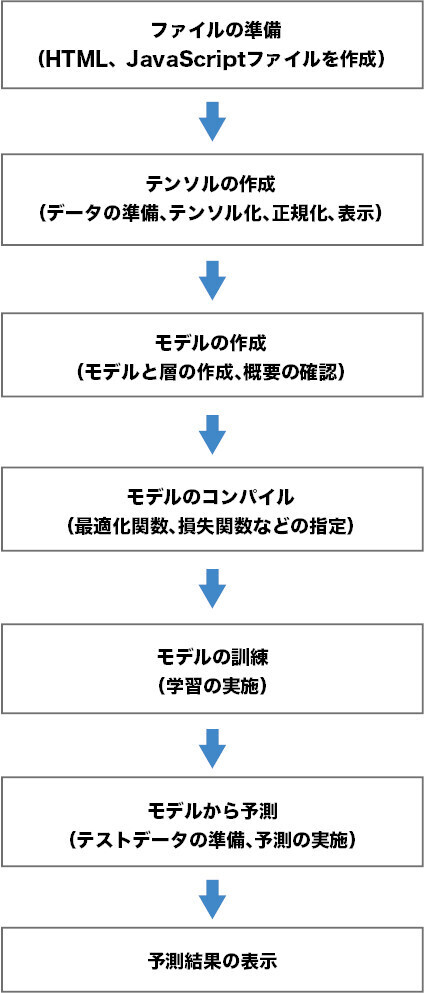
図2:ハンズオンのステップ

[NOTE]ハンズオンの環境
本連載のサンプルはHTMLファイルとJavaScriptファイルなどから構成されるシンプルなものです。そのため、適当なテキストエディタとブラウザがあれば作成、実行が可能ですが、できればVS Code(https://code.visualstudio.com/download)などのコードエディタの利用をおすすめします。VS Codeを利用する場合、拡張機能「Live Server」をインストールしておくと、ファイルを指定してのブラウザの起動や自動更新などの機能を利用できて便利です。
ファイルを準備する
まずは、サンプルの基点となるHTMLファイル(index.html)を作成しましょう(リスト1)。
リスト1:index.html
<!DOCTYPE html>
<html>
<head>
<title>TensorFlow.js:販売価格から売れ行きを予測する</title>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js"></script> (1)
<script src="script.js"></script> (2)
</head>
<body>
</body>
</html>
(1)では、TensorFlow.jsライブラリの読み込み方法を示しています。CDN(Content Delivery Network)から読み込んでいますが、公式GitHub(https://github.com/tensorflow/tfjs)で案内されているように、Node.jsモジュールとしても利用可能です。本連載では簡便さを考慮して、CDNから直接読み込んで利用します。
なお、この読み込みによって、グローバル変数tfが利用できるようになります。この変数は、TensorFlow.jsライブラリを使うための変数で、以降頻繁に利用するので覚えておきましょう。
(2)は、本サンプル用のJavaScriptファイルの読み込みです。TensorFlow.jsを使うコードは、このファイルに記述していきます。ファイルの中身は、ひとまずリスト2のようにしておきます。これは、コンソールに開始メッセージを表示するだけの内容です。
リスト2:script.js(初期状態)
console.log('こんにちは、TensorFlow.js!');
HTMLファイルをブラウザで読み込みます。ページには何も表示されませんが、ページを右クリック→[検証]をクリックしてデベロッパーツールを開き(Google Chromeの場合)、「コンソール」タブにJavaScriptコードから書き出したメッセージが表示されていれば、ここまでの手順はうまくいっています(図2)。
-
図2:初期表示

以降も、表示はコンソールに対して行っていきますので、デベロッパーツールは開いたままにしてください。
テンソルを作成する
ここからは、script.jsにコードをどんどん追加していきます。まずは、訓練に必要なデータをテンソル(第1回を参照、この例では1次元のテンソル、つまり配列)という形式で準備します。回帰分析においては、入力となるデータ(「特徴量」と呼ばれます)と出力となるデータ(「ラベル」と呼ばれます)からモデルを訓練するので、それぞれテンソルとして作成します(リスト3)。なお、特徴量(販売価格)とラベル(売れ行き)には、おおよそ「売れ行き = -販売価格 + 1000」となる一次相関関係があるとして架空のものを作成しています。価格が上がるほど売れ行きが下がるという大まかな関係を押さえてください。
リスト3:script.js(テンソルの作成)
// おおよそ「売れ行き = -販売価格 + 1000」となる配列を用意する
const inputsArray = [100, 200, 300, 400, 500]; (1)
const labelsArray = [920, 780, 720, 580, 500];
// 正規化のために最大値を求める
const maxInputs = tf.scalar(Math.max(...inputsArray)); (2)
const maxLabels = tf.scalar(Math.max(...labelsArray));
// テンソル化して正規化を実行する
const inputs = tf.tensor1d(inputsArray).div(maxInputs); (3)
const labels = tf.tensor1d(labelsArray).div(maxLabels);
inputs.print(); (4)
labels.print();
ここで使うTensorFlow.jsのメソッドは、以下の通りです。
・tensor1dメソッド:1階テンソルを配列から作成する(他には2階テンソルを作るtensor2dなどがある)
・scalarメソッド:1要素のみの1階テンソルを単一のスカラー(数値)から作成する
・divメソッド:テンソルの要素ごとの商からなるテンソルを作成する(他にはadd、sub、mulなどのメソッドがある)
・printメソッド:テンソルの値をコンソールに表示する
これらのメソッドを使い、(1)特徴量とラベルの1次元配列を用意する、(2)正規化(NOTE参照)のための最大値からなる1階テンソルを作る、(3)配列をテンソル化して正規化する、(4)得られたテンソルを確認用に表示する、の流れでコードを記述します。
図3のように、特徴量とラベルのそれぞれについて、正規化された1階テンソルが作成されたのを確認できれば、ここまでの手順はうまくいっています。
-
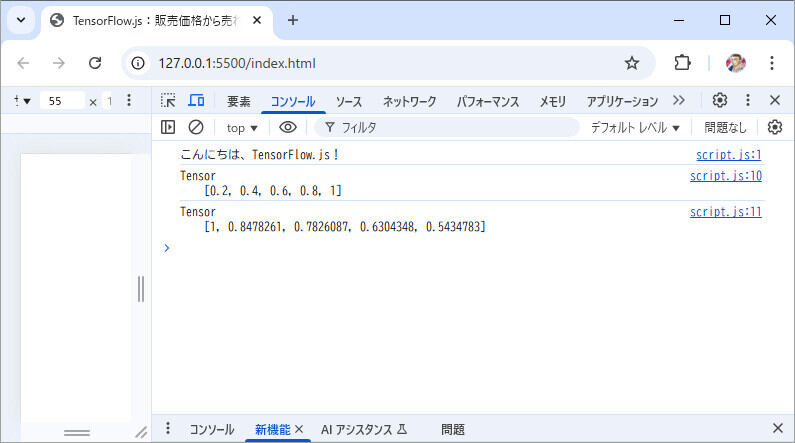
図3:テンソルの作成

[NOTE]正規化
ここで登場する「正規化」とは、テンソル内のデータの分布を0~1か-1~1の範囲に収まるように調整することです。訓練において扱う数値は、とても小さい場合もあれば大きい場合もあり、ケースによってまちまちです。そこで安定した成果を出すために、正規化によって入力範囲を一定にすることが推奨されているのです。正規化の方法には幾つかありますが、ここでは「入力÷最大値」による正規化を行っています。最小値も使う、「(入力-最小値)÷(最大値-最小値)」による正規化もあり、こちらはゼロから離れた入力がほとんどである場合に有効です。
モデルを作成する
テンソルを準備できたら、機械学習の核となるモデルを作成します(リスト4)。
リスト4:script.js(モデルの作成)
const model = tf.sequential(); (1)
model.add(tf.layers.dense({ (2)
units: 1,
inputShape: [1],
}));
console.log(model.summary()); (3)
ここで使うTensorFlow.jsのメソッドは、以下の通りです。
・sequentialメソッド:Sequentialモデルを作成する
・denseメソッド:Dense層を作成する
・addメソッド:層をモデルに追加する
・summaryメソッド:モデルの概要をテキストで返す
これらのメソッドを使い、(1)モデルを作成する、(2)層を作成しモデルへ追加する、(3)モデルの概要を確認用にテキストで表示する、という流れでコードを記述します。
作成できるモデルには、以下の3種類があります。
・Sequential:入出力がともに1個で層が一直線につながるモデル
・Functional:複数の入出力を持ちフローが複雑となるモデル
・Subclassing:独自に構築できるモデル
今回採用したのは、このうち「Sequential」というシンプルで最も基本となるモデルです。入力が1つで出力を1つ得る単回帰分析では、Sequentialが最適であるためです。Functional、Subclassingは、単回帰に収まらない複雑な問題を解決したい場合に使われます。
モデルには処理層が最低1個は必要なので、Dense層と呼ばれる基本的な層を追加しています。Dense層は、数ある層の種類の中でも核となるCore層のうち「全結合層」と呼ばれる、全ての入力を次の層に出力する基本的な層です。その性質から、回帰分析に適しています。Dense層では、「重み」「バイアス」「活性化関数」など多くのパラメータを使って計算するため、複雑なパターンの学習に対応します。
denseメソッドの、ここで使われている引数の意味は表1の通りで、これによって構築されたモデルのイメージは図4のようになります。
表1:denseメソッドの主な引数
| 引数 | 概要 |
|---|---|
| units | 層のユニット数。層の出力の数に相当する。ここでは1となる |
| inputShape | 入力層にのみ必要。入力データの形状を指定する。ここでは[1]すなわち1要素の1階テンソルとなる |
-
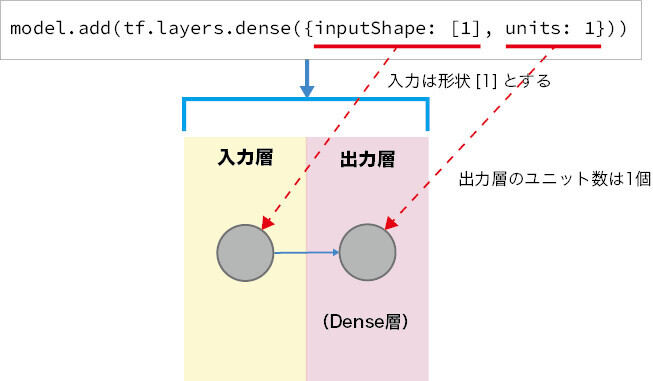
図4:作成するモデル

得られるモデルの概要が図5のように表示されれば、ここまでの手順はうまくいっています。
-
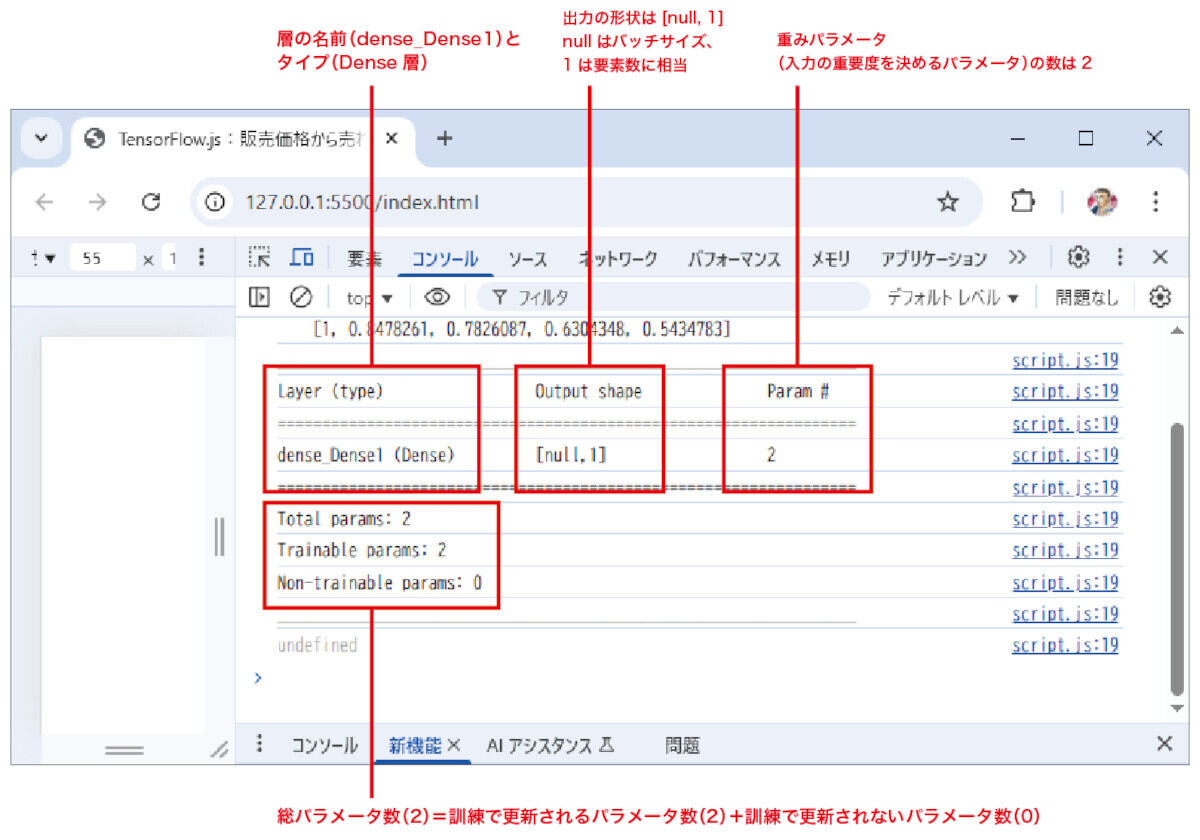
図5:作成したモデルの概要

モデルをコンパイルする
データとモデルが準備できればさっそく訓練といきたいのですが、その前に「コンパイル」という作業が必要となります(リスト5)。
リスト5:script.js(モデルのコンパイル)
model.compile({
optimizer: 'sgd',
loss: 'meanSquaredError',
});
ここで使うTensorFlow.jsのメソッドは、以下の通りです。
・compileメソッド:オプティマイザ、損失関数、評価関数などを受け取り、モデルをコンパイルする
このメソッドを使い、モデルをコンパイルします。「コンパイル」とは、モデルが訓練に使用する関数をあらかじめ設定しておくことです。表2は、ここで指定されているcompileメソッドの最重要な引数です(今回は使いませんが、評価関数を指定するmetrics引数もあります)。
表2:compileメソッドの最重要な引数
| 引数 | 意味 | 概要 |
|---|---|---|
| optimizer | オプティマイザ 損失関数を最小化する最適化関数を選択。 | 10種類以上のオプティマイザから、ここでは最も基本的なsgd(確率的勾配降下法)というアルゴリズムを選択 |
| loss | 損失関数 正解と予測値の差(損失)を求めるための関数。 | 単回帰分析で使われるmeanSquaredErrorすなわち平均二乗誤差を選択 |
訓練の成果は、一般的にコンパイルに指定する関数によって影響を受けます。期待する予測結果がうまく得られないという場合には、オプティマイザとそれに与える学習率(1学習あたりのパラメータの変化度合を指定する数値)を変更して調整するとうまくいく場合があります。本記事では、最も基本となるSGDを、既定の学習率で使用する指定としています。
モデルを訓練する
コンパイルが済んだら、訓練を実行できます(リスト6)。
リスト6:script.js(モデルの訓練)
async function trainModel() { (1)
await model.fit(inputs, labels, { (2)
batchSize: 5,
epochs: 2000,
});
console.log('訓練終了!');
}
console.log('訓練開始...');
trainModel(); (3)
ここで使うTensorFlow.jsのメソッドは、以下の通りです。
・fitメソッド:モデルを訓練する。与えられた特徴量に対して、結果がラベルに一致するようになるまで関係を調整する
このメソッドを使い、(1)訓練を実行する非同期関数trainModelを定義する、(2)trainModel関数内で訓練を非同期で実行する、(3)trainModel関数を呼び出す、という流れでコードを記述します。
わざわざ非同期関数を定義するのは、fitメソッドを非同期で呼び出す必要があるためです。fitメソッドは訓練の主体ともいえるものなので、データ量に応じて実行には時間を要します。そのため、非同期関数として全体の処理をブロックしないようにするのです。このように、TensorFlow.jsのメソッドは非同期であるものもいくつかあるので、その場合は同様に非同期関数を作成して、その内部から呼び出す必要があります。
fitメソッドは、訓練のための特徴量とラベル、そして訓練の詳細を指定するオプションを与えて呼び出します。オプションは多数ありますが、重要なのは、バッチサイズ(batchSize)とエポック数(epochs)です(表3)。
表3:fitメソッドの主なオプション
| オプション | 意味 |
|---|---|
| batchSize | バッチサイズ。大量のデータは分割して訓練するのが望ましいので、その際に使う分割後のデータ数。既定値は32で、2のべき乗であることが推奨される |
| epochs | 学習回数。期待する予測結果が得られる適切な回数にする必要がある |
今回のサンプルでは、下記NOTEの試行の結果として、batchSizeとepochsをそれぞれ入力データ数である5と2000回と設定しています。
[NOTE]バッチサイズとエポック数
バッチサイズについては、「バッチサイズの既定値>データ数」なので既定値のままでよいかと思われましたが、データ数ちょうどとした方が予測の精度が上がるようでした。 エポック数は、学習不足(文字通り学習が足りずに改良の余地を残すこと)と過学習(学習のしすぎで一般的でないパターンも学習してしまうこと)とならないような最適な値にする必要があります。10,100、1000、2000、3000といった大まかな数値で試行錯誤した結果として、2000を選択しています。


モデルから予測してみる
いよいよ、予測を実施しましょう。期待する成果が得られるでしょうか? 予測を実施するコードは、trainModel関数に追記します(リスト7)。
リスト7:script.js(モデルからの予測)
async function trainModel () {
…略…
console.log('訓練終了!')
// 予測の実施
const testInput = tf.tensor1d([600]).div(maxInputs) (1)
const prediction = model.predict(testInput) (2)
prediction.mul(maxLabels).print() (3)
}
ここで使うTensorFlow.jsのメソッドは、以下の通りです。
・predictメソッド:入力のテンソルを受け取って予測を実行する
・mulメソッド:テンソルの要素ごとの積からなるテンソルを作成する
このメソッドを使い、(1)既出のdivメソッドにより正規化した入力を作成する、(2)予測を実行する、(3)非正規化して結果を表示する、というコードを記述します。
(1)で指定する600は、冒頭で用意した100~500のデータのいずれにも該当しない未知のデータです。このデータに対して期待する結果(400)が得られるかを検証します。図6のように、結果がテンソルで表示されれば、ここまでの手順はうまくいっています。
-
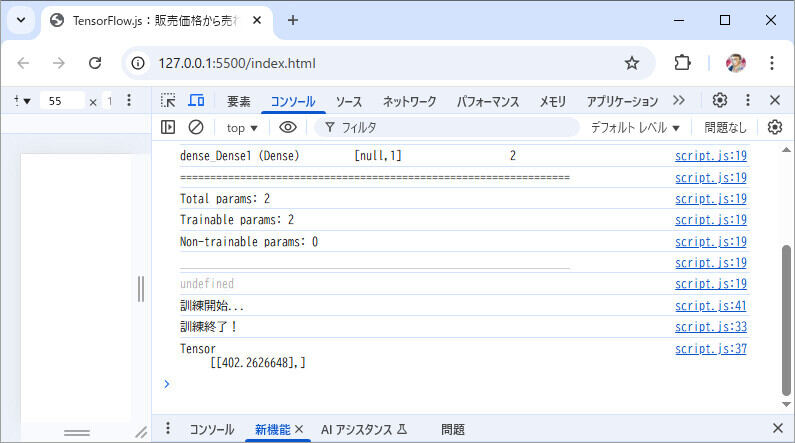
図6:script.js(モデルからの予測)

ここでは、「402」という結果が得られました。何回か実行すると、「421」「385」などという結果がばらつきがありながらも得られます。期待する400に、おおよそ近い結果が得られたのではないかと思います。結果は、オプティマイザやその学習率、バッチサイズ、エポック数でも変化します。ブラウザ内で処理が完結するメリットを生かして、いろいろ変えて試しましょう。
まとめ
今回は、販売価格から売り上げを予測するサンプルを通じて、TensorFlow.jsライブラリの読み込み方法、モデルの作成や訓練の実施などの基本的な流れを解説しました。次回は、この応用編として、外部にある大量のデータを使った事例を、可視化ライブラリの利用法とともに紹介します。
WINGSプロジェクト 山内直(著) 山田 祥寛(監修)
有限会社 WINGSプロジェクトが運営する、テクニカル執筆コミュニティ(代表山田祥寛)。主にWeb開発分野の書籍/記事執筆、翻訳、講演等を幅広く手がける。現在も執筆メンバーを募集中。興味のある方は、どしどし応募頂きたい。著書、記事多数。
RSS
X:@WingsPro_info(公式)、@WingsPro_info/wings(メンバーリスト)<著者について>
WINGSプロジェクト所属のテクニカルライター。出版社を経てフリーランスとして独立。ライター、エディター、デベロッパー、講師業に従事。屋号は「たまデジ。」。









